RAG检索增强生成技术学习
检索增强 LLM ( Retrieval Augmented LLM ),简单来说,就是给 LLM 提供外部数据库,对于用户问题 ( Query ),通过一些信息检索 ( Information Retrieval, IR ) 的技术,先从外部数据库中检索出和用户问题相关的信息,然后让 LLM 结合这些相关信息来生成结果。下图是一个检索增强 LLM 的简单示意图。
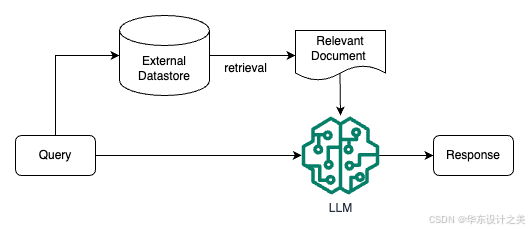
传统的信息检索工具,比如 Google/Bing 这样的搜索引擎,只有检索能力 ( Retrieval-only ),现在 LLM 通过预训练过程,将海量数据和知识嵌入到其巨大的模型参数中,具有记忆能力 ( Memory-only )。从这个角度看,检索增强 LLM 处于中间,将 LLM 和传统的信息检索相结合,通过一些信息检索技术将相关信息加载到 LLM 的工作内存 ( Working Memory ) 中,即 LLM 的上下文窗口 ( Context Window ),亦即 LLM 单次生成时能接受的最大文本输入。
为什么需要引入RAG呢?
1.对长尾知识的处理
LLM 对通用大众知识的生成通常较为准确,但面对长尾知识时,回复可靠性明显下降。ICML 会议上的这篇论文 Large Language Models Struggle to Learn Long-Tail Knowledge,研究发现,LLM 在事实性问答中的准确性,与预训练数据中相关领域文档的数量高度相关 —— 相关文档越多,准确性越高。由此可得出核心结论:LLM 对长尾知识的学习能力较弱,论文中的相关性曲线也印证了这一点。
为提升 LLM 对长尾知识的处理能力,常见思路是在训练数据中补充更多长尾知识,或增大模型参数量。这两种方法虽有实验数据支撑其有效性,但经济性极差 —— 需依赖海量训练数据与超大模型参数,才能大幅提升回复准确性。相比之下,通过检索在 LLM 推断阶段,将相关信息作为上下文(Context)提供给模型,既能保证较高的回复准确性,又具备更强的经济性。
2.私有数据
ChatGPT 等通用 LLM 的预训练数据以公开数据为主,不包含私有数据,因此缺乏私有领域知识。例如询问某企业内部知识时,LLM 大概率会给出未知或编造的回复。
若通过预训练阶段加入私有数据、或用私有数据微调模型来解决,不仅训练与迭代成本极高,还存在隐私泄露风险 —— 已有研究与实践表明,通过特定攻击手段,可促使 LLM 泄漏训练数据,若训练数据含私有信息,极易引发隐私安全问题。
而将私有数据构建为外部数据库,让 LLM 回答私有数据相关问题时,先从数据库中检索出相关信息,再结合这些信息生成回复,能有效规避上述问题。这种方式无需通过预训练或微调,让 LLM 在参数中 “记忆” 私有知识,既节省了训练与微调成本,也在一定程度上降低了私有数据的泄露风险。
3.数据新鲜度的保证
LLM 的知识全部来源于训练数据。尽管多数知识的更新周期较长,但仍有部分信息更新频繁,导致 LLM 从预训练数据中学到的这部分内容易过时。
若将这类高频更新的知识构建为外部数据库,供 LLM 在需要时检索调用,就能在不重新训练 LLM 的前提下,实现模型知识的更新与拓展,从而直接解决 LLM 的数据新鲜度问题。
4.来源验证和可解释性
常规情况下,LLM 的生成结果不会标注信息来源,难以解释 “为何生成该内容”。而通过为 LLM 提供外部数据源,让其基于检索到的相关信息生成回复,可在生成结果与信息来源之间建立明确关联。
这种关联能实现生成结果的来源追溯,大幅增强回复的可解释性与可控性 —— 用户可清晰知晓 LLM 生成回复所依据的具体信息。
此外,针对检索增强方案,存在一个常见疑问:随着 LLM 上下文窗口(Context Window)的不断扩大,是否可直接在上下文中纳入海量信息,从而不再需要检索环节?
