登录社区云,与社区用户共同成长
邀请您加入社区
在多线程环境下实现单例模式,需要审慎权衡懒加载、性能、复杂性和安全性。对于大多数现代Java应用,推荐优先选择枚举方式或静态内部类方式。枚举方式提供了最高级别的安全性和简洁性,是防御反射和序列化攻击的理想选择。静态内部类方式则完美实现了懒加载,且无需任何同步代码,代码清晰易懂。如果因为某些原因(如需要继承一个非枚举的类)无法使用枚举,并且非常关注懒加载的效率,那么双重检查锁定(DCL)配合`vol
因此,在按值返回局部对象时,直接返回即可,不需要使用`std::move`,否则可能反而会抑制编译器的优化机会。例如,对于一个管理动态数组的类,移动构造函数会拷贝源对象的指针到新对象,然后将源对象的指针置为`nullptr`。这种所有权的转移避免了不必要的拷贝,将资源(如动态内存的指针)从源对象高效地移动到目标对象,同时将源对象置于一个有效但可安全析构的状态(通常为空状态)。一个具备异常安全性的实
A: WSAAsyncSelect 本质仍是消息泵,建议把业务线程拆出,UI 只负责 PostMessage 刷新。若客户端规模 >500,可将 WSAAsyncSelect 替换为完成端口,保留现有消息层接口,UI 线程零改动。客户端关闭窗口→closesocket→服务器 FD_CLOSE→从链表删除→在线人数-1→UI 实时刷新。1、C++SOCKET同步阻塞、异步非阻塞通信服务端、客户端代
本项目将 Kaggle 电商数据集上传至 HDFS,借助 Hive 映射生成数据表。依托 SparkCore 与 SparkSQL 完成离线数据处理,结合 SparkML 搭建分析模型:通过 KMeans 完成用户分群,逻辑回归预测用户复购倾向,线性回归预估七日 GMV。采用 SparkStreaming 对接 Kafka 实现实时流数据计算,离线与实时共 21 项指标存入 MySQL。后端 Sp
