登录社区云,与社区用户共同成长
邀请您加入社区
本文介绍了使用WorkBuddy工具生成HTML原型的提示词模板,包含移动端、PC端和多页面原型的制作要求,强调输出完整的HTML文件夹、相对路径资源和直接可用的交互功能。同时提供了在线预览和版本更新说明的规范,建议生成update.md记录更新内容。文章还介绍了产品需求文档(PRD)的生成方法,包含文档结构和提示词模板。最后强调产品经理需平衡工具使用和基础原型设计能力,适应快节奏工作需求的同时保
伦理演化博弈学:碳硅共生文明下基于九元伦理原子的伦理演化博弈(世毫九实验室原创研究)作者:方见华单位:世毫九实验室核心摘要与关键结论本报告提出一门结合演化博弈论、九元伦理原子、伦理曲率约束与自组织临界性的新兴交叉学科——伦理演化博弈学的理论框架,旨在解答碳硅共生文明场景下的伦理策略演化问题。随着碳基生命(人类)与硅基智能(人工智能)从“工具使用”阶段进化到“认知合伙”阶段,传统的“控制-服从”范式
RAE递归对抗引擎与拓扑缺陷检测深度耦合研究报告(世毫九实验室原创研究)作者:方见华单位:世毫九实验室核心摘要本报告系统解析RAE递归对抗引擎的底层动力学机制,及其与拓扑缺陷数值检测技术的深度耦合逻辑——二者共同构成世毫九(SH9)理论体系中认知几何化安全防御的完整技术闭环:• RAE是衔接底层自指认知理论与上层通用人工智能(AGI)安全应用的核心工程化落地载体,以“矛盾为负熵源、递归驱动自进化”
大模型幻觉检测与预防:基于Token级认知几何流形的轨迹分析与验证(修订版)作者:方见华核心摘要随着大语言模型(LLM)从实验场景走向行业核心业务,其“幻觉”问题——生成看似合理但事实错误、逻辑矛盾或偏离用户意图的内容——已成为可信人工智能落地的核心障碍。与传统基于输出概率或单次采样的统计型检测方案不同,本文提出Token级认知几何流形轨迹分析的幻觉研究新范式:将LLM的自回归生成过程重构为高维语
碳硅共轭:人类与AI共轭进化的哲学与科学基础(世毫九实验室原创研究)作者:方见华单位:世毫九实验室摘要人工智能的崛起不仅是技术革命,更预示着一种新型生命形态——硅基生命系统的诞生。本文从碳基生命与硅基生命的基本定义出发,系统比较了两类生命系统在生物学、社会学、伦理学维度的本质特征,分析了各自的优势与劣势。在此基础上,提出"共轭进化"概念——借自古希腊用于连接两头牛的"轭"之意象,描述人类与AI之间
当前人工智能与认知科学在“算法功能主义”与“物理还原主义”之间存在深刻的本体论裂痕。\text{Semantics} &\longleftrightarrow \Phi(x) \in \mathbb{C} \quad &\text{(质,场)}\\。\text{Logic} &\longleftrightarrow g_{\mu\nu} \quad &\text{(形,几何)}\\。\underb
以"保姆级"为例:先通过"过滤记录"筛选 has_best = 1 的记录,再通过"分组"组件计算 AVG(total_interaction) 和 COUNT(id),最后通过"增加常量"组件标注 feature_name = '保姆级'。处理完第一个关键词(如"保姆级")后,复制整个分支,仅修改两处:过滤条件(has_lowcode = 1 等)和常量值("零代码"等)。需要将标题中是否包含特