RAG核心模块
为了构建检索增强 LLM 系统,需要实现的关键模块和解决的问题包括:
- 数据和索引模块:将多种来源、多种类型和格式的外部数据转换成一个统一的文档对象 ( Document Object ),便于后续流程的处理和使用。文档对象除了包含原始的文本内容,一般还会携带文档的元信息 ( Metadata ),可以用于后期的检索和过滤。
- 查询和检索模块:如何准确高效地检索出相关信息
- 响应生成模块:如何利用检索出的相关信息来增强 LLM 的输出
RAG调用模式
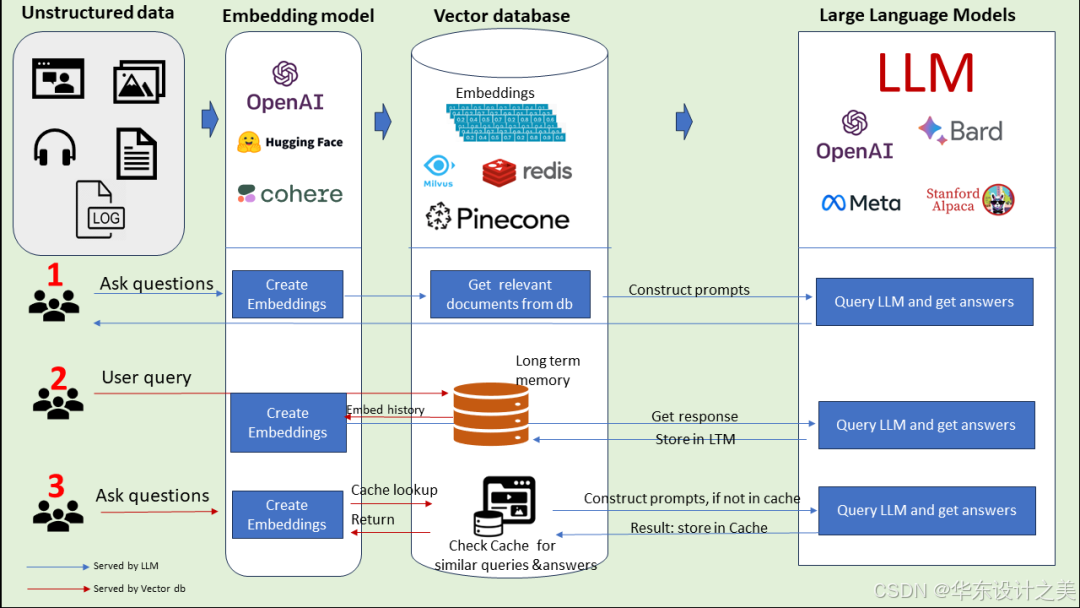
1. 模式一:非结构化数据驱动的经典 RAG(文档检索增强)
该模式是处理静态非结构化数据的核心 RAG 方案,聚焦于将分散的非结构化信息转化为 LLM 可利用的上下文,核心逻辑是 “先检索文档,再生成回答”,流程与价值可进一步拆解如下:
核心流程补充
- 数据预处理阶段:需先对非结构化数据进行标准化处理。这类数据包括但不限于企业内部文档(如 PDF 格式的产品手册、项目方案)、历史对话记录、行业报告、网页文本等;处理时会先进行文本分段(避免单段文本过长超出 Embedding 模型限制),再通过 Embedding Model 将每段文本转化为高维向量,最终将这些向量与原文片段对应存储到向量数据库中,形成 “向量 - 文本” 的映射索引。
- 用户交互阶段:当用户提出问题后,系统会先将问题也通过相同的 Embedding Model 向量化,再基于向量相似度算法(如余弦相似度),在向量数据库中检索出与问题最相关的 Top N 个文本片段;随后进入Prompt 构建环节—— 并非直接将检索结果传给 LLM,而是会结合 “指令(如 “基于以下参考信息,准确回答用户问题,不编造内容”)+ 用户问题 + 检索到的文本片段”,组装成结构化的 Construct Prompts,最后将其输入 LLM 生成回答并返回给用户。
适用场景与优势
- 适用场景:企业知识库问答(如员工查询内部规章制度)、学术文献辅助解读(如基于论文片段回答研究问题)、产品手册咨询(如用户查询家电操作步骤)等静态非结构化数据的问答需求。
- 核心优势:无需将海量非结构化数据注入 LLM 参数,大幅降低模型训练 / 微调成本;通过 “文档检索 + 上下文约束”,能强制 LLM 基于真实文档生成回答,显著减少幻觉。
潜在注意点
- 需根据数据类型选择匹配的 Embedding Model(如处理技术文档可选代码类 Embedding 模型,处理通用文本可选通用语义模型),否则会影响检索精度。
- 文本分段的粒度需合理:段度过长可能导致检索到的信息包含冗余内容,段度过短可能割裂文本逻辑,需结合数据特点调试。
2. 模式二:长时记忆导向的 RAG(用户交互记忆增强)
该模式的核心是 “构建用户专属的长时记忆库”,区别于模式一的 “文档检索”,其检索对象是用户的历史交互数据(问题 + 回答),解决 LLM 原生多轮对话中 “上下文丢失” 的问题,让模型能理解用户的长期需求逻辑。
核心流程补充