小米扫地机器人固件展现了典型的嵌入式实时系统设计范式:以 FreeRTOS 为调度核心,构建模块化、层次化的软件架构;通过严谨的异常检测与安全控制策略保障设备物理安全;利用高效的 IAP 机制支持远程升级;并设计轻量可靠的通信协议实现内外部数据交互。整个系统在性能、资源占用与功能完整性之间取得了良好平衡,为其稳定、智能的清扫体验提供了坚实的软件基础。
SparkML机器学习
易于使用:提供了丰富的 API,支持 Scala、Java、Python 和 R 等多种编程语言。高度可扩展:可以处理海量数据,适用于大规模机器学习任务。丰富的算法库:支持分类、回归、聚类、降维、协同过滤等常用算法。本文详细介绍了 Spark MLlib 的功能及其应用,结合实例演示了分类、回归、聚类、降维、协同过滤等常用机器学习任务的实现过程。通过这些实例,我们可以看到 Spark MLlib
VectorIndexer主要作用:提高决策树或随机森林等ML方法的分类效果。VectorIndexer是对数据集特征向量中的类别(离散值)特征(index categorical features categorical features )进行编号。它能够自动判断那些特征是离散值型的特征,并对他们进行编号,具体做法是通过设置一个maxCategories,特征向量中某一个特征不
成功实施微服务架构需要遵循一系列关键的设计模式。随着云原生技术和.NET平台的持续演进(如.NET Aspire等新框架的推出),.NET开发者将能够更加高效地设计、开发和运维高可用、可扩展的微服务应用,从容应对数字化时代对软件系统提出的更高要求。同时,.NET通过丰富的诊断和日志记录库(如Serilog、Application Insights、OpenTelemetry)为系统的可观测性(Ob
== 完整预处理Pipeline ===
