登录社区云,与社区用户共同成长
邀请您加入社区
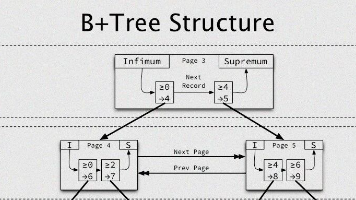
MySQL 索引为何偏偏选中 B+ 树?这个问题背后藏着不少的设计考量。其实,MySQL 选择 B+ 树。这背后既有数据结构的精妙设计,也离不开一个关键的现实约束——。因为数据库的数据最终是落在磁盘上的,而磁盘读写比内存操作慢好几个数量级。。B+ 树的层数少、叶子节点有序相连、非叶子节点仅存键值等特性,恰恰都是为了这个目标服务的。下次再有面试官问你“为什么是 B+ 树?”,你不妨从“如何减少磁盘
对于使用Maven构建工具的Java Web开发者来说,将Tomcat服务器无缝集成到IntelliJ IDEA开发环境中是提高开发效率的关键一步。本文将深入解析在Maven项目结构中配置Tomcat的五个核心环节,帮助开发者避免常见的配置陷阱。通过以上五个关键配置项的详细设置,开发者可以构建高效的Maven Web项目开发环境。注意:Tomcat 10.x要求Servlet 5.0规范,与旧版项
对于大多数初次接触Spark集群开发的工程师和学生而言,真实的多机环境搭建存在硬件成本高、网络配置复杂等门槛。伪分布式模式通过在单台机器上模拟多节点行为,实现了"小身材大能量"的实践效果。提示:伪分布式并非生产环境方案,其主要适用于原型开发、CI/CD流水线测试以及教学演示场景。实际项目部署建议采用Kubernetes或YARN等成熟方案。通过本指南的实践,开发者可以在单台机器上获得接近真实集群的
在 Python 开发中,管理项目依赖是一个至关重要的环节。想象一下,你同时在开发两个项目:项目A需要 `requests` 库的 2.20 版本,而项目B却依赖最新的 2.28 版本。如果将它们都安装在全局环境中,势必会引发版本冲突,导致其中一个项目无法正常运行。这就是所谓的“依赖地狱”。为了解决这个问题,Python 提供了虚拟环境(Virtual Environment)这一强大工具。本文将
这篇文章摘要: 本文全面总结了C++技术面试和Linux系统编程的核心知识点,涵盖以下内容: C++基础: 虚函数、多态、STL容器实现原理 智能指针、类型转换、模板等高级特性 内存管理、异常处理等机制 Linux系统: 进程线程区别与同步机制 进程间通信方式及实现 文件描述符、内存管理等系统调用 数据结构与算法: 红黑树、哈希表等数据结构 排序算法、LRU缓存等经典问题 链表操作等常见面试题 项
C++20协程的引入,为我们提供了一条通向结构化并发编程的救赎之路,彻底改变了我们处理异步操作的方式。传统的回调模式中,错误需要在每个回调中单独处理,而协程允许我们使用熟悉的try-catch块来捕获异步操作中抛出的异常。例如,一个异步HTTP服务器可以使用协程来处理每个连接,代码清晰度接近同步版本,同时保持了异步程序的高性能特性。通过将传统的回调函数转换为协程,我们可以将嵌套的异步调用展平为线性
C++性能优化是一门平衡艺术,需要在代码清晰度、开发效率和运行效率之间找到最佳平衡点。现代C++提供了丰富的工具和特性来帮助我们编写高性能代码,但更重要的是培养性能意识和对底层细节的理解。优秀的C++开发者不仅要知道如何优化,更要知道何时优化以及优化什么。只有将性能考量融入日常开发实践,才能持续产出高效的C++代码。
自动管理对象(局部、静态、成员)遵循 “构造反序” 的默认规则,无需手动干预;手动管理对象(堆对象)需按资源依赖控制delete顺序,智能指针是最佳实践;复杂场景(继承、容器)需关注虚析构、声明顺序等细节,避免依赖冲突。咱们在写代码时,无需死记所有规则,只需抓住 “资源安全释放” 的核心目标:确保被依赖的资源后释放,优先使用自动管理方式(局部对象、智能指针),就能避免 90% 以上的析构相关问题。
本实验通过一个基于C++的支付系统案例,演示代理模式和策略模式的经典应用场景,并展示高效开发实践中的模块化设计、代码复用和扩展性优化。实验代码分为两部分:支付策略模块(策略模式)与支付权限验证模块(代理模式),二者协同实现功能解耦与业务扩展。- 策略逻辑:每个`executePayment()`返回`bool`状态码,而非抛出异常(更适合业务层判断)。- 缓存代理实例:对高频支付场景,可复用`Pa
