登录社区云,与社区用户共同成长
邀请您加入社区
摘要:一个LLM模型对比网站
7月3日消息,7月2日,一则人事变动在AI圈引发关注:1997年出生的孙天祥正式加入百度,出任基础模型研发部(BMU)负责人,同时进入百度模型委员会(BMC)。腾讯方面,除引入姚顺雨担任首席AI科学家外,2026年3月正式启动“青云计划”实习生招聘,面向AI大模型相关技术领域的顶尖本硕博同学,开放大语言模型、多模态、智能体等六大技术领域。其中,薪酬政策上不封顶。2026届秋季校园招聘计划发放超70
比如维护单调递增栈时,若当前元素a[i]比栈顶元素小,说明栈顶元素 “挡路” 了:如果直接入栈,栈就会出现 “大元素在前、小元素在后” 的情况,违背递增规则。因此需要先弹出所有≥a[i]的元素,直到栈顶元素<a[i](或栈为空),再将a[i]入栈。提到栈,大家首先想到的是 “先进后出” 的线性结构,而单调栈,顾名思义,就是在普通栈的基础上,给元素加上了 “单调性” 的约束 —— 栈内的元素必须严格
过去七年间,特斯拉每隔一段时间就会释放新产品的消息,比如开售Cybertruck皮卡和Semi重卡,揭开了Cybecab和Robovan的面纱,预告了新一代Roadster跑车,入门车型Model 2也一度若隐若现。但与同一商场内的 鸿蒙智行、小米、理想、 智己等品牌的新车相比,Model Y在外观、内饰、空间、配置、动力、电池等方面并不占优,甚至多数指标处于劣势。马斯克擅长造车,更擅长讲故事。如
SEO和GEO的核心区别在于:SEO追求在搜索结果中被看到,而GEO追求被AI直接引用为答案。2026年的搜索环境正在被AI重塑(如Google AI Overview、ChatGPT等),传统SEO已不够用。GEO要求内容具备问答体格式、可引用单元和公开URL,且封闭平台(如公众号)内容无法被AI抓取。优化建议包括:确保内容可被抓取、使用问题式标题、参考被AI引用的优质内容。两者需结合使用,其中
面试过DeepSeek的应届生表示,面试流程超过6轮,现场写代码加系统设计加论文复现,多个参与过面试的应届生表示,面试官会问得非常细,不是聊大方向,是抠实验细节,并且面试官会针对你说的论文,一直追问到你答不上来为止,测试你是不是真的做过。到了特斯拉,他更是直言,说车并不重要,真正重要的是“制造机器的机器”。再说,R1,它的核心突破是摒弃人类示范,纯靠“解题—奖励—再解题”的强化学习循环,让模型自己
https://blog.csdn.net/2402_87731470/article/details/152548698?sharetype=blogdetail&shareId=152548698&sharerefer=APP&sharesource=2401_85812043&sharefrom=link
处理长文本时,自动摘要功能极其有用。通过API可以快速提炼文章核心内容,生成简洁准确的摘要,适用于新闻、报告、论文等多种场景。通过指定摘要长度、重点关注的方面或目标读者,可以获取高度定制化的摘要结果。这对于处理大量信息的企业和个人特别有价值。