随机森林回归作为一种强大的集成学习方法,在回归任务中表现出色。通过结合多个决策树的预测结果,随机森林不仅提升了模型的预测精度,还在一定程度上减轻了单棵决策树易于过拟合的缺陷。在 Spark 中,随机森林回归被广泛应用于各种大规模数据分析任务,凭借其强大的并行处理能力和灵活的参数调优方法,成为了数据科学家和工程师的常用工具。通过合理的参数调整和特征选择,随机森林回归能够在许多实际场景中提供准确且稳健
理解这些机器学习模型的数学原理需要一定的数学基础,下面我将简要介绍每个模型的数学原理,并附上相关的数学公式。
利用AUC评分最高的参数,给用户推荐艺术家对多个用户进行艺术家推荐利用AUC评分最高的参数,给艺术家推荐喜欢他的用户。
数据格式:userId,movieId,rating,timestamp。数据格式:userId, [(movieId, rating)]说明:当前文章或代码如侵犯了您的权益,请私信作者删除!数据格式:movieId,title,genres。movieId:电影ID。userId:用户ID。rating:推荐度。
Fincept Terminal v4 全面测评:一个想颠覆金融数据终端市场的野心项目,真实体验比官方宣传更复杂
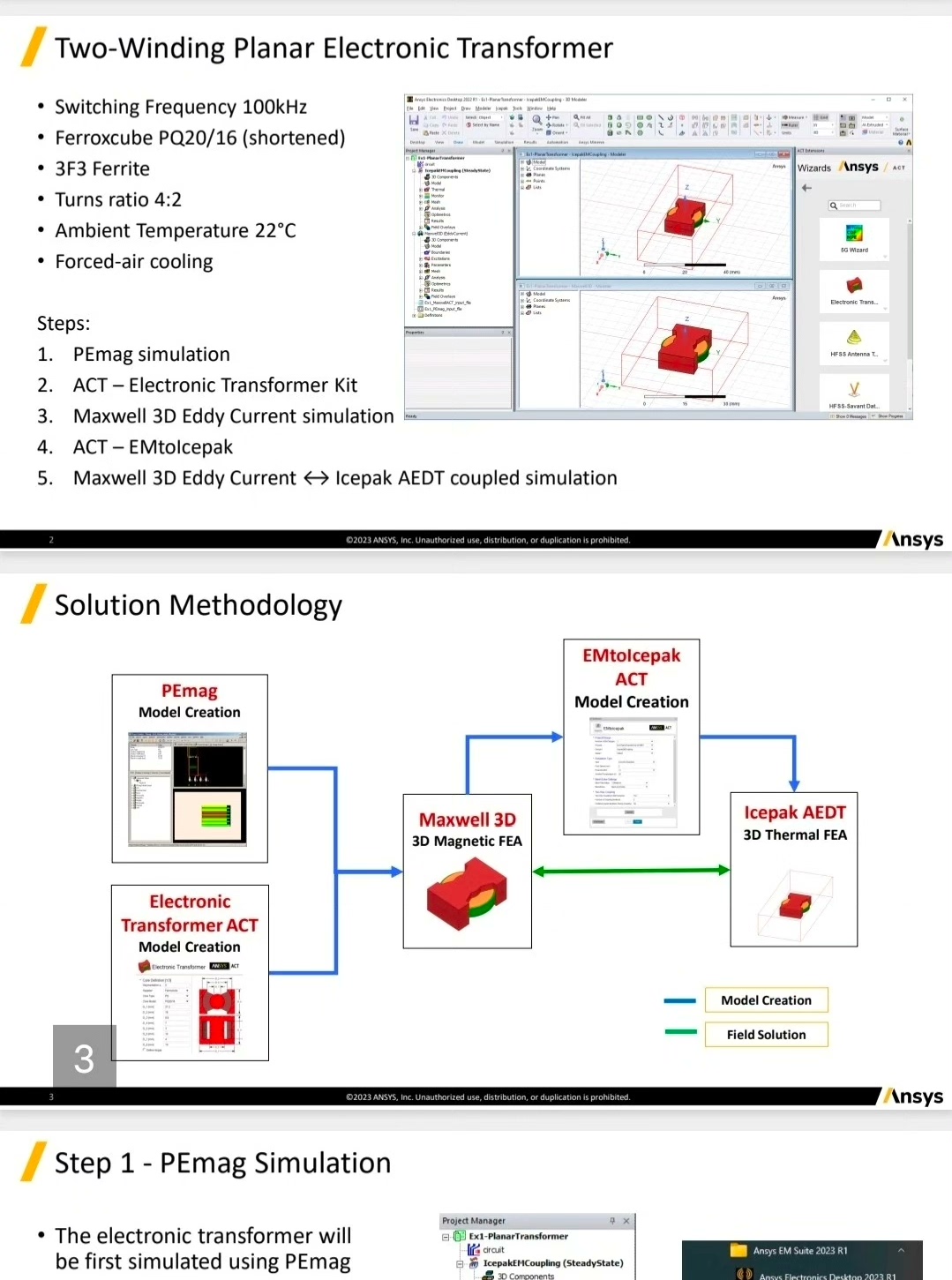
本Maxwell与Simplorer联合仿真代码通过模块化、参数化设计,构建了一套完整的移相全桥变换器开关变压器仿真系统。代码实现了磁芯建模、拓扑搭建、联合仿真、闭环控制的全流程自动化,核心优势在于高精度的电磁特性计算、灵活的参数配置能力以及贴近工程实际的闭环控制功能。用户可基于此代码快速开展变压器设计验证,通过修改参数、扩展模块适配不同应用场景,显著提升电力电子变换器的研发效率与设计可靠性。An