设计模式在Java中的实践,如单例模式和工厂模式,展现了面向对象思想的精髓。从基础的synchronized关键字到高级的Fork/Join框架,Java让开发者能够充分利用多核处理器的计算能力。Java语言的持续演进证明了其强大的生命力。从最初的Applet到现在的云原生应用,Java始终与时俱进,为开发者提供稳定而强大的编程平台。丰富的开源库覆盖了从Web开发到人工智能的各个领域,持续推动着技
本文深入解析面试高频考点Kadane算法,详细讲解其动态规划思想及Python/Java双语言实现。通过对比两种语言的代码风格和工程实践,帮助开发者掌握最大子数组和问题的O(n)解法,并提供了常见变体问题的解决方案和面试技巧。
直接使用会遇到一个陷阱:默认实现的是最大堆,而我们需要最小堆。这里有三种解决方案:// 方案1:使用greater比较器// 方案2:自定义比较结构体// 方案3:存储负值(不推荐但常见于竞赛代码)// 存储距离的负值提示:方案1最简洁,但方案2在需要复杂比较逻辑时更灵活。方案3虽然节省代码,但会降低可读性。
在最近的一个分布式存储项目中,我们最终选择了改造ZLToolKit的日志模块:保留其高效的异步架构,但替换文件通道为自定义的压缩存储实现,同时增加网络通道支持实时日志分析。这种混合方案在保证性能的同时,满足了运维团队的实时监控需求。在C++生态中,面对spdlog、glog、ZLToolKit等众多方案,开发者常陷入选择困境。本文将带你穿透表象,从线程模型、IO策略到落地实践,构建完整的选型方法论
当你第一次在CTF比赛中遇到RSA共模攻击题目时,可能会感到无从下手。别担心,本文将带你从零开始,用Python脚本快速解决这类问题。我们以SWPUCTF 2021新生赛的crypto2题目为例,手把手教你编写攻击脚本,让你在5分钟内搞定这道题。RSA共模攻击(Common Modulus Attack)是指当两个不同的公钥使用相同的模数n时,攻击者可以利用这两个公钥对同一明文进行加密的密文来恢复
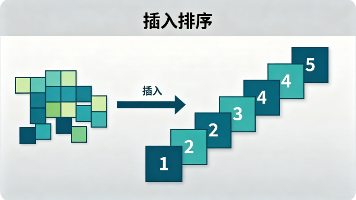
插入排序是一种简单高效的稳定排序算法,时间复杂度为O(n²),但在处理接近有序数据时性能接近O(n)。其核心思想是逐个选取元素并插入到有序区的正确位置,通过后移元素腾出空间,减少无效操作。算法实现简洁直观,仅需常数级额外空间,适合小规模数据(如n<1000)和部分有序场景。虽然大数据量性能不如快速排序等算法,但其稳定性和自适应特性使其成为基础排序算法中最实用的选择之一,也是算法学习的重要基础
1. tiny_obj_loader.h 的使用include这个头文件需要先定义一个宏#define TINYOBJLOADER_IMPLEMENTATION#include "tiny_obj_loader.h"122. tiny_obj_loader.h 中数据结构的介绍2.1 attrib_t// Vertex attributestypedef struct {std:...
11.34 基于近似动态规划的优化控制研究及 在电力系统中的应用上世纪 50 年代以来,在空间技术发展和数字计算机实用化的推动下,动态系统的优化理论得到了迅速的发展,形成了一个重要的学科分支——最优控制[1-2] 。它在空间技术、系统工程、多级工艺设备的优化等领域都有越来越广泛的应用。因而更深入研究最优控制问题,无论在理论上,还是在实践上都具有重大的意...
1.LDALDA是一种三层贝叶斯模型,三层分别为:文档层、主题层和词层。该模型基于如下假设:1)整个文档集合中存在k个互相独立的主题;2)每一个主题是词上的多项分布;3)每一个文档由k个主题随机混合组成;4)每一个文档是k个主题上的多项分布;5)每一个文档的主题概率分布的先验分布是Dirichlet分布;6)每一个主题中词的概率分布的先验分布是Dirichlet分布。文档的生成过程如下:1...
数据结构与算法
——数据结构与算法
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 AI Agent技术社区
AI Agent技术社区



 DAMO开发者矩阵
DAMO开发者矩阵
