登录社区云,与社区用户共同成长
邀请您加入社区
本文介绍了KMP算法及其扩展应用。主要内容包括: KMP算法通过预处理模式串生成next数组,利用已匹配信息避免回溯,将字符串匹配优化至线性时间复杂度O(n+m)。文章提供了KMP模板代码实现。 扩展KMP(Z函数)用于求解模式串与文本串每个后缀的最长公共前缀,给出了算法定义和实现模板。 简要提及马拉车(Manacher)算法(未详细展开)并附模板代码。 通过经典例题展示KMP应用,如利用lps数
本文探讨了二元线性逻辑与灰度混沌逻辑的适用边界,指出将工具化的二元思维套用于生命、意识等复杂系统会导致认知偏差。生命本质是持续流变的灰度系统,人类心智具有多元共存性,而无限时空中的庞加莱回归意味着多重可能性同步存在。时间在局部视角存在,但在全域层面消解。作者提出分层认知范式:底层保留二元逻辑保障算力效率,上层采用汉语柔性语义构建灰度认知系统。这一架构通过语义桥接层实现信息转换,使人工智能既能高效执
系统讲解一套生产级评估体系是怎么运转的。文章覆盖七大主题:EvalEnvironment 生命周期(prepare/dispose SPI、每个 trial 独立 workspace/clock/controller/lease)、Record/Replay 机制(录制真实 LLM 交互、回放时 HTTP 请求严格为 0)、SHA-256 请求哈希(canonical JSON + trial s
参考代码运行结果uthash头文件
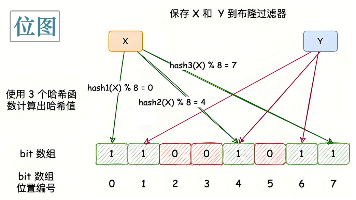
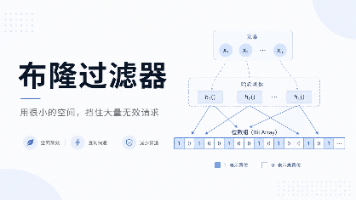
布隆过滤器是一种高效的空间节省型数据结构,主要用于判断元素是否可能存在于集合中。它通过位图和多个哈希函数实现,能在极小内存(如1MB拦截百万级请求)下快速过滤无效查询,避免缓存穿透问题。其核心特点是:若判断不存在则一定不存在,若判断可能存在则需进一步确认(可能误判)。误判率可通过调整位图大小和哈希函数数量控制,适用于大规模数据的存在性检查场景,显著降低数据库压力。
HarmonyOS NEXT 网络套接字开发指南 本文介绍了 HarmonyOS NEXT 中的网络套接字开发,重点讲解了 TCP 和 UDP 协议的使用方法。 核心内容 环境准备:需要使用 @ohos.net.socket 模块并声明 ohos.permission.INTERNET 权限。 TCP 套接字: 生命周期:创建实例 → 连接服务器 → 注册数据监听 → 发送数据 → 关闭连接 关键
本文介绍了HarmonyOS NEXT中的密码学工具箱开发实践,重点讲解cryptoFramework模块的核心功能和使用方法。主要内容包括: 密码学基础支持:涵盖消息摘要(Hash)、对称加密(AES)、消息认证码(HMAC)、非对称加密(RSA)等安全功能,无需权限即可使用。 核心数据结构DataBlob:作为所有密码操作的输入输出容器,实现字符串与二进制数据的转换。 消息摘要算法:详细对比7
1.7的put操作是头插入的。两个线程同时put并且resize的时候会出现环形链表的情况,所以get操作会出现死循环。遍历时(get)执行删除操作(remove)会抛出这个异常,这叫做fast-fail机制。resize中有个transfer,需要把旧数组中的所有元素转移到新的数组中。put操作中判断key为NULL的时候,会调用putForNullKey。不是计算Hash后对table.len
本文基于JDK 1.8源码深度解析HashMap的get/put核心流程。HashMap采用数组+链表+红黑树混合结构,通过扰动函数(h=hashCode())^(h>>>16)优化哈希分布。put流程包含哈希计算、桶定位、树化判断(链表≥8且容量≥64时转红黑树)、尾插法插入及扩容迁移(高低位拆分避免rehash);get流程通过(n-1)&hash定位桶后,按链表遍历或红黑树搜索(O(log
Java HashMap 扩容数组中单链表的位置变化分析
Python中的集合与字典是两种重要的数据结构。集合分为可变集合(set)和不可变集合(frozenset),支持丰富的集合运算(并集、交集等)。字典(dict)是键值对映射结构,键必须是可哈希类型,提供高效的查找功能。两种结构都支持多种创建方式(构造函数、推导式等)和常用操作(增删改查)。字典还支持视图对象、合并操作等特性,在数据存储、配置管理、频率统计等场景有广泛应用。