- 记忆库初始化与更新:当用户首次提出问题时,系统会先将问题通过 Embedding Model 向量化,将 “问题向量 + 问题原文” 存储到长时记忆数据库(本质是向量数据库,侧重 “用户交互数据” 的存储);随后调用 LLM 生成回答,生成后会将 “回答文本 + 对应问题向量” 也存入记忆库,形成 “用户问题 - 模型回答” 的完整记忆条目。
- 多轮交互中的记忆调用:当用户提出后续问题(如 “基于上次说的方案,补充成本分析”)时,系统会先将新问题向量化,在长时记忆库中检索与该问题语义相关的历史交互条目(如 “上次的方案内容”);再将 “历史记忆条目 + 新问题” 整合为 Prompt 输入 LLM,让 LLM 能基于用户的历史对话逻辑生成连贯回答,而非 “每次对话都从零开始”。
适用场景与优势
- 适用场景:个性化咨询(如律师对同一客户的多轮案件沟通)、持续项目协作(如团队成员围绕同一项目的多次问答)、个人学习助手(如用户长期学习某一学科,模型记住其已掌握的知识点)。
- 核心优势:实现 “个性化长时记忆”,解决通用 LLM 多轮对话中 “忘记前文” 的问题;记忆库独立存储,可灵活调取特定用户的历史交互数据,适配个性化需求。
潜在注意点
- 需做好记忆库的 “去冗余” 与 “时效性管理”:若用户重复提问相似问题,需避免记忆库中存储大量重复条目;若历史回答因信息更新而过时,需支持手动或自动清理旧记忆。
- 需强化隐私保护:记忆库存储的是用户专属交互数据,需通过权限控制、数据加密等方式,防止用户隐私信息泄露。
3. 模式三:缓存优先的 RAG(高频问答效率增强)
该模式是 “以缓存换效率” 的优化方案,核心逻辑是 “先查缓存,再查 LLM”,通过复用历史问答结果,减少对 LLM 的重复调用,降低成本并提升响应速度,本质是 RAG 与缓存机制的结合。
核心流程补充
- 缓存库构建逻辑:此处的 “Cache” 并非传统的键值对缓存,而是基于向量数据库的 “问答对缓存库”—— 系统会将历史中用户的问题、LLM 的回答分别向量化,以 “问题向量 - 回答向量 - 原文问答对” 的形式存储到缓存库中,同时可设置缓存有效期(如 7 天、30 天)。
- 用户请求的 “缓存命中判断”:当用户提出新问题时,系统先将问题向量化,在缓存库中进行相似度检索;若检索到相似度高于预设阈值(如 0.85)的历史问题,且缓存未过期,则直接将对应的历史回答返回给用户,无需调用 LLM;若未检索到相似问题(未命中),或缓存已过期,则正常调用 LLM 生成回答,生成后将 “新问题 + 新回答” 的向量与原文存入缓存库,为后续相似请求提供缓存支持。
适用场景与优势
- 适用场景:高频重复问答场景(如客服领域的 “产品保修政策”“退款流程” 等常见问题)、公开信息查询(如 “某城市的天气”“某节日的日期” 等固定或低频更新的问题)、高并发请求场景(如电商大促期间,大量用户咨询相同的活动规则)。
- 核心优势:极致提升响应速度 —— 缓存命中时可实现毫秒级回复,远快于 LLM 的秒级生成速度;大幅降低成本 —— 减少对 LLM API 的重复调用,尤其对高频问题占比高的场景,成本节省效果显著。
潜在注意点
- 需动态调整相似度阈值:阈值过高(如 0.95)会导致 “明明有相似缓存却未命中”,阈值过低(如 0.7)会导致 “返回不相关的缓存回答”,需结合业务场景测试最优值。
