




- @longxiaotian718
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
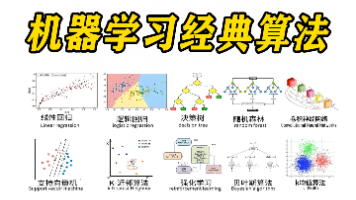
Spark MLlib 是 Spark 的机器学习 (ML) 库。它的目标是使实用的机器学习变得可扩展且易于使用。

AI Agent技术栈梳理模型服务存储工具与库智能体框架智能体托管与服务在人工智能领域持续演进的当下,AI 智能体技术栈正逐渐崭露头角。智能体软件生态系统在内存管理、工具使用、安全执行和部署等方面都取得了显著进展。

人工智能领域,"prompt"指的是向模型输入的文字提示或指令,用于引导模型生成对应的回复或完成特定的任务。它可以是一个问题、一句话、一段文字,甚至是一系列的指令。Prompt的内容和形式根据具体情境和需求而定,它决定了模型生成回复的方向和内容。在使用GPT-3.5及类似的自然语言处理模型时,用户通过编写简短的prompt来描述输入和预期输出的格式,然后将其传递给模型以获取响应。prompt的设计

构建和训练机器学习模型中,需要经常对数据进行分类,划分训练集和测试集,在这些日常工作中,我们必须使用脚本对数据进行处理,无论是分类、回归还是聚类,这些脚本都能让你效率大增,这些脚本有哪些呢?
大模型的参数主要包括输入层参数、隐藏层参数、输出层参数、激活函数参数、损失函数参数、优化器参数和正则化参数等。这些参数在神经网络模型中起到关键作用,例如权重和偏置,它们决定了模型的复杂度和学习能力。

智能体在千行百业中有着广泛的应用,目前已经在 600 多个项目落地和探索,广泛应用于政府与公共事业、交通、工业、能源、金融、医疗、科研等行业。智能体是模拟人类智能的计算机系统,能自主感知环境、智能决策并行动。例如,实在 Agent 智能体就是典型的智能体应用之一,它可以实现人机互动,通过语音唤醒进行启动或者控制,如打开网页,下载文件,订个餐厅,甚至是一个完整的工作流程。

最近看到抖音热搜的DeepSeek AI只能很火,很多小伙伴都想部署,但感觉上条件不是很满足,不知道怎样才能搞定它。今天就来告诉大家怎么在自己的Windows电脑上部署DeepSeek AI人工智能教程!(本教程仅适用于Windows10或以上版本的系统哦!使用的是测试机i5- 6600T RAM8GB+ROM120GB的配置,其中的i5-6600T是一半的性能(因为是建立在虚拟机上的,所以性能只

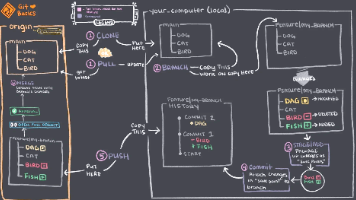
本篇文章我们介绍了git pull的用法,明白了它有merge和rebase两种模式。默认情况下,它使用的是merge。使用merge的方式拉取代码会导致git历史变得复杂,不利于维护和溯源。因此,建议使用rebase的方式拉取代码。我们只需要做如下设置即可设置完成后,你就可以放心的使用git pull了,不用在被git老手或者版本管理员给diss咱们git命令不精通了^_^, 下面这张图大家可以
Spark MLlib 是 Spark 的机器学习 (ML) 库。它的目标是使实用的机器学习变得可扩展且易于使用。
一个大规模的对话层级自动幻觉评估基准,旨在评估大语言模型在对话中识别幻觉的能力及其产 生幻觉的倾向。该数据集包含186089个问题-答案对,这些问答对 是从7680对电影情节中创建的,每对情节来自于同一部电影的两个版本(从一个版本的情节中创建问 题,并从另一个版本中提取或合成答案)。APPS包含从不同开放访问编码网站 (如Codeforces、Kattis等)收集的10,000个平均问题长度为29