通过这次仿真设计,我对Buck电源的控制环设计有了更深刻的理解。尤其是借助MATLAB/Simulink工具,大大提高了设计效率。当然,这只是一个起点,未来还打算尝试更高阶的设计,比如引入状态观测器,或者研究更复杂的控制策略。Buck电源仿真设计,基于MATLAB/Simulink建模仿真。使用Control System Tool的sisotool模块,对Buck电路的控制环参数进行设计,可以一
本文基于“DSP 平台 SMO”开源工程,对一套“全速域、全开源、全 C 代码”滑模观测器(Sliding-Mode Observer, SMO)方案做深度剖析,帮助开发者快速吃透其设计思想与工程落地细节。无感Foc电机控制,算法采用滑膜观测器,启动采用Vf,全开源c代码,全开源,启动顺滑,很有参考价值。无感Foc电机控制,算法采用滑膜观测器,启动采用Vf,全开源c代码,全开源,启动顺滑,很有参考
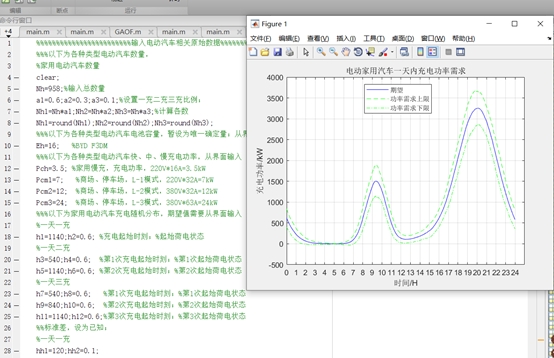
然后,根据不同的充电模式和参数,计算出每辆电动汽车的充电功率,并将其加到`Ph`数组中相应的位置。最后,代码使用`mean`函数和`std`函数分别计算出`Bh`矩阵每列的平均值和标准差,然后根据平均值和标准差计算出充电功率的上限和下限,并将这些数据绘制成图表。最后,代码使用`mean`函数和`std`函数分别计算出`Bh`矩阵每列的平均值和标准差,然后根据平均值和标准差计算出充电功率的上限和下限
模型里的驾驶员模块预置了三种性格:"激进型"会触发连降两挡的操作,"经济型"的油门开度永远不超过65%,而"菜鸟型"的踏板行程曲线会出现神经质般的抖动。——仿真结果:发动机工作扭矩,电机工作扭矩,电池SOC变化,电池能量变化,电池电流变化,车速跟随变化,燃油消耗变化,累计行驶距离结果,整车工作模式变化等等结果全部都有。——仿真结果:发动机工作扭矩,电机工作扭矩,电池SOC变化,电池能量变化,电池电
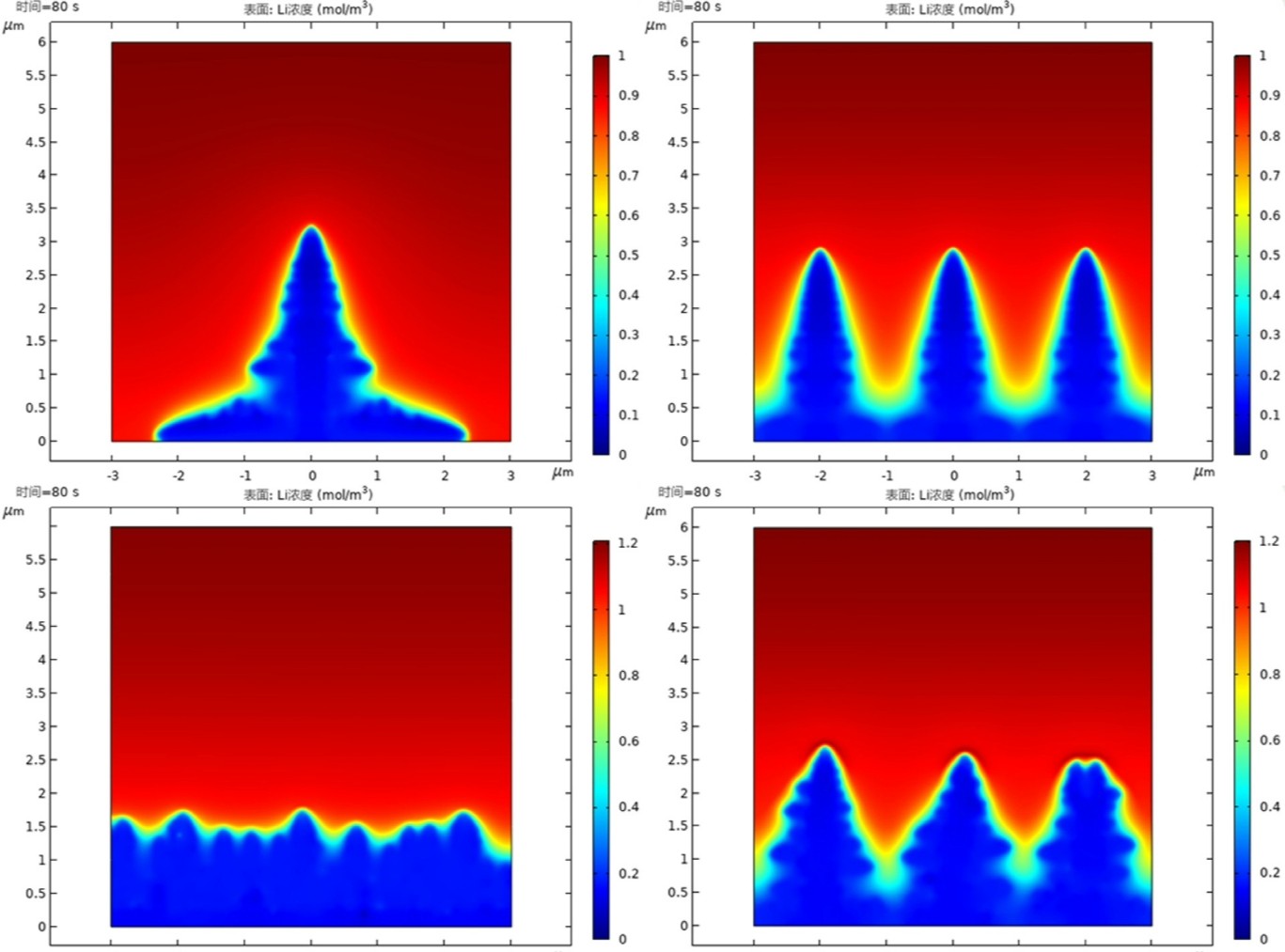
