登录社区云,与社区用户共同成长
邀请您加入社区
本文探讨了利用AI技术解决Python爬虫IP封禁问题的方法。传统代理池管理存在效率低、易识别等缺陷,而AI辅助工具如ProxyPoolAI能通过智能代理筛选、动态更新和失效预警提升爬虫成功率。解决方案包含三大模块:AI驱动的代理管理工具选型、基于日志分析的封禁识别,以及自动生成代理切换与失效检测代码。实测表明,该框架可将中断率降低60%,代理成本减少30%。未来可结合深度学习预测反爬策略变化,并
实例化类,然后直接运行run()方法就好。
合理的线程生命周期管理是并发编程的基础,需要确保线程的正确启动、同步和资源释放,避免僵尸线程或资源泄漏的问题。现代C++中可以通过结合std::thread、std::mutex和std::condition_variable等组件实现高效的线程池,有效减少线程创建销毁的开销并提高任务执行效率。std::mutex是最基本的互斥量类型,但现代C++还提供了更细粒度的锁类型,如std::shared
/ 异步处理响应 client.newCall(request).enqueue(new Callback() { @Override public void onResponse(Call call, Response response) { if (response.isSuccessful()) { String jsonData = response.body().string();在构建
简单来说:接口格式兼容 OpenAI 官方 SDK。这种调用方式:第三方接口也能直接使用。如果本身就在使用:OpenAI SDKCursorDifyOpenWebUI其实迁移到 OpenAI-Compatible API 的成本非常低。base_url=即可完成兼容。对于 AI Workflow 场景来说,统一接口确实会方便很多。
这一限制给NDK接口对接带来了诸多不便:开发者必须将组件创建任务通过任务队列提交至UI线程,不仅增加了开发复杂度,更关键的是,当需要动态创建大量组件时,所有任务会堆积在单一UI线程中串行执行。系统线程池(4个)和自定义线程(2个,分别异步/同步挂载)并行创建Button组件,组件创建完成后自动挂载到UI主树,页面显示带有“系统框架线程”、“用户线程1”、“用户线程2”标签的Button;非多线程组
新人来问我,我能告诉他“这个条款三年前改过一次,原因是当时吃了官司”。DeepSeek给了我语言理解能力,公司的知识图谱给了我专业判断力。合在一起,我不只会找问题,还能说清楚“问题在哪、怎么改、为什么这样改”。法务老大没直接批我,而是把修改逻辑录进去,告诉我“下次遇到类似情况,这样处理更好”。法务每次修改文本,我都知道改了哪里、为什么改、最后怎么定的。这些“为什么”积累起来,成了我能教给下一个人的
在404的位置,上传你刚才做好的404.html文件,或者填好文件路径。不然不仅访客体验差,搜索引擎也会觉得你网站乱糟糟的,影响收录。我之前图省事弄过,结果被搜索引擎判定为违规跳转,收录掉了不少。我当时就写了一句“页面走丢啦,点击返回首页”,再加个链接。如果还是显示服务器的报错页面,就回去检查文件路径和权限。我第一次就是路径填错了,弄了半天还是默认报错,白忙活。后来花了点时间研究,踩了几个坑,给你
摘要: 面对2026年AI驱动的立体化反爬技术(如TLS指纹、前端行为分析、动态验证码),传统爬虫手段已失效。本文提出基于YOLOv8的目标检测方案,通过标注数据集、训练定制模型(识别率超90%),并集成到爬虫流程中,高效破解复杂验证码。同时强调需结合行为模拟(如随机延迟、自然鼠标轨迹)和指纹隐藏(使用Playwright)绕过前端监测。最终指出,AI定制化破解与合规操作是未来反反爬的核心方向,技
如果目标网站的验证码字体、大小、位置都固定,可以用 OpenCV 的模板匹配。掌握这些方法,是为了更好地理解攻防原理,从而构建更健壮的系统,或者在合法授权下进行安全测试。如果你有几百张标注好的验证码数据,可以自己搭一个简单的卷积神经网络(CNN)。无论是点选验证码里的多个图标,还是滑块验证码里的缺口和滑块,YOLO都能精准定位。是国内开发者开源的神器,集成了多种识别模型,对中文、算术题、简单滑块都