- 需做好缓存的 “时效性管理”:对信息易更新的问题(如 “某产品的最新价格”),需缩短缓存有效期,或在信息更新时主动清空旧缓存,避免返回过时答案。
| 维度 | 模式一(非结构化数据 RAG) | 模式二(长时记忆 RAG) | 模式三(缓存优先 RAG) |
|---|---|---|---|
| 核心检索对象 | 静态非结构化文档片段 | 用户历史交互(问题 + 回答) | 历史问答对缓存 |
| 核心目标 | 处理文档知识、减少幻觉 | 实现个性化长时记忆 | 提升响应速度、降低成本 |
| 典型适用场景 | 企业知识库问答 | 个性化多轮咨询 | 客服高频问题 |
RAG vs SFT
- 预训练 LLM(基准):“自带通用知识的基础模型”。知识完全固化在模型参数中,仅包含预训练截止日前的通用数据,无法主动更新知识,也无法定制化行为,适合处理无特殊要求的通用问答(如 “地球半径是多少”)。
- SFT(预训练 + 有监督微调):“参数级定制的专业模型”。通过特定领域 / 场景的标注数据,调整模型参数,让模型 “记住” 特定知识或 “学会” 特定行为(如医疗术语表达、法律文书风格),本质是将知识 / 能力内化到模型参数中。
- RAG(预训练 + 检索增强):“外部知识辅助的动态模型”。不改变模型参数,而是在生成回答前,从外部数据库(文档、实时数据等)中检索相关信息,作为上下文喂给模型,本质是让模型 “临时借用” 外部知识。
| 对比维度 | 预训练 LLM | 预训练 + SFT | 预训练 + RAG |
|---|---|---|---|
| 1. 数据处理与时效性 |
- 知识固定于 “预训练截止日”,无法更新(如 2023 年训练的模型不知道 2024 年的新政策); - 数据范围仅限通用公开数据,无领域 / 私有数据。 |
- 知识范围扩展到 “微调数据截止日”,但更新需重新准备数据、重新微调(如新增 100 份文档需重新跑微调流程); - 数据需标注(如 “问题 - 正确回答” 对),且存在 “灾难性遗忘” 风险(新微调知识覆盖旧知识)。 |
- 知识完全依赖外部数据库,更新仅需同步数据到数据库(如新增文档直接嵌入存向量库),无需改动模型; - 支持实时数据检索(如对接 API 查实时天气、股票),时效性最强。 |
| 2. 知识覆盖与准确性 |
- 仅覆盖通用高频知识,长尾知识(如某小众行业标准)准确性极低; - 无法验证知识来源,易编造 “看似合理” 的错误信息(幻觉)。 |
- 可覆盖特定领域的中高频知识(如医疗中的常见病诊断),但长尾知识仍依赖微调数据量(数据少则准确性低); - 知识准确性依赖微调数据质量(数据有错误则模型会学错)。 |
- 知识覆盖范围等于 “外部数据库范围”,只要数据库包含,长尾知识(如某企业 2024 年 Q1 财报细节)也能准确回答; - 准确性依赖检索精度(检索到相关数据则准确),且可追溯知识来源(如 “回答来自 XX 文档第 3 页”)。 |
| 3. 定制化能力 | - 无定制化能力:输出风格(如正式 / 口语)、行业术语、行为逻辑(如 “拒绝敏感问题”)均固定,无法调整。 |
- 强定制化能力: 1. 行为定制(如儿童机器人的 “温和语气”、法律模型的 “严谨表述”); 2. 知识定制(如让模型记住某公司的专属产品参数); 3. 格式定制(如输出固定的报告模板、JSON 结构)。 |