comsol 锂枝晶模型 五合一单枝晶定向生长、多枝晶定向生长、多枝晶 随机生长只无序生长随机形核以及雪花枝晶,包含相场、浓度场和电场三种物理场在锂电领域,锂枝晶的生长一直是研究的重点,因为它严重影响电池的安全性与性能。今天咱就来唠唠 Comsol 里超酷炫的锂枝晶模型 “五合一”,它涵盖了单枝晶定向生长、多枝晶定向生长、多枝晶随机生长、无序生长随机形核以及雪花枝晶这几种生长模式,并且综合了相场、
现在,我需要将这三个部分结合起来,形成一个自定义的PDE。这个PDE需要同时考虑应力、流体流动和温度变化。注co2驱替煤层气THM耦合模型自定义pde耦合固体力学% 耦合的PDE系统这个系统方程组看起来有点复杂,但其实每一部分都有其物理意义。需要注意的是,这个系统是非线性的,求解起来可能会遇到一些困难。
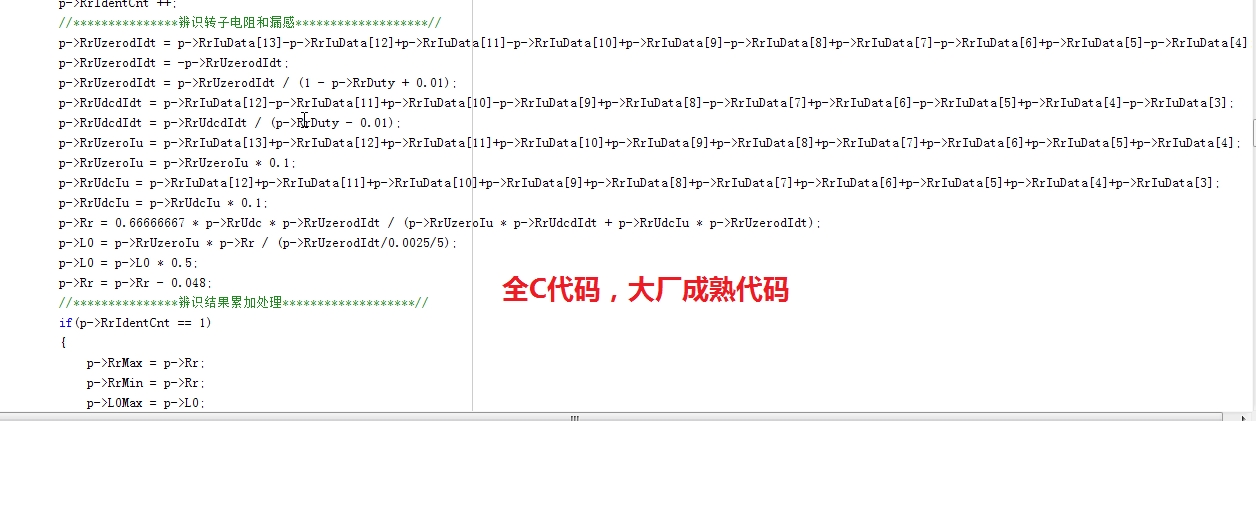
该算法已在 50 kW 以下变频器批量应用,兼容 TI C2000、STM32、GD32 等平台,可直接移植,无需额外硬件成本,为高性能矢量控制奠定可靠基础。本文基于一份已在 TI TMS320F28335 上量产落地的 C 工程,对「定子电阻 → 转子电阻 & 漏感 → 互感 & 空载电流」三步辨识法进行端到端解读,给出可落地的状态机、算法公式、代码流程与调试技巧。当电流>额定值置位 RrIuF
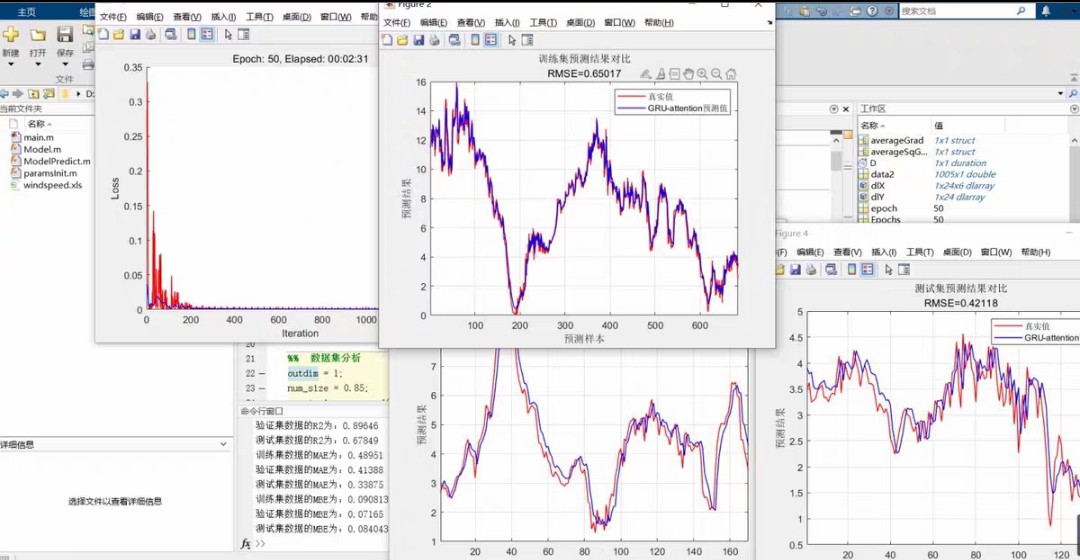
我们在某电力负荷数据集上做过对比实验,Attention-GRU的预测速度比LSTM快30%,精度还高出2个百分点——门控机制确实更适合捕捉时间序列的长期依赖。这段代码实现了时间序列的窗口切片。举个例子,lag=10表示模型会看前10天的数据来预测第11天。这种程度的拟合在时序预测中算是把GRU的潜力榨干了——当然,还得归功于注意力机制这个外挂。2、评价指标包括:R2、MAE、MSE、RMSE等,