用了半年自愈方案,最大的感受是:它没有消灭运维工作,而是把“紧急救火”变成了“计划性维护”。工程师不用再半夜改代码,只需要每周花一小时复核AI修复的规则,优化Prompt和校验逻辑。别追求100%自愈率。初期能达到70%就很有价值,剩下30%复杂场景留给人工,逐步迭代比一步到位更靠谱。优先复用已有资产。历史解析规则、数据校验函数都是宝贵素材,喂给大模型比从零训练效果好得多。严格遵守合规底线。自愈只
本文介绍了一种基于GPT-4o的自然语言数据采集方案,旨在替代传统爬虫中繁琐的规则维护工作。作者分享了工程落地的关键步骤:通过Playwright渲染页面并截图,用结构化Prompt引导GPT-4o进行语义解析,再通过Pydantic校验输出。文章重点剖析了三个实践难题(模型幻觉、长列表漏采、成本控制)的解决方案,并给出分级处理架构图。该方案在作者业务场景中显著降低了维护成本,但强调需权衡响应速度
本文系统梳理了2026年数据采集技术的分层体系与选型策略。文章提出四个关键层级:基础层(requests+lxml)、渲染层(playwright)、智能辅助层(YOLO模型)和语义层(大模型),并给出各层的适用场景、代码示例和避坑指南。作者强调技术选型应遵循"能用简单不用复杂"的核心原则,通过分层决策流程图演示如何根据场景特点选择最优方案。最后指出工程师的核心竞争力在于精准匹配问题与工具的能力,
这套自适应工具上线后,页面改版导致的采集中断时长下降了85%,运维从“半夜救火”变成了“每周复盘”。别追求全自动。初期AI修复成功率70%就很有价值,剩下30%复杂场景留给人工迭代,逐步优化比一步到位更靠谱。优先复用历史资产。旧解析规则、校验函数、标注数据都是宝贵素材,喂给AI比从零开始效果好十倍。性能与智能要平衡。95%的请求走传统解析,只有5%触发AI,这才是能上生产的方案。全量AI调用只适合
本文介绍了一种基于AI Agent的零规则数据采集方案,通过语义理解替代传统爬虫的硬编码规则。方案采用YOLO模型检测页面区块,再结合视觉语言模型(VLM)进行语义提取,实现无需维护XPath/CSS选择器的数据采集。文章详细拆解了技术实现路径,包括页面渲染、区块裁剪、Prompt工程和数据处理流程,并总结了实际落地中的三大挑战(模型幻觉、长列表漏采、显存不足)及其解决方案。该方案在业务场景中验证
本文分享了如何将Python爬虫性能从100请求/秒优化到10000+请求/秒的实战经验。作者通过逐步优化实现了性能的显著提升:首先进行基础优化(禁用日志、复用连接池)使性能提升3倍;然后重构为异步爬虫(使用aiohttp+信号量控制并发)达到2000请求/秒;接着通过内存优化(对象池/流式处理)提升到3500请求/秒;最后采用多进程+异步混合和分布式架构(Redis任务队列)突破10000请求/
摘要:AI赋能的爬虫开发新范式 本文分享了作者使用DeepSeek V3进行爬虫开发的实战经验。通过对比测试,DeepSeek在爬虫开发领域展现出78%的一次生成成功率、优秀的中文反爬理解能力和极高性价比等优势。文章提出了完整的AI爬虫工作流,强调"AI生成+人类验证"的协作模式,并分享了三种Prompt模板:基础爬虫、反爬处理和分布式爬虫模板。通过电商评论爬取的实战案例,展示
异步爬虫架构与高并发实现 本文探讨了Python异步爬虫的核心原理与工业级实现方案,重点分析了传统同步爬虫的性能瓶颈和异步爬虫的优势。 核心内容摘要 同步爬虫的局限性: 99%时间浪费在IO等待上 多线程方案存在线程切换开销大、并发数量有限等问题 处理万级URL时性能不足 异步爬虫三大核心概念: 协程:轻量级执行单元,资源消耗极低 事件循环:异步程序的调度中心 IO多路复用:实现高并发的底层技术
2026年亚马逊第四代语义级反爬系统彻底改变了电商数据采集格局。本文揭示了该系统的核心技术原理:基于Transformer的行为语义序列分析,将用户操作视为语义单元进行整体评估。传统反爬方案如Playwright+Stealth插件、住宅IP代理等均告失效。作者团队创新性地构建了全链路伪装架构,包含动态IP混合池、真实TLS指纹复制、人类行为语义模拟引擎等核心模块,通过GPT-4o微调模型生成符合
