登录社区云,与社区用户共同成长
邀请您加入社区
对于KMP的next数组求解,每个人都有每个人的理解和求法,掌握自己的那一种方法就可以。但是不是只需要写出代码那么简单,就像第二题,我们需要真正理解KMPnext数组的含义,才可以把这个方法移动到其他地方。本篇文章就到这里结束了!!!希望可以帮助大家理解~~~
只需这一篇文章,从零开始彻底理解KMP算法
移动开发领域跨平台开发方案介绍
哈希暴力法的枚举上限:由于允许循环节残缺,原串长度可能不足两个完整循环节(如abcdabc周期为4),因此枚举上限必须是len,绝不能写成len/2。KMP的0-base越界:获取全串最长前后缀必须是nxt[len-1]。在0-base中,写成nxt[len]会直接读取未知内存导致RE或WA。大数据量的I/O阻塞:本题字符串长度高达 10^6,如果不加cin.tie(0);,容易在读取长字符串时超
多组数据切忌滥用memset: 本题是多组测试数据,且最大长度达10^6。在KMP代码中,如果每读入一个字符串就,会引发海量的无用内存擦除,容易导致超时。因为pre()函数内部的for循环是严格基于索引逐个赋值的,会自动覆盖旧数据,因此无需清空。哈希匹配的内层break: 哈希校验时,一旦发现当前分块sum和基准块ans2不等,必须立刻将flag2置0并break出内层循环。若缺少此break,在
多组数据读入的阻塞陷阱题目规定以单个结束。很多同学习惯写。当最后一行只有一个时,s1会读入,而程序会阻塞等待s2的输入,虽然信息学奥赛一本题可以通过,但容易导致评测机卡死报超时。先读取s1探路,判断若为则立刻break,确认安全后再读取s2。KMP的Next 数组赋值位置在求next数组时,nxt[i]记录的是以索引i结尾的子串的最长公共前后缀长度。必须写成nxt[i]=j,切忌笔误写成nxt[j
public class kmp{static int KMP(String S,String T, int pos){if(S.length() < T.length()){return -1;}char[] s = new char[S.length()];char[] t = new char[T.length()];for(int k = 0;
这两天仔细的学了一下KMP算法,本来自己试着以自己的方式记录下自己的学习过程,但是写着写着便不知道自己在说什么了,不知如何组织自己的语言了。自己还是需要修炼,但是为了记录自己的学习过程,只好转载一篇July大神写的,原文链接地址:http://blog.csdn.net/v_JULY_v/article/details/6545192引言 在此之前,说明下写作本文的目的:1、之前
KMP 模式匹配详解通俗易懂KMP 模式匹配是解决字符串匹配的问题一、原始的字符串暴力匹配要点:子串的第一个字符匹配成功主串的字符后就依次匹配子串后面的字符,直到子串匹配结束代码:public static int forceMatch(char[] mainString,char[] pattern){int i = 0;int j = 0;//回溯的指针int k = 0;while (i &
这是一个KMPC++的模板。相信很对同学看了大佬超详细的讲解(本文有链接),但还是不太清楚next数组的意义,或者为什么next[0]=-1,而不是1。Kmp的时间复杂度为什么是线性的
目录【BF算法】【KMP算法】【拓展KMP】【前言】著名的模式匹配算法有BF算法和KMP算法,本文章主要着重讲KMP算法及其拓展。【BF算法】BF(Brute-Force)算法,是最简单直观的模式匹配算法。看下图,上边的是主串a,下边的是模式串b。分别用i,j做各自串的指针,若a[i]==b[j],i++,j++,继续比较;若不相等,i=i-j+2,j=1,重新开始...
tips:KMP其实本质并不复杂,我尽量用最简单的语句表达;另外,本人特别喜欢另一种更年轻高效字符串匹配算法——Sunday算法,感兴趣的可以前往查看该参考博文:https://blog.csdn.net/q547550831/article/details/51860017KMP作用:char *str = &amp;quot;bacbababadababacambabacadd
参考1简书:https://www.jianshu.com/p/18410598c061(DFA_KMP)参考2:https://segmentfault.com/a/1190000008575379(BruteForce、KMP)参考2原文:https://subetter.com/algorithms-and-mathematics/kmp-algorithm.html ...