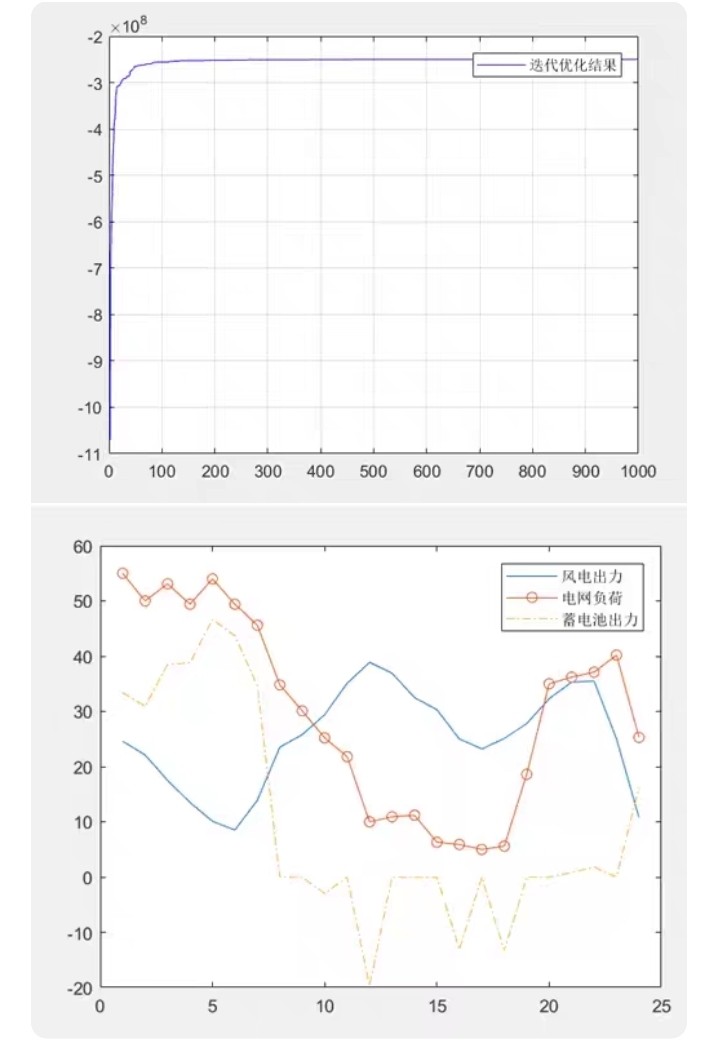
MATLAB代码:基于遗传算法的风电混合储能容量优化配置关键词:混合储能 容量配置优化遗传算法参考文档:《基于遗传算法的风电混合储能容量优化配置》无超级电容器!;仿真平台:MATLAB主要内容:为了降低独立风力发电系统中储能装置的生命周期费用,建立以风力发电系统中储能装置的生命周期费用最小值为优化的目标函数、负荷缺电率等指标为约束条件的模型,结合蓄电池储能特性,利用风电和负荷24h的发用电数据,研
摘要:本文介绍了一个基于Kafka+Hadoop+SparkML的电影推荐与用户画像系统项目。系统采用大数据技术架构,整合离线/实时推荐算法(ALS协同过滤+内容推荐)和多维度用户画像分析(兴趣标签+行为聚类)。项目包含数据采集、预处理、模型训练等完整实施流程,提供个性化推荐(响应时间≤1秒)和动态用户画像更新功能。交付成果包括系统源码、技术文档和可视化Demo,适用于毕业设计或实际应用场景开发。
通过这个模型可以对输入对象的特征向量预测或对对象的类标进行分类。2、从通信的角度讲,如果使用 Hadoop 的 MapReduce 计算框架,由于是通过heartbeat 的方式来进行的通信和传递数据,会导致非常慢的执行速度,而 Spark 具有出色而高效的 Akka 和 Netty 通信系统,通信效率极高。线性回归是利用称为线性回归方程的函数对一个或多个自变量和因变量之间关系进行建模的一种回归分
1.背景介绍Spark MLlib 是 Apache Spark 生态系统中的一个重要组件,它提供了大规模机器学习的算法和工具。Spark MLlib 可以处理大规模数据集,并提供了许多常用的机器学习算法,如梯度下降、随机梯度下降、支持向量机、决策树等。此外,Spark MLlib 还提供了数据预处理、模型评估和模型优化等功能。在本文中,我们将深入探讨 Spark MLlib 的核心概念、...