大模型驱动的智能爬虫技术革命 本文系统介绍了大模型爬虫的技术原理与实战应用,对比传统爬虫规则匹配方式,大模型基于语义理解实现智能数据采集。核心内容包括: 技术架构分析:三层架构设计实现自然语言交互、智能抓取和数据处理 全链路实战演示:以京东游戏本数据采集为例,展示从需求描述到自动入库的完整流程 工具选型建议:对比Thunderbit等主流AI爬虫工具的特性与适用场景 关键优势在于:零代码操作、自动
1、数据集:钢材缺陷数据集包含6个类别:"crazing","inclusion","patches","pitted_surface","rolled-in_scale","scratches"对应钢材表面夹杂、划痕、压入氧化皮、裂纹、麻点和斑块6种缺陷。这些新版本的模型能够更准确地识别细微的缺陷,并且对复杂背景下的缺陷检测有更好的鲁棒性。本文所使用的钢材缺陷数据集包含了6个类别的缺陷图像:"c
混沌映射在优化算法中的应用其实并不复杂,但它带来的效果却非常显著。通过改进初始化种群,我们可以在全局搜索和局部开发之间找到更好的平衡,从而提升算法的优化和收敛性能。如果你也在研究优化算法,不妨试试混沌映射,说不定会有意想不到的收获。最后,附上一张蜣螂优化算法的初始化种群改进图,大家可以直观地看到混沌映射带来的变化。!蜣螂优化算法初始化种群改进图好了,今天就聊到这里,下次再分享更多有趣的优化算法技巧
以下是一个完整的示例,展示如何训练一个简单的神经网络分类模型,并对其结果进行可视化,包括训练过程的损失和准确率曲线、混淆矩阵以及ROC曲线等。通过这些可视化图表,您可以更直观地了解模型的训练过程和分类性能,从而进行进一步的优化和调整。-**训练过程的损失和准确率曲线**:显示训练集和验证集的损失和准确率变化情况。-**混淆矩阵**:显示分类结果的混淆矩阵,包括正确分类的数量和错误分类的数量。-**
Akamai 验证是指通过 Akamai 的内容分发网络(CDN)进行的安全验证过程。Akamai 提供了多种验证机制,以确保用户和数据的安全性。边缘身份验证(Edge Authentication):在靠近用户的边缘服务器上进行身份验证,以减少延迟并提高安全性。API 验证:通过 API 密钥和令牌来验证 API 请求的合法性。客户端验证:使用客户端证书或其他身份验证方式来验证客户端的身份。
摘要:本文介绍了一种基于具身智能的动态网页采集方案,仅需30行Python代码即可实现类人操作采集。该方案利用OpenClaw的具身智能网页采集技能,无需配置浏览器驱动、反爬中间件或手动编写选择器,只需输入采集目标和核心字段,AI即可自动完成点击、滚动、翻页和数据提取。该方案解决了传统采集工具配置繁琐、反爬处理复杂和维护成本高的问题,已在工业数据采集和电商竞品分析项目中验证。通过京东iPhone
本文通过一套全栈Python舆情监控系统的实战,从行业痛点、整体架构设计、核心模块实现、避坑指南、落地效果全流程拆解,完美解决了品牌公关、市场调研、政府舆情的三大核心痛点。一句话总结:Python舆情监控系统,全流程自动化,告别人工刷帖,漏看负面舆情概率降到0.1%,人工成本降为0,每年节省几十万。本文的所有代码均经过生产环境验证,可直接复制使用,如果你在舆情监控系统开发中遇到任何问题,欢迎在评论
本文介绍了一个适合Python初学者的爬虫实战项目——爬取软科中国大学排名数据并生成交互式可视化排名表。项目特点包括:目标网站反爬弱(仅需设置User-Agent)、代码清晰(使用requests+BeautifulSoup4基础库)、数据实用(包含学校名称、排名、省份、总分等关键信息)、成果可视化(生成可交互的HTML表格)。 主要内容包括: 环境准备:安装requests、BeautifulS
Python爬虫性能优化实战:协程异步架构实现10倍效率提升 本文针对传统爬虫的性能瓶颈,提出了一套全链路协程异步的优化方案。文章首先分析了爬虫慢的根本原因——95%时间浪费在IO等待上,指出多线程方案存在GIL锁和资源占用高的缺陷。随后详细介绍了生产级异步爬虫架构设计,包括全链路异步、精准并发控制、TCP连接池复用等核心优化点。通过对比伪异步代码和真异步实现的差异,作者展示了如何正确使用aioh