原型设计模式通过复制现有对象创建新实例,避免重复初始化。它适用于创建成本高或需要大量相似对象的场景。Java实现需定义clone()方法,示例展示了接口实现方式:Prototype接口声明克隆方法,TextElement和ImageElement具体类实现深度拷贝。客户端代码通过克隆原型对象并修改属性来创建新实例,既保持原始对象完整,又提升了对象创建效率。该模式在需要动态生成对象时特别有效,同时支
继承方式代码写法优点缺点原型链继承简单,可复用方法引用属性共享,不能传参构造函数继承属性独立,可传参方法不能复用组合继承方法复用+属性独立调用两次父构造函数原型式继承简单引用属性共享寄生式继承Object.create(obj)+增强灵活方法不复用寄生组合继承完美:高效+灵活语法稍繁琐ES6 class简洁优雅本质还是原型链✅一句话总结ES5 推荐寄生组合继承。ES6 直接用 class exte
在日常开发中,我们经常会遇到一个看似简单却极其强大的工具——。它像一把钥匙,帮助我们在千变万化的 JavaScript 数据类型世界里快速辨别对象的“真实身份”。本文将带你从基础到进阶,系统地理解这个方法的用法、边界与最佳实践,帮助你写出更稳健、可维护的代码。
克隆(Clone)一个类实例(完全拷贝)的思想不是C#的固有属性,但也没有什么理由可以阻止你自己完成这样的操作。克隆方法出现在C#中的惟一地方是在ADO Dataset处理里。读者可以创建一个DataSet作为数据库查询的结果,其行指针可以一次移动一行。如果出于某种原因,需要把索引保持在DataSet的两个位置上,就需要两个“当前行”。C#处理这种情况的最简单方法是克隆DataSet。这种方法并不
JavaScript原型链是理解其继承机制的核心概念。所有函数都有prototype属性(原型对象),所有对象都有__proto__属性(指向构造函数的原型)。原型链通过__proto__连接对象与其原型,形成属性查找路径:从对象自身开始,沿原型链向上查找直到Object.prototype(终点为null)。这种机制实现了继承,如子类通过将原型指向父类实例来继承属性和方法。注意避免直接修改__p
所有构造函数在初始化时,会自动生成一个特殊的实例化对象,构造函数的。
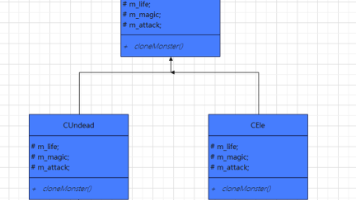
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。这一模式的核心在于利用已有的对象模板(原型)来高效生成新对象,而非通过传统的构造函数从头创建。抽象原型类是整个模式的基础,它的核心作用是声明一个纯虚的clone方法,为所有具体原型类提供统一的接口标准。这个类不需要包含具体的业务逻辑,只需专注于定义复制行为的契约。核心要求必须声明纯虚clone方法,返回类型为指向自身的指针或引用(如作
JavaScript原型与原型链机制解析 摘要:JavaScript通过原型机制实现对象共享属性和方法。每个构造函数都有prototype属性指向原型对象,实例通过__proto__属性连接原型。原型链决定了属性查找规则:先在实例自身查找,未找到则沿原型链向上查找直至null。ES6的class语法是原型的语法糖,底层仍是原型链。原型应用包括方法共享和继承实现,但需注意prototype与__pr