HashMap 继承了AbstractMap,实现了Map接口,HashMap是根据key-value来存储数据的,HashMap其实就是一个数组+链表+红黑树组成的。因为HashMap在存储数据的时候,会先去计算key的hash值,因为一个相同的key值,所得的hash值应该是唯一的,所以我们可以很快的去定位到value的值。HashMap允许key和value都为null,但是key只能有一次
这两个问题其实有很多解决办法,这里使用了一种简单的办法,给每个真实结点后面根据虚拟节点加上后缀再取Hash值,比如”192.168.0.0:111”就把它变成”192.168.0.0:111&&VN0”到”192.168.0.0:111&&VN4”,VN就是Virtual Node的缩写,还原的时候只需要从头截取字符串到”&&”的位置就可以了。通过采取虚拟节点的方法,一个真实结点不再固定在Hash
password_hash() 函数用于创建密码的散列(hash)PHP 版本要求: PHP 5 >= 5.5.0, PHP 7。
pycryptodome是一个功能强大的Python密码学库,支持AES、RSA等多种加密算法,提供哈希计算、数字签名等功能。该库具有高性能C语言实现、安全默认参数和跨平台兼容性,适用于网络安全、数据保护等场景。文章介绍了其安装方法,并演示了对称加密(AES)、哈希算法(SHA)、随机数生成等基础功能,以及RSA加密、数字签名等高级应用。通过用户密码存储和文件加密的实际案例,展示了该库在提升系统安
摘要: JDK 8对HashMap进行了六大核心优化: 红黑树优化:链表长度≥8且数组≥64时转为红黑树,查询从O(n)降至O(logn); 哈希算法改进:高位参与运算,减少20%碰撞概率; 插入方式:头插法改为尾插法,解决并发扩容死循环问题; 扩容优化:节点位置通过位运算快速确定,性能提升30%+; 函数式API:支持Lambda表达式简化操作; 并发安全改进:尾插法消除链表成环风险(仍需Con
int x, y;// 哈希函数需要重载 std::hashreturn 0;特性底层哈希表查找O(1) 平均,O(N) 最坏是否排序❌ 无序Key 唯一性✅ 唯一适合场景高速查找 / 快速插入 / ID 映射Key 类型限制若是自定义类型,需重载==和std::hash。
本文总体介绍了哈希表的 概念与具体内容;以及C++11的无序式哈希容器:包括unordered_set、unordered_map、unordered_multiset、unordered_multimap的概念与具体代码实现。
不在。
C++题解P2288家谱问题的解法,核心在于通过哈希处理字符串实现并查集操作。将字符串转换为唯一编号后,使用并查集维护家族关系。哈希函数采用字母ASCII值作为T进制位,通过取模运算确保唯一性。代码实现了字符串哈希、并查集查询合并等操作,处理'#'、'+'、'?'三种指令分别对应设置祖先、合并集合和查询祖先功能。该方法避免了map的高时间复杂度,通过数组直接存储字符串与编号的映射关系,提高了查询效
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到log₂N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。
在C#编程中,集合是存储和操作数据的重要工具。本文将详细介绍C#中最常用的哈希集合和字典类型,通过简单易懂的例子帮助理解它们的使用方法和底层原理。哈希是一种将任意长度的数据转换为固定长度数值的算法。在集合中,哈希用于快速定位数据位置。通俗理解:哈希就像是给每个东西分配一个唯一的"房间号码",把复杂的东西转换成简单的数字编号,方便快速找到它。想象一个图书管理员,图书馆里有100个房间(0-99号)。
Java:实现DoubleHashing双哈希测试算法(附带源码)
Java:实现使用双哈希作为冲突解决技术的哈希表算法(附带源码)
Java:实现支持任何哈希函数的通用bloom过滤器算法(附带源码)
这么好的事,不点一下试试?