next[]数组的定义:对于字符串s的第i个字符s[i],next[i]定义为字符s[i]前面最多有多少个连续的字符和字符串s从初始位置开始的字符匹配。
在KMP算法原理中,我们简要分析了KMP算法的原理,在直观上了解了算法流程,并分析了KMP算法之于暴力算法的效率提升之处。这里我们就从暴力算法出发,根据算法基本流程一步步实现典型的KMP算法。文中出现的名词:模式串(pattern,P),长度为m,当前字符指针i文本串(text,T),长度为n,当前字符指针j1.暴力算法(BF)暴力算法的是最直接的匹配算法,分别
KMP算法求next数组和nextval数组方法总结首先next数组,以下是天勤给出的求解步骤FL为从左边第一个字符起的字串FR为从右边第一个字符起的字串如果没理解可以看下面的例子例如模式串为123456...
原文地址:http://www.cnblogs.com/SYCstudio/p/7194315.htmlKMP算法(研究总结,字符串)前段时间学习KMP算法,感觉有些复杂,不过好歹是弄懂啦,简单地记录一下,方便以后自己回忆。引入首先我们来看一个例子,现在有两个字符串A和B,问你在A中是否有B,有几个?为了方便叙述,我们先给定两个字符串的值A=”abcaabababaa”B=”abab...
KMP算法的改进KMP算法已经在极大程度上提高了子符串的匹配效率,但是仍然有改进的余地。1. 引入的情景下面我们就其中的一种情况进行分析:主串T为"aaaabcde…"子串S为"aaaade"那么容易求得子串的next[]={0,1,2,3,4}下标12345子串aaaadnext01234当使用KMP算法进行匹配时,由于T[5]!=S[5], 因此子串指针回溯,子串回溯后变为T[5]与S[4]的
本文介绍了KMP算法的基本原理和实现方法,重点讲解了Next数组的求解过程和失配回溯机制。Next数组是KMP算法的核心,它记录了模式串的最长公共前后缀信息,用于优化字符串匹配的效率。本文分析了三种常见的Next数组求解情况,并给出了相应的示例和图解
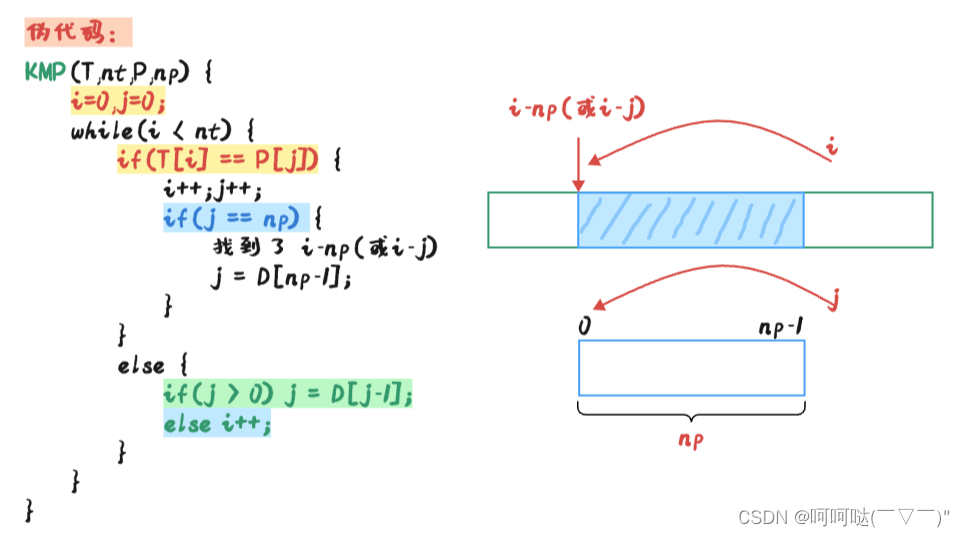
我们从刚刚已经计算好的 D数组(记录最大公共前后缀的长度)里发现,D[3]表示这前四个字母A所对应的最大公共前后缀的长度为3,P串拥有的最大公共前后缀也是3,可以看标注的串③ 和 串④;,它也是在做向前探索,可以去找一些复杂的例子感受一下,j是如何往前移动的,它可能不是一口气就移动到该去的位置的,它需要多次移动。如果说在匹配的过程中,在某个时间点,此时 i 指向的字符是 x ,j 指向的字符是 y
1.KMP介绍1.1什么是KMP之所以叫KMP是为了纪念发明者,分别为:Knuth,Morris和Pratt1.2KMP有什么用KMP主要是应用在字符串匹配上。KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前匹配的文本内容,可以利用这些信息避免从头再去做匹配。2.前缀表的介绍2.1什么是前缀表写KMP时用到的next数组就是前缀表。前缀表是用来回溯的,它记录了模式串与主串(文本串)不匹配
AI 驱动开发是 Kuikly2026 年的核心方向——我们希望将 AI 能力深度融入研发全链路。围绕这一方向,我们沿着客户端开发的各个环节逐一推进,实践了 Harness 开发并沉淀了工具,相关能力已在司内多条业务线落地,并显著提升了研发效率。现在,我们正式开源首批 AI 能力:Rules 与 Skills,诚邀各位开发者体验与协作,项目地址:https://github.com/Tencent