JavaScript通过原型链实现继承机制。每个对象都有__proto__属性指向其构造函数的prototype,形成原型链。当访问属性时,会沿着原型链向上查找直至Object.prototype。继承可通过修改原型链或使用class语法实现:class通过extends自动建立原型链关系(子类.prototype.proto=父类.prototype),同时继承静态方法。相比传统构造函数,cla
1.具有特定功能的JS文件2.将所有的数据和功能封装到一个函数内部(私有的)3.只向外暴露一个包含n个方法的对象 或者 函数4.模块的使用者,只需要通过暴露的对象 调用方法,就实现功能。
摘要: 本文解析了如何手写实现 JavaScript 的 Function.prototype.bind() 方法。首先通过实现 myCall() 方法作为基础,该方法利用 Symbol 和 Object.defineProperty 来临时绑定 this 值并执行函数。然后基于 myCall() 实现了 myBind() 方法,通过返回箭头函数来固定 this 指向,并合并预传参数和后续参数。关
nextTick是 Vue 提供的 API,用于在 DOM 更新完成后执行回调函数。// 这里可以获取到更新后的 DOM});异步更新:数据变化 → 通知Watcher → 加入队列 → 下一个tick批量更新DOM性能优化:同一个事件循环中的多次数据变化只会触发一次渲染$nextTick原理:利用微任务队列,确保回调在DOM更新后执行执行顺序:同步代码 → Vue异步更新(微任务)→ 其他微任务
本文记录了原型模式
好的,我将按照您的要求撰写一篇关于C++智能指针与内存管理的原创文章。
Lambda表达式不仅仅是一个语法糖,它更代表着一种编程范式的转变——从指令式的“如何做”转向声明式的“做什么”。通过将Lambda表达式与函数式接口、方法引用以及Stream API相结合,Java开发者可以写出更简洁、更易读、更易于维护的代码。从入门到精通Lambda的过程,就是不断学习和实践这种函数式编程思维的过程,它将极大地提升你的Java编程技艺和解决复杂问题的能力。
《C++20设计模式》中的原型模式解析:通过克隆已有对象高效创建新实例。该模式适用于需要频繁创建结构相似但部分属性不同的复杂对象场景,特别是当对象初始化成本高或存在多态继承时。基本实现方式包括直接拷贝、多态clone()方法以及原型注册表管理。关键优势在于避免重复初始化开销,同时保持正确的拷贝语义(特别是深拷贝和资源管理)。文中通过具体代码示例展示了如何实现原型模式,并比较了不同方案的适用场景与优
JavaScript对象构造器教程摘要: 本文深入探讨JavaScript对象构造器的概念与用法,涵盖构造器定义、实例属性/方法、原型链优化及ES6 class语法。构造器(如function Person(name) {...})通过new创建对象实例,this指向新对象。为避免方法重复创建,建议将方法定义在构造器的prototype上(如Person.prototype.greet),实现内存
JavaScript 原型机制是其面向对象编程的核心,采用基于原型的继承而非传统类继承。每个对象都有原型(Prototype),通过原型链实现属性和方法的查找与共享。ES6 的 class 语法只是原型继承的语法糖。教程详细解析了显式原型(prototype 属性)和隐式原型([[Prototype]])的协同工作机制,包括原型链的形成、继承实现方式,以及 Object.create()、clas