HashMapunordered_map哈希表——遍历无序HashSetunordered_set单向迭代器增删查效率O(1)Map红黑树——中序遍历有序Set双向迭代器增删查效率O(logN)哈希又称散列(hash),是一种组织数据的方式,本质是通过哈希函数把关键字Key根存储位置建立一个映射关系查找时通过这个哈希函数计算出Key存储的位置,进行快速查找一、开放定址法。
Python 字典(dict)之所以查询效率非常高(平均时间复杂度为),主要归功于其底层实现——。
java-NC321 连续数组的长度。
优先用数组:当元素是整数且范围有限时(空间和速度最优)。优先用Set:只需去重或判断存在性,无需额外信息时。优先用Map:需要存储键和对应的值(如索引、次数)时。
哈希值是通过哈希算法计算出的固定大小的数值,常用于对象的快速比较、字典键查找和集合成员检测等场景。float('nan') 是不相等的自身,但在同一次 Python 运行期间它的哈希值是可用且固定的,不过不同 Python 会话之间,这个哈希值可能不同(受哈希随机化影响)在 Python 3.3 及以上版本,字符串、字节序列等的哈希值会因会话不同而变化,以增强安全性(防御哈希攻击)。由于哈希随机化
但是第二种方法对内存的要求太高,1G约等于10亿Byte,1G可存10/4个int,40 / (10 / 4)还是使用位图,开两个42亿9000万个比特位的空间,第一个代表2^1,第二个代表2^0。,10代表出现两次及以上,00代表未出现,01代表只出现一次,因此对位图进行封装就。因此大约需要16G,但是因为空间太大,只能将这些数放在硬盘中,而二分查找只能处理内存。3、一个文件中有100亿个整数,
哈希冲突发生时,查询元素entry1的过程取决于冲突解决方法。链地址法通过遍历桶3的链表查找entry1,时间复杂度可能从O(1)退化到O(n)。开放地址法则按探测序列(如线性探测)在后续桶中搜索,Python的dict采用类似方法自动处理冲突。实际使用中,直接通过my_dict[entry1]即可获取值,无需关心底层实现。两种方法都能有效解决冲突,但开放地址法(Python默认)通常更高效,尤其
Map 接口是 Java 集合框架中非常重要的一员,位于java.util包下。它提供了一种键值对(Key-Value)的存储方式,用于存储具有映射关系的数据,允许通过键(key)来高效地查找对应的值(value)。这种数据结构在编程中非常常见,特别适合需要快速查找和检索的场景。TreeMap 是基于红黑树(Red-Black tree)实现的有序映射集合,它默认会按照键的自然顺序(natural
本文整理了6道编程题解,涵盖数字统计、数组交集、快递费用计算、字符串消除、动态规划和字符串处理等算法问题。1. 统计区间内数字2的出现次数;2. 找出两个数组的交集元素;3. 计算快递费用,考虑重量和加急情况;4. 模拟栈实现相邻字符消除;5. 动态规划求解爬楼梯最小花费;6. 将输入单词的首字母转为大写。每道题都给出了核心代码实现,适合编程练习和算法学习。
在这个示例中,我们使用了Dictionary来实现哈希查找算法。首先,我们遍历数组,将数组元素作为键,元素在数组中的索引作为值,存储在Dictionary中。然后,我们可以通过目标值在Dictionary中查找其索引,如果存在则返回索引,否则返回-1表示未找到。C#实现哈希查找算法。
本文讨论了LeetCode 128题"最长连续序列"的两种解法。第一种使用C++的map,时间复杂度为O(n log n),通过排序和遍历统计连续序列长度。第二种使用unordered_set实现O(n)时间复杂度,通过检查每个可能的序列起点并扩展。Python和Java也提供了类似unordered_set的解法,利用集合快速查找特性,确保线性时间复杂度。关键点在于避免重复检
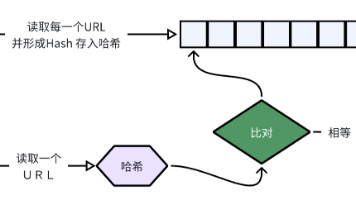