- 弱定制化能力: 1. 仅能通过 “检索内容 + Prompt 指令” 调整回答(如 “基于检索到的产品文档,用口语化表达”); 2. 无法改变模型本身的行为逻辑(如模型天生的口语风格,无法通过 RAG 改成学术风格)。 |
| 4. 幻觉控制机制 | - 无机制:完全依赖模型自身的 “知识记忆”,遇到未知内容易幻觉(如编造不存在的学术论文)。 | - 间接控制:通过 “领域数据对齐” 减少该领域的幻觉,但遇到 “微调数据外” 的内容,幻觉仍会出现(如医疗 SFT 模型遇到罕见病,可能编造治疗方案)。 |
- 直接控制:“检索证据 + Prompt 约束” 双重保障 —— 1. 回答必须基于检索到的信息,无信息则提示 “无法回答”; 2. 可在 Prompt 中明确 “不允许编造未检索到的内容”,从指令层面抑制幻觉。 |
| 5. 透明度与可追溯性 | - 黑箱:无法解释回答的来源,用户不知道 “模型为什么这么说”。 | - 半黑箱:回答逻辑基于微调数据,但无法定位具体来自哪条训练数据,仍无法追溯单一回答的依据。 |
- 全透明: 1. 可展示 “回答对应的检索片段”(如 “参考《2024 公司规章》第 5 章”); 2. 可查看检索相似度(如 “该片段与问题相似度 92%”),让用户判断回答的可信度。 |
| 6. 成本与资源需求 |
- 单次预训练成本极高(千万级 GPU 小时),但后续使用无额外成本; - 无需额外系统(仅需模型服务)。 |
- 成本包含三部分: 1. 数据成本(标注、清洗,领域数据标注单价可达数百元 / 条); 2. 计算成本(微调需 GPU,如用 LoRA 微调 7B 模型需数千元,175B 模型需数十万元); 3. 更新成本(每次更新数据需重新微调,长期成本高)。 |
- 成本集中在 “外部系统”: 1. 存储成本(向量数据库,如 Milvus、FAISS,按数据量计费,TB 级年费数千元); 2. 检索成本(API 调用、相似度计算,低并发场景成本可忽略); 3. 无更新成本(数据更新仅需同步到向量库)。 |
| 7. 落地核心挑战 |
- 知识过时(如无法回答 2025 年的新事件); - 长尾知识缺失; - 幻觉严重。 |
- 数据质量与规模(无高质量标注数据则微调无效); - 灾难性遗忘(新微调知识覆盖旧知识); - 更新效率低(紧急数据更新需数天微调周期)。 |
- 检索精度(如 Embedding 模型不匹配导致检索到无关内容); - 外部数据治理(需维护数据库的完整性、时效性,如实时同步官网政策); - 长文档处理(如 PDF 长文档分段不合理影响检索效果)。 |
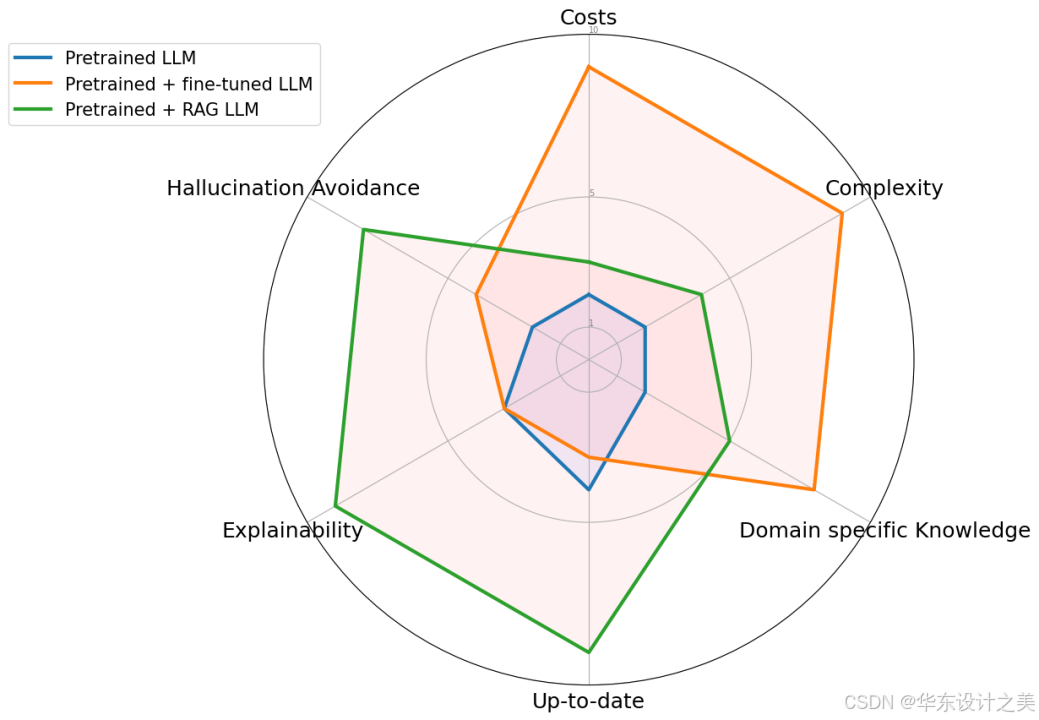
与预训练或微调基础模型等传统方法相比,RAG 提供了一种经济高效的替代方法。RAG 从根本上增强了大语言模型在响应特定提示时直接访问特定数据的能力。为了说明 RAG 与其他方法的区别,请看下图。雷达图具体比较了三种不同的方法:预训练大语言模型、预训练 + 微调 LLM 、预训练 + RAG LLM。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)