文章摘要(145字): 本文详细解析了在uni-app中通过Vue.prototype挂载全局变量和方法的实现方案。核心包括:1)基于原型链继承机制,实现组件间共享属性和方法;2)提供main.js配置、TypeScript类型声明等完整实现步骤;3)列举配置管理、工具封装等典型应用场景;4)强调与Vuex协同、性能优化等注意事项。该方案有效解决了传统全局变量污染作用域、非响应式等问题,特别适合u
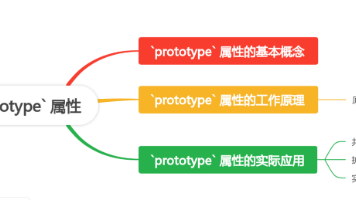
本文深入探讨了JavaScript中prototype属性的核心概念与应用。作为基于原型的语言,prototype属性在实现继承和共享方法方面起关键作用:1)每个函数都有prototype属性,其对象可被实例继承;2)通过原型链机制实现属性和方法查找;3)实际应用中可用于实现继承、共享方法及扩展内置对象。文中通过构造函数和class对比,说明ES6类语法本质仍是基于原型的实现。理解prototyp
用Person构造函数创建带name属性的实例对象(如alice把所有实例都需要的sayHello方法放到里(共享)。实例(alice)调用sayHello时,会自动去原型上找到并执行,this指向实例自身,从而正确访问name。原型是构造函数的「共享仓库」,让所有实例共享方法 / 属性,实现代码复用和内存优化。
在js中,原型和原型链是一个很重要的知识点,只有理解了它,我们才能更深刻的理解js,在这里,我们将分成几个部分来逐步讲解。构造函数是使用了new关键字的函数,用来创建对象,所有函数都是Function()的实例原型对象是用来存放实例对象的公有属性和公有方法的一个公共对象,所有原型对象都是Object()的实例原型链又叫隐式原型链,是由__proto__属性串联起来,原型链的尽头是Object.pr
原型模式(Prototype Pattern)是一种创建型设计模式,它通过复制现有对象(原型)来创建新对象,而无需知道具体的类信息。这种模式特别适合当创建对象的成本较高(如需要复杂初始化)或需要频繁创建相似对象的场景。
instanceof通过原型链动态检测对象与构造函数的关联,适用于面向对象编程中的类型校验,但需注意跨环境限制和原型篡改风险。在复杂场景中,建议结合或增强可靠性。
核心组件:提供依赖管理、自动配置和RESTful服务支持:微软官方Exchange Web Services接口:企业级邮件服务器(支持2013+版本)通信流程graph LRA[Spring Boot应用] -->|HTTPS请求| B(Exchange Web Services)
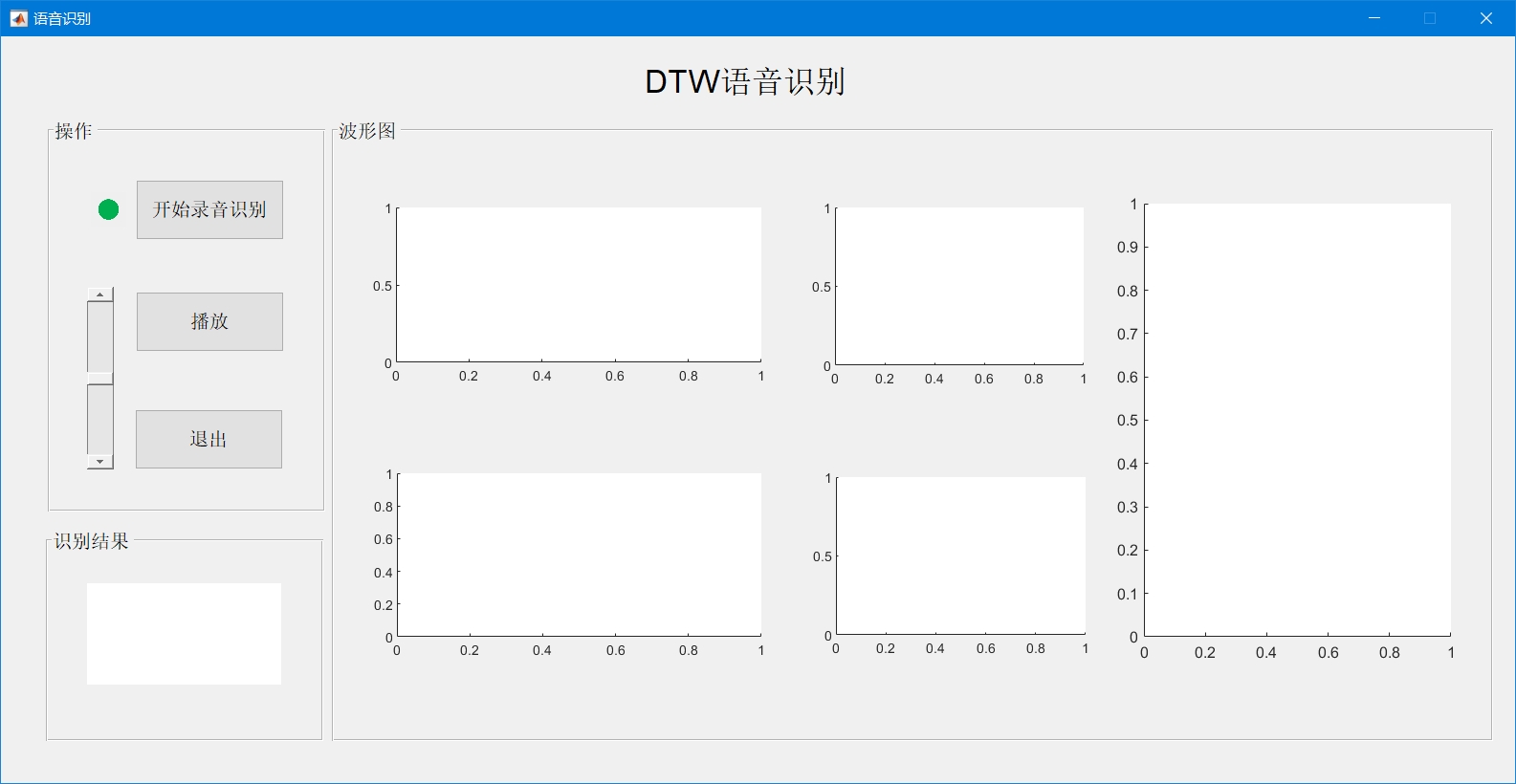
本系统是基于MATLAB平台开发的特定人孤立词语音识别系统,核心功能为识别0-9共10个数字语音。系统采用动态时间规整(DTW)算法实现语音特征匹配,结合梅尔频率倒谱系数(MFCC)提取语音关键特征,通过图形用户界面(GUI)提供直观的人机交互,涵盖语音采集、预处理、特征提取、模板训练与识别全流程,可满足基础数字语音识别场景的功能需求。