本文摘录了四个技术问题的解答: 哈希表原理与哈希函数设计:通过哈希函数将键映射到数组下标实现快速查找,设计哈希函数需考虑均匀分布和冲突处理。 大文件URL去重:通过哈希分片将大文件拆分为小文件,再逐块比较相同哈希值的URL。 vector的resize与reserve区别:resize改变元素数量(size),可能影响容量(capacity);reserve仅预分配内存空间,不影响size。 满二
摘要: HashMap是Java集合框架中基于哈希表实现的Map接口,允许空键和空值,非线程安全。其性能受初始容量和负载因子影响,默认负载因子0.75平衡了时空开销。查找操作(get/put)时间复杂度为O(1),迭代性能与容量和大小相关。当条目数超过容量×负载因子时会自动扩容为两倍。建议预先设置合理初始容量以减少rehash。迭代器采用快速失败机制,并发修改会抛出ConcurrentModifi
tuple() 用于创建不可变的元组对象。它既可以将可迭代对象转换为元组,也可直接创建一个空元组,在数据不可变性要求较高的场景中非常实用。虽然元组本身不可变,但如果元组中包含可变对象(如列表),这些对象内部的内容仍可修改。当且仅当元组中所有元素都是可哈希对象时,元组才是可哈希的,可作为字典键或集合成员。如果需要将键值对转换为元组,应使用 tuple(d.items())。任意可迭代对象,如列表、字
以其独特的"身份校验"特性,在对象缓存、实例追踪等场景中发挥着不可替代的作用。其底层基于线性探测的实现,虽然在高冲突场景下性能受限,但通过内存紧凑性和简单逻辑,满足了特定场景的需求。对于资深工程师而言,掌握不仅需要理解其与HashMap的差异,更要能在实际项目中精准判断适用场景——当业务逻辑依赖对象身份而非值相等时,它是最优解;而在常规场景下,过度使用则会引入不必要的复杂性。
WeakHashMap通过弱引用与引用队列的结合,实现了键值对的自动清理,为临时数据存储提供了优雅的解决方案。但其特性也带来了独特的注意事项:需避免值引用键导致的内存泄漏,理解size()方法的非精确性,以及在高并发场景下的线程安全问题。对于资深工程师而言,掌握WeakHashMap不仅是应对面试的必备技能,更能在缓存设计、资源管理等场景中做出更合理的技术选型——既不过度依赖手动清理,也不盲目相信
Python 分布式系统构建:一致性哈希与服务发现实践 摘要 本文介绍了如何在Python中实现分布式系统的关键组件:一致性哈希和服务发现。一致性哈希算法通过哈希环和虚拟节点技术,显著减少了节点变更时的数据重分配开销;服务发现机制则实现了动态节点注册与健康检查功能。文章提供了基于asyncio的高性能异步实现方案,包括核心哈希环逻辑、服务发现集成、故障处理机制以及性能优化策略。通过完整的代码示例和
它与 set 类似,但一旦创建,其元素就不能被添加、删除或修改,因此可以作为字典的键或其他集合的元素。3、在多线程或需要数据安全的情况下,可以用 frozenset 替代 set,防止被意外修改。1、创建 frozenset 的时间复杂度与 set 相同,取决于输入数据的长度。3、frozenset 可以作为字典的键或其他集合的元素,而 set 不可以。frozenset 可以作为字典的键或其他集
JAVA:实现HashMap哈希映射底层算法(附带源码)
JAVA:实现HashMap线性探测算法(附带源码)
用 Python+Qt 打造“波场哈希分分彩”:实时多模型预测结果
哈希算法
——哈希算法
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 EazyDevelop社区
EazyDevelop社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 人工智能6S服务平台
人工智能6S服务平台


 AMD开发者中国社区
AMD开发者中国社区




 AI Agent技术社区
AI Agent技术社区