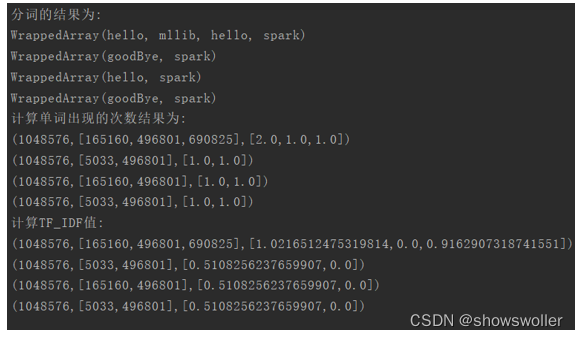
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
Spark MLlib 是 Spark 的机器学习 (ML) 库。它的目标是使实用的机器学习变得可扩展且易于使用。
大模型微调技术是一种在机器学习和人工智能领域中使用的技术,它允许开发者利用已经训练好的大型预训练模型(通常称为基础模型或基线模型),并对其进行调整以适应特定的任务或领域。这种技术可以显著减少从头开始训练一个模型所需的时间和资源,同时还能保持或提高模型的性能。
如果您觉得本博客的内容对您有所帮助或启发,请关注我的博客,以便第一时间获取最新技术文章和教程。同时,也欢迎您在评论区留言,分享想法和建议。谢谢支持!一、引言1.1 Spark MLlib简介Apache Spark MLlib(Machine Learning library)是一个开源机器学习框架,建立在Apache...
1.背景介绍自然语言处理(NLP)是一门研究如何让计算机理解和生成人类语言的科学。在过去的几年里,自然语言处理技术已经取得了显著的进展,这主要是由于深度学习和大数据技术的发展。Spark MLlib是一个用于大规模机器学习的开源库,它为自然语言处理任务提供了一系列有用的工具。在本文中,我们将讨论如何使用Spark MLlib进行自然语言处理任务。我们将从背景介绍、核心概念与联系、核心算法原...
预训练权重下载官方仓库:访问 GitHub 项目权重下载运行以下命令自动下载指定模型(以base支持模型包括:tinybasesmallmediumlarge(根据需求选择,越大精度越高但计算资源消耗越大)。手动下载。
在AI框架集成方面,研究显示充分优化的C++接口可在TensorFlow Serving等环境实现对比Python接口17-29倍的吞吐量提升。本文通过经典Dijkstra最短路径算法的优化实践,系统性探讨C++在数据结构设计、内存管理及编译器优化层面的多维突破路径。| 内存优化权重| 30%| 70%| 90%|标准实现的时间复杂度为`O((V+E)logV)`,其中瓶颈出现在基于堆的优先队列操
spark-ml
——spark-ml
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区


 快递鸟社区
快递鸟社区
 DAMO开发者矩阵
DAMO开发者矩阵




 腾讯云开发者社区
腾讯云开发者社区





 AtomGit开源社区
AtomGit开源社区



 魔乐社区
魔乐社区







 智能体开发者社区
智能体开发者社区
 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区