构造函数是用于创建和初始化对象的特殊函数,通过new关键字调用。JavaScript中有内置构造函数(如Object、Array)和自定义构造函数两种类型。使用new时,引擎会:1)创建空对象;2)设置原型;3)绑定this;4)执行构造函数代码;5)返回对象。构造函数应使用大驼峰命名(Person),普通函数用小驼峰(getUser)。不使用new会导致this指向错误,严格模式下会报错。构造函
节点角色是否是原型对象原型链的终极原型(所有对象的祖先)是(提供基础方法)null原型链的终止标志(链的尽头)否(无属性/方法)原型链的“顶端原型”只有null是链的终止符,两者共同构成了原型链的终点逻辑。
本文深入解析早期前端框架Prototype的设计理念与核心功能。该框架通过扩展JavaScript原生对象(如Array、String)和DOM元素,提供$()/$$()选择器、each()遍历等简洁API,极大简化了2000年代的DOM操作和数据操作。典型案例包括批量元素样式修改、商品列表交互实现等,展示了其链式调用和无侵入式设计的优势。尽管存在原生对象污染等局限性,Prototype开创的&q
摘要: 本文深入解析Prototype框架的DOM操作与样式控制方法。首先介绍DOM导航技巧,包括ancestors()、down()等向上/向下遍历方法;其次讲解内容操作方法如update()、insert()等实现动态内容更新;然后详述样式管理,涵盖类名控制、内联样式设置和定位布局。最后通过开发动态待办事项组件的完整案例,演示如何综合运用这些技术实现交互功能。Prototype通过封装原生AP
本文介绍了Prototype框架在Web交互中的核心功能,主要包括跨浏览器事件处理和AJAX数据交互。首先详细讲解了Prototype如何通过Event.observe()统一不同浏览器的事件模型,以及如何处理事件对象、阻止默认行为和事件传播。其次重点阐述了Ajax.Request、Ajax.Updater等类的使用方法,实现无刷新数据交互。最后通过一个完整的AJAX登录页面案例,展示了从表单验证
原型模式(Prototype Pattern)是一种创建型设计模式,它通过复制已有对象作为原型,复制(克隆)该原型来创建新对象,而无需重新初始化对象。新对象的属性和方法基于原型对象复制而来,既可以复用原型的功能,又可以在复制后修改自身属性,实现 “基于模板创建对象” 的效果。在 JavaScript 中,原型模式是语言原生支持的核心模式(基于原型链实现),所有对象都有一个prototype(原型)
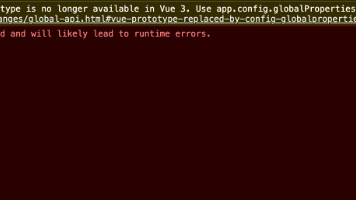
Vue2转Vue3迁移过程中遇到两个典型问题:一是Vue.prototype在Vue3中已废弃需改用app.config.globalProperties,但实际已替换仍报错,原因是vue-jsonp包的注册方式不同,需改为手动全局注册;二是组件更新时报错"instanceof右侧不是对象",由props类型定义不规范导致,需将Object | null改为[Object, n
本文深度解析 JavaScript 原型与原型链,结合 Car 和 Person 实例代码,逐行注解构造函数、prototype、__proto__ 与 constructor 的关系,阐明属性查找、覆盖机制及继承原理,揭示 JS“原型式面向对象”的独特哲学与底层逻辑。