本文对比了Python爬虫开发中Requests同步爬虫和aiohttp异步爬虫的性能差异。Requests的同步阻塞模型在大规模数据采集时存在性能瓶颈,而aiohttp基于异步IO模型,通过事件循环和协程实现并发请求,将网络IO等待时间压缩到极致,性能可提升3倍以上。文章详细解析了两种模型的底层原理,并通过代码示例展示了如何将同步爬虫改造为异步爬虫,包括环境准备、核心API转换等关键步骤。最后还
字段定义 NEWS_FIELD_DEFINITION = """- title: 新闻标题,字符串类型,提取原文中的完整新闻标题- publish_time: 发布时间,字符串类型,格式为YYYY-MM-DD HH:MM:SS,无则填null- author: 发布作者,字符串类型,提取原文中的作者名称,无则填null- source: 新闻来源,字符串类型,提取原文中的发布机构/来源,无则填nu
% 用最优参数训练最终模型% 7:3拆分训练集和测试集,别用交叉验证的那部分数据当测试集,作弊就没意思了% 计算隐藏层输出% 求解输出权重fprintf('最终测试集准确率:%.4f\n', test_acc);我用iris数据集跑的时候,普通ELM的测试准确率大概在88%-92%之间波动,用这个PSO-HELM之后稳定在95%以上,而且每次跑的结果都差不多,再也不用看运气了。
【代码】自动对焦搜索算法。
本文主要是对RSA算法进行了一个详细的分析,并且实际应用在逆向Temu登录中,以实战的方式方便读者理解及学习
当我们发起请求并获得响应时,发现响应数据也经过了加密。最后,我们将上述解密逻辑封装到一个JS文件中,并通过Python调用这个JS文件来实现逆向操作。在扣取到的JS代码中,我们补充所需的浏览器环境,模拟实际的运行环境。这样,我们可以更准确地解析参数并发起请求。这个步骤帮助我们了解如何加密b和kiv参数,进而能够正确地解密这些参数。为了分析这些加密参数,我们需要进一步定位JS加密代码的位置。定位到J
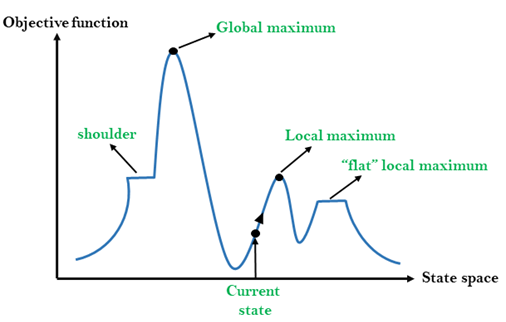
它基于图像的清晰度评价值来确定镜头的移动方向和步长,通过不断迭代逐渐逼近最佳焦距。虽然爬山算法在自动对焦领域得到了广泛应用,但仍存在一些挑战和限制,需要进一步的研究和改进来提高其性能和适用性。为了解决这些问题,研究者们提出了各种优化和改进方法,如采用拟合曲线的方式预测最佳峰值点,以减少搜索时间和提高对焦精度。算法然后以一个预定的步长沿某一方向(通常是向清晰度更高的方向)移动镜头,并捕获另一帧图像计
爬山算法(Hill Climbing Algorithm)是一种常见的启发式搜索算法,常用于解决优化问题。其核心思想是从一个初始状态出发,通过逐步选择使目标函数值增大的邻近状态来寻找最优解。接下来,我们将通过 JavaScript 实现一个简单的爬山算法,帮助大家理解其原理和应用。从一个初始状态开始。评估当前状态的目标函数值。在当前状态的邻居中选择一个目标函数值更大的状态。如果找到了更优的邻居,则
Plotly是数据可视化领域备受推崇的库,它提供了创建丰富、交互式且高质量的图表的能力.支持多种图表类型,如线图、散点图、柱状图、饼图、热力图等
爬山算法
——爬山算法
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 AI Agent技术社区
AI Agent技术社区



 HarmonyOS开发者社区
HarmonyOS开发者社区
 CSDN-OPC开发者社区
CSDN-OPC开发者社区

 openEuler 社区
openEuler 社区

 AtomGit开源社区
AtomGit开源社区








 DeepSeek技术社区
DeepSeek技术社区



 腾讯云开发者社区
腾讯云开发者社区




 广州城市开发者社区
广州城市开发者社区

 2048 AI社区
2048 AI社区





 魔乐社区
魔乐社区