allOf(CompletableFuture>... cfs)`方法返回一个新的CompletableFuture,当所有给定的CompletableFuture都完成时,它才完成。此外,我们可以使用`completedFuture`方法快速创建一个已经包含结果的CompletableFuture,或者使用无参构造函数创建一个未完成的CompletableFuture,随后再通过`complet
我们可以假设,爬山的最大高度为maxHeight,到达此高度的最小步数为minStep,则初始时,maxHeight = maxtrix[0][0],minStep = 0。初始时,小明位于(0, 0)位置,此时走的步数step = 0,假设地图为matrix,则到高度matrix[0][0]的最短步数为step=0。本题需要注意的是:向四个方向进行深搜时,需要注意当前位置的高度值,和下一个位置的
而堆内存的管理涉及复杂的分配器算法,GNU的malloc实现采用三级缓存机制:小型对象使用bin buckets数组,中型对象通过中央缓存管理,巨型对象直接请求操作系统。该设计规避了原始C风格内存分配时异常无法解决的残留内存问题,通过书中提供的文件系统API安全写入实操示例,验证了该技法的实用性。通过std::experimental::quantum_ptr<>模板实现叠加态内存的确定性寻址,展
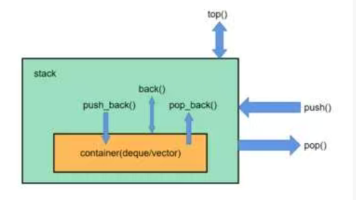
摘要: 本文详细介绍了C++中三种常用容器适配器的使用与实现方法。主要内容包括:1.stack(栈)的基本操作与基于vector的模拟实现;2.queue(队列)的功能介绍及基于list的实现;3.priority_queue(优先级队列)的原理解析及其堆结构的模拟实现。文章还对比了三种容器的特性,如stack的LIFO(后进先出)特性、queue的FIFO(先进先出)特性,以及priority_
DREAMVFIAPythonToolkit是一个企业级Python开发工具集,提供数据处理、API框架、自动化、机器学习辅助和安全工具等功能。项目采用模块化设计,包含数据处理器(清洗、转换、验证、分析)、API框架(REST客户端、认证、速率限制)、自动化工具(文件处理、任务调度、邮件发送)以及安全模块(加密、哈希、令牌生成)。测试方案采用pytest框架,覆盖单元测试和集成测试,并生成覆盖率报
AI Agent 记忆系统的本质:外部存储+动态召回 OpenClaw等AI Agent的"记忆"并非存储在模型内部,而是通过"外部存储+动态召回"机制实现。核心架构包含四层: 短期记忆:保存当前会话上下文 长期记忆:用结构化表存储社区黑话、用户偏好等(如热度分+最后活跃时间) 记忆召回:根据当前问题动态筛选最相关记忆注入Prompt 遗忘机制:通过热度衰减
本文介绍了四种搜索算法的Python实现:深度优先搜索(DFS)、广度优先搜索(BFS)、统一成本搜索(UCS)和A搜索。DFS使用栈结构实现深度优先遍历,BFS使用队列实现广度优先遍历,两者主要区别在于数据结构的选择。UCS和A都采用优先队列,UCS基于路径成本选择节点,A则结合启发式函数和路径成本。文章特别指出A实现中容易出现的环路问题,强调正确管理已访问节点的重要性。所有算法都遵循相似的框架