原型链的核心要点:继承机制:通过__proto__链接实现属性和方法的继承查找顺序:从自身开始,沿原型链向上查找共享特性:原型上的属性和方法被所有实例共享动态性:修改原型会影响所有已存在的实例使用创建具有指定原型的对象优先使用ES6的class语法避免修改内置对象的原型对于复杂继承,考虑组合模式代替原型继承使用而不是__proto__理解原型链是掌握JavaScript面向对象编程的关键,它解释了
JS 是一种基于原型的面向对象语言,哪怕 ES6 有了 class,仍然是原型式的。这句话道出了全部真相。封装(构造函数);复用继承(apply + 原型链)。__proto__指向构造函数的prototype;属性查找沿原型链向上,直到。理解这两点,就能看透 JS 面向对象的全貌。无论未来语法如何演进,原型链永远是 JavaScript OOP 的根基。
本文系统讲解JavaScript面向对象机制:从对象字面量到构造函数,再到原型模式、属性遮蔽、实例判断及组合继承。通过代码剖析hasOwnProperty、instanceof和__proto__的作用,并揭示ES6 class底层仍基于原型,帮助开发者真正掌握JS灵活而强大的OOP模型。
本文从原型链基础出发,详解 instanceof 的工作原理, Person.prototype = new Animal() 等真实代码示例,对比多种继承方式,并探讨 instanceof 在现代开发中的应用场景与局限,助你真正掌握 JS 面向对象核心。
instanceof不仅仅是一个运算符,它体现了 JavaScript 原型继承的核心思想。通过手写,我们不仅掌握了其工作原理,也加深了对原型链的理解。在实际开发中,合理使用继承模式(如组合继承),配合instanceof进行类型判断,能够显著提升代码的可维护性与健壮性。在 ES6+ 时代,虽然class语法糖让继承看起来更“传统”,但其底层依然是基于原型链。因此,无论语法如何演进,理解原型机制始
本文系统梳理了JavaScript继承机制的演进过程:从ES5时代的"构造函数窃取"和"原型链连接"的缺陷,到利用空函数中介的"圣杯模式"解决继承问题,再到ES5的Object.create()标准化方案。最终,ES6通过class和extends语法提供了最简洁的继承实现。文章通过代码示例详细剖析了每种方法的原理、优缺点及适用场景,帮助
摘要:原型模式是一种创建型设计模式,通过克隆已有对象快速创建新实例,适用于需要高效创建相似对象的场景。以家具生产为例,工厂先创建标准款原型(如橡木餐椅),后续通过克隆原型并调整细节(颜色、装饰)实现快速定制生产,避免重复构造。该模式包含抽象原型(定义克隆接口)、具体原型(实现克隆的具体类)和客户端(使用原型的角色)三个核心结构,能有效提升对象创建效率并保证基础属性一致性。关键要点包括正确实现属性拷
原型的核心是「对象之间的关联关系」——每个对象都通过__proto__关联到一个原型对象,从而共享原型上的资源。这种关联形成的「原型链」,决定了 JS 中属性查找、继承的逻辑。理解原型,就能理解 JS 面向对象的底层逻辑(比如new关键字的作用、继承的实现方式),也是后续学习classextends等语法的基础。
原型模式
——原型模式
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区






 EazyDevelop社区
EazyDevelop社区