




- @lzm12278828
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
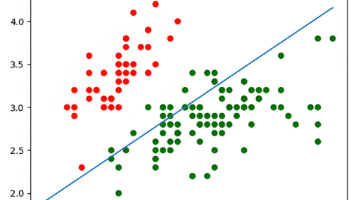
该数据集包含150个样本,分为3 个类别(山鸢尾Setosa、杂色鸢尾Versicolor、维吉尼亚鸢尾Virginica,各50个样本),每个样本描述了鸢尾花的4个特征:萼片长度(sepal length)、萼片宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)(单位均为厘米)。训练集是用于训练回归模型的,当训练好后,用测试集进行测试,看训练
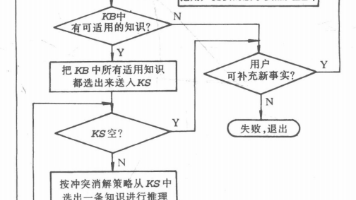
在逆向推理过程中,由于要与用户进行对话,有针对性地向用户提出询问,这就有可能获得一些原来不掌握的有用信息,这些信息不仅可用于证实要证明的假设,同时还可能有助于推出一些其它结论。此时为了得到一个可信度符合要求的结论,可用这些结论作为假设,然后进行逆向推理,通过向用户询问进一步的信息,有可能会得到可信度较高的结论。正向推理(Forward Chaining)是从已知事实(数据)出发,正向使用推理规则(
(2)归纳学习虽然是人们常用的一种学习方法,但由于它在学习中不使用领域知识分析、判断实例的属性,而仅仅通过实例间的比较来提取共性,这就无法保证推理的正确性,而基于解释的学习因在其学习过程中运用领域知识对提供给系统的实例进行分析,这就避免了类似问题的发生。: 设领域理论为 T(一组逻辑规则或知识库),训练实例为 (x, y),其中 x 是实例描述,y 是目标概念(如“可堆叠”“安全状态”)。解释构造
梯度消失通常发生在激活函数(如sigmoid或tanh)的饱和区域,导致梯度值非常小,使得参数更新变得非常缓慢。损失函数则根据这些预测结果和真实标签之间的差异来计算一个标量值(即损失值),该值表示了当前网络预测的准确性或误差大小。具体来说,它首先计算输出层损失函数关于输出层参数的梯度,然后通过链式法则逐层传递这些梯度,直到到达输入层。在多维空间中,梯度指向损失函数值增长最快的方向,而负梯度则指向损

单层感知器是一种最简单的神经网络形式,它包含一个输入层和一个输出层,没有任何隐藏层。Madaline可以用一种间接的方式解决线性不可分的问题,方法是用多个线性函数对区域进行划分,然后对各个神经元的输出做逻辑运算。线性神经网络解决线性不可分问题的另一个方法是,对神经元添加非线性输入,从而引入非线性成分,这样做会使等效的输入维度变大,如图4所示。在输出节点中的传递函数(激活函数)采用线性函数purel

它是通过从环境中取得若干与某概念有关的例子,经归纳得出一般性概念的一种学习方法。在这种学习方法中,外部环境(教师)提供的是一组例子(正例和反例),这些例子实际上是一组特殊的知识,每一个例子表达了仅适用于该例子的知识,示例学习就是要从这些特殊知识中归纳出适用于更大范围的一般性知识,它将覆盖所有的正例并排除所有反例。:设实例集合 S = {x_1, x_2, ..., x_n},每个实例具有属性 A,
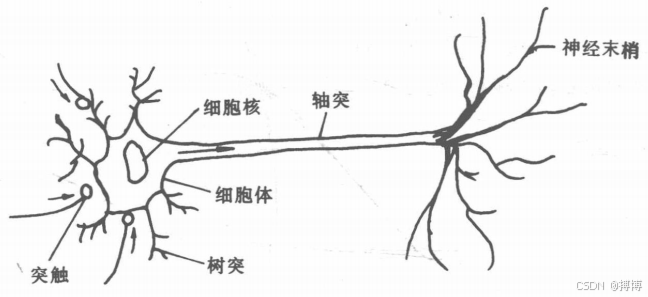
在无反馈的前向网络中,信息一旦通过某个神经元,过程就结束了,而在该网络中,信息可以在神经元之间反复往返地传递,网络一直处在一种改变状态的动态变化之中。θ为该神经元的阈值;人们在极短的时间内就可以对外界事物作出判断和决策,而且还具有很强的容错性及自适应能力,善于联想、类比、归纳和推广,能不断地学习新事物、新知识,总结经验,吸取教训,适应不断变化的情况等。在每一神经元中,信息都是以预知的确定方向流动的
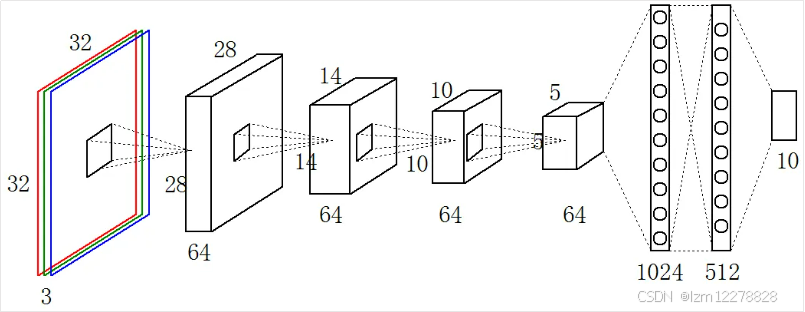
激活层负责对卷积层抽取的特征进行激活,由于卷积操作是由输入矩阵与卷积核矩阵进行相差的线性变化关系,需要激活层对其进行非线性的映射。激活层主要由激活函数组成,即在卷积层输出结果的基础上嵌套一个非线性函数,让输出的特征图具有非线性关系。图1中左边第一个图是32*32*3的三维彩色图像,彩色图像有三层,表示包含红R、绿G、蓝B三个通道。卷积神经网络(Convolutional Neural Networ
在这一阶段中,符号学习的研究也取得了很大进展,它与连接学习各有所长,具有较大的互补性。1980年他在卡内基-梅隆大学召开的机器学习研讨会上做了“为什么机器应该学习”的发言,在此发言中他把学习定义为:学习是系统中的任何改进,这种改进使得系统在重复同样的工作或进行类似的工作时,能完成得更好。在20世纪80年代,由于对智能机器人的研究取得了一定的进展,同时又出现了一些发现系统,于是人们开始把学习看作是从
命题逻辑和谓词逻辑是人工智能的重要数学基础。命题逻辑适合简单推理,而谓词逻辑能够更精细地表示知识并支持复杂推理。它们在知识表示、自动推理和专家系统中发挥着重要作用。