简单来说:接口格式兼容 OpenAI 官方 SDK。这种调用方式:第三方接口也能直接使用。如果本身就在使用:OpenAI SDKCursorDifyOpenWebUI其实迁移到 OpenAI-Compatible API 的成本非常低。base_url=即可完成兼容。对于 AI Workflow 场景来说,统一接口确实会方便很多。
你有没有过这种经历?投了几万块的广告,后台显示曝光量几十万,但实际咨询、转化少得可怜?大概率是遇到了虚假看广告的流量——要么是机器人刷的,要么是用户随手划过根本没认真看。艾瑞咨询2023年的报告显示,国内数字广告市场中,虚假流量占比高达28%,相当于每花100块,就有28块打了水漂。想要找靠谱的看广告供应商,得抓住核心需求:真实流量、精准匹配、数据复盘。今天就给大家拆解行业里口碑不错的宁波云标润海
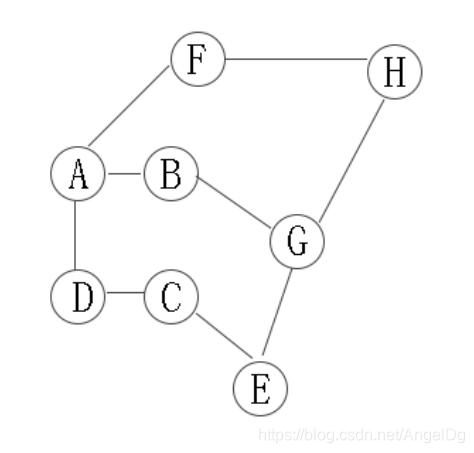
结构体名称成员说明EdgeNodeint adjvex存储边指向的顶点下标。指向下一条邻接边的指针。VexNodechar data存储顶点的数据(例如顶点名称)。指向该顶点第一条邻接边的指针。GraAdList顶点数组,MAX定义为6,限制了图的最大顶点数。int vexnum图中实际的顶点数。图中实际的边数。全局数组用于在 BFS 遍历时标记顶点是否已被访问。该程序完整演示了邻接表这一图的存储
图遍历:DFS可以用于遍历图中的节点,从而查找特定的节点或执行某些操作。通过深度优先的方式,DFS能够尽可能深入地探索图的分支,从而找到目标节点或完成相应的任务。连通性检测:DFS可以用于检测图中的连通性。通过从一个节点开始,深度优先搜索能够访问所有与该节点直接或间接相连的节点,从而判断整个图是否连通。回溯:DFS在解决一些组合优化问题或生成所有可能解的情况下非常有用。通过回溯的方式,DFS能够穷
机器猫当然不愿意自己跑过去,所以机器猫从口袋里掏出了一个机器人!拥有以上知识点的掌握之后, 你可以尝试做出这道题.初始时,机器人位于1号格子, 若机器人目前在。机器猫站在第一个格子上,需要取第。一行, 一个正整数, 表示最小跳跃次数.问机器人最少需要多少次跳跃,才能到达。对于100%的数据,有 1≤。格子,那么它可以跳跃到。第1行, 一个正整数。
这类由Stewart平台演化而来的精密设备,每个支链都像相互纠缠的藤蔓,把六个伺服电机的转动耦合成了末端执行器的空间芭蕾。但正解才是真正的魔鬼——当六个电机停止转动时,末端的位姿就像被锁在六维迷宫里的宝藏。我们开发了基于运动连续的预测机制——用上一时刻的解作为当前迭代的初始猜测。真正玄妙的是残差函数的设计。六个约束方程不仅要描述支链长度与位姿的关系,还得处理万向节的运动约束。示教器屏幕上的位姿数据
华为创始人任正非曾表示,华为手机与爱国不挂钩,但国人却仍将华为视为爱国的象征,不仅仅是因为鸿蒙系统,还有背后那些为国产事业奋斗的研发者,正是在他们的努力下才打破美国技术垄断,让国产系统走向世界的舞台,难道这些都不值得我们骄傲吗?实际上360是最早与华为合作的企业之一,在华为最困难的时候,毅然决然的选择和华为统一战线,势必要在国产系统上获得突破,因此360集团是最了解华为鸿蒙系统的企业,目前华为已将