设主串T为'abaabaabcabaabc',模式串S为'abaabc'。采用KMP算法进行匹配,到匹配成功时为止,在匹配过程中进行的单个字符间的比较次数是多少次?由于第一次匹配 第6个字符不匹配(移动位数=已匹配的字符数-对应的部分匹配值(对应匹配字符的长度)下标)前面的ab不需要匹配了所以不算次数。第三次匹配 后面的 abc依次匹配 3次,一共得 6+1+3=10。得到 已匹配的字符数为5,对
腾讯自研、基于 Kotlin Multiplatform 的企业级跨端框架,原生渲染 + 原生动态化,是 Flutter 在高性能动态化场景下最具竞争力的替代方案。Flutter 的核心问题是"动态化"与"性能"难以兼得——要动态化就得走 JS,要性能就得放弃动态化。:需要高性能原生体验 + 动态化能力的企业级 App,尤其适合已有 Kotlin/Android 团队、需要覆盖鸿蒙平台的项目。ma
● 题目给数字序列,就用数组 /vector<int>,绝对不要用命令 to_string(x) 转字符串!转字符串 = 必错 + 必超时。
● 当 i%(i-next[i])==0 时,存在循环节。循环节长度 L=i-next[i],循环次数 K=i/L=i/(i-next[i])。
KMP(Kotlin Multiplatform)是谷歌开发的跨平台架构,旨在解决多平台应用开发中的重复工作问题。传统开发需要为Android、iOS等不同平台分别编写业务逻辑和UI,而KMP允许将共享代码(如业务逻辑)放在commonMain中,平台差异部分通过expect/actual机制实现(如PlatformButton在不同平台的UI实现)。官方Demo展示了如何用expect声明通用接
跨平台开发长期面临“一次编码、多端运行”的理想与现实落差。开发者常陷入取舍困境:既要兼顾性能与体验,又要控制包体与维护成本,更要在 Android、iOS、HarmonyOS 甚至 Web 和小程序间保持一致。实际项目中,常见坑包括启动延迟、渲染卡顿、多端差异修复成本高、动态化能力受限等,这些都直接影响交付效率与用户留存。
面对多端并存与生态碎片化的挑战,行业转型方向愈加清晰——需以统一底座降低多端研发复杂度,以原生能力保障体验一致,以动态化提升迭代敏捷度。Kuikly已在社交、音乐、资讯、输入法、直播等多领域实现标杆落地:在QQ体系支撑亿级日活的多端一致体验,在搜狗输入法实现鸿蒙与AI工程化双突破,在直播业务完成从Flutter到KMP+Kuikly的无缝迁移,在AI代码生成场景建立可复用的工程化路径。这些跨行业、
在移动与智能终端生态日益分化的背景下,Android、iOS、HarmonyOS 各自维护独立的运行环境与开发规范,导致应用在多端发布时面临接口不一致、渲染机制差异、生态能力接入困难等问题。本篇结合官方文档、开源社区实践与可验证资料,围绕跨平台开发从框架选型到工程优化进行系统化梳理,提供可落地的方案与代码示例,帮助开发者在不同业务场景下作出务实决策。低端设备易出现帧率波动。基类的扩展模块,各平台宿
AI能翻译代码,跨平台框架还有必要吗?KMP崛起、Flutter焦虑、RN衰退,2026年跨端技术选型的真实判断
KMP
——KMP
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 EazyDevelop社区
EazyDevelop社区




 腾讯云开发者社区
腾讯云开发者社区
















 龙虾开发者社区
龙虾开发者社区

 人工智能6S服务平台
人工智能6S服务平台


 AtomGit开源社区
AtomGit开源社区