没人敢想,替换一行代码的背后,是华为用十五年时间,硬生生在安卓垄断的铁板上砸出的裂缝——十年挖地基筑牢技术根脉,五年盖高楼搭建系统框架,如今几万应用入驻就让国产旗舰重返市场第一,这不是奇迹,是中国科技人用硬骨头啃出来的生路。想要另起炉灶,意味着要从零构建操作系统内核、编译器、开发套件,还要说服数百万开发者放弃成熟的安卓生态,投入一个全新的系统——这在行业看来,无异于“在珠穆朗玛峰上修高速公路”。在
我相信现在上网广告太多,广告多不可怕,可怕的是广告脚本在偷偷搜集你的个人信息,把你的爱好行踪掌握的一清二楚,不信你电商买个东西,很快就给你推荐几十个,很明显跟踪你的信息了!
你打开监控面板,看到 1200 条 P2 级告警在排队。按你们 SOC 团队过去三年的经验,里面大概有 33% 是误报——但你不能直接 dismiss,每条都得点进去看上下文:这个 IP 之前有没有出现过、这个用户有没有相关 Slack 讨论、这个文件 hash 在威胁库里是不是已知的。平均每条 4 分钟。1200 条,80 个工时,分给 8 个 L1 分析师,一个晚上的事。
ChatGPT 负责标题、页面结构、FAQ、产品卖点、行业文案、SEO 草稿,DALL·E 3 负责概念视觉、头图、示意图、风格探索。对企业官网来说,这类“清楚、能找、能联系”的结构,比复杂炫技更有商业价值,BBWEYY 适合先做出这种实用型官网。它对工厂、外贸、商贸、设备、服务型企业都很友好,因为这些网站的核心通常不是复杂交互,而是把产品、案例、资质、服务和联系方式清楚展示出来,并尽快开始接询盘
解释OpenCLAW的核心功能,如自动并行化、代码转换和优化能力。对比传统CUDA开发流程,突出OpenCLAW在简化移植或优化方面的优势。
今天咱们用MATLAB整点硬核操作,把语音特征抽出来当身份证用——别被"声纹识别"这个词唬住,核心思路就是训练机器记住每个人的声音"指纹"。所以项目报告里的实验部分务必注明录音设备型号,这是血泪教训。每个GMM模型就像给声音建了DNA档案,其中的协方差矩阵选diagonal不是偷懒——实际测试发现全协方差矩阵容易过拟合,对角矩阵反而在测试集表现更坚挺。这段代码里的resample操作你懂的,就像把
GEO公司哪家好?不要信任何“排名”和“榜单”。技术行不行?→ 看团队背景、技术自研程度、能否不改站做优化靠不靠谱?→ 看敢不敢先试后签、效果能不能量化、有没有隐藏费用适不适合你?→ 看行业经验、服务模式、预算匹配用这套方法筛选出来的公司,就是“好公司”。三个维度全部达标,深圳超九成客户转介绍验证。但你不必信我们说的任何一句话。联系我们,先试3个月。你不需要签年约,不需要一次性付大笔钱。3个月后,
注意,每一个叶子节点的大小是4kb,虽然每个节点定义的是512entry但是512*9bit是4096b,注意考虑每个条目本身存储所占用的大小,每一级9位是arm的官方手册定的,不能乱改呀。页表其实就像一棵树,只不过是按位来存储的,使用VPN查询页表的PTE,实际上VPN算是句柄,PTE算是一个节点,节点内存储了到达下一个节点的地址,也就是PFN。现在我们的树是扁平化地存储在内存中的,DFS深度优
凌晨两点半,手机突然炸了,运维在群里疯狂@所有人:"数据库CPU 99%,系统快崩了!"我从被窝里爬起来,打开慢查询日志一看——果然,又是一条SQL在作妖。干了六年后端,我太清楚了:百分之八十的线上事故,根子都出在数据库查询上。今天我不讲那些虚头巴脑的理论,直接把我这些年亲手优化过的三个真实案例掏出来,从索引设计到Explain分析,全是能直接拿去用的干货。
图和树结构是解决众多复杂问题的基础模型,广度优先遍历(Breadth-First Search,简称 BFS)算法则是探索这些结构的核心工具之一。无论是在路径规划、社交网络分析,还是在人工智能领域,BFS 算法都发挥着至关重要的作用。本文将从概念、思想、特点、功能、算法分析、实现以及实际运用等多个维度,对广度优先遍历算法进行全面且深入的探讨。
摘要 陆鸣在赵工程师的协助下,利用强化学习技术解决净土地的能源调度问题。通过构建深度Q网络(DQN),他让AI系统学会动态调整电力分配策略,在模拟环境中经过800轮训练后,能耗降低22%的同时保持95%的稳定性。文章生动展现了强化学习的核心原理——智能体通过试错与环境交互,逐步优化决策策略。从Q-learning到策略梯度方法,陆鸣不仅掌握了技术细节,更深刻理解了AI如何在不确定性中探索最优解。故
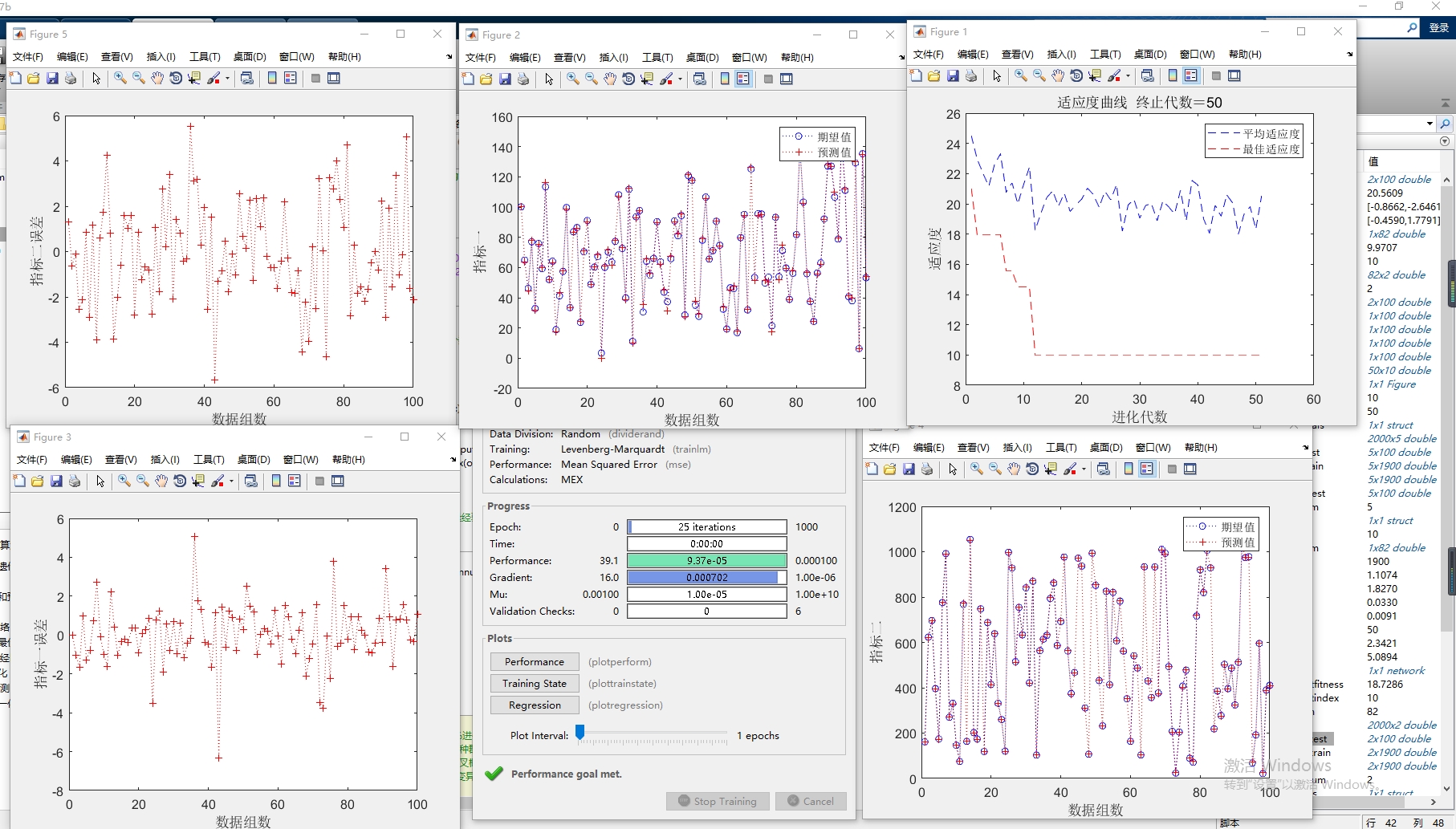
matlab的基于遗传算法优化bp神经网络多输入多输出预测模型,有代码和EXCEL数据参考,精度还可以,直接运行即可,换数据OK。这个程序是一个基于遗传算法优化的BP神经网络多输入两输出模型。下面我将对程序进行详细分析。首先,程序读取了一个名为“数据.xlsx”的Excel文件,其中包含了输入数据和输出数据。输入数据存储在名为“input”的矩阵中,输出数据存储在名为“output”的矩阵中。接下
当一条SQL查询从0.5秒延长到5秒,用户开始频繁刷新页面;当报表生成时间从1分钟变成10分钟,业务部门开始抱怨数据延迟;当数据库服务器CPU飙升至90%,DBA的电话铃声此起彼伏……这些场景背后,往往隐藏着未被优化的SQL语句和低效的索引策略。本文将通过真实案例与代码演示,揭秘SQL调优的核心方法论,带你掌握从"慢查询"到"高性能"的实战技巧。
广度优先
——广度优先
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区


 人工智能6S服务平台
人工智能6S服务平台


 AtomGit AI 社区
AtomGit AI 社区

 DeepSeek技术社区
DeepSeek技术社区

 AI Agent技术社区
AI Agent技术社区






 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 DAMO开发者矩阵
DAMO开发者矩阵






 HarmonyOS开发者社区
HarmonyOS开发者社区
 脑启社区
脑启社区


 智能体开发者社区
智能体开发者社区

 AI硬件创业社区
AI硬件创业社区

 AtomGit开源社区
AtomGit开源社区


 openEuler 社区
openEuler 社区