登录社区云,与社区用户共同成长
邀请您加入社区
本文从 Schema 理解、意图识别、SQL 生成、结果验证和 Agent 工作流角度,分析大模型与数据库结合的演进路径。
本文结合 Chat2DB 实战,梳理从 ChatGPT 写 SQL 到专业 AI 数据库工具的工作流,重点讨论智能问数、Schema 感知、SQL 审核和团队安全边界。
undefined
本文介绍了一款面向企业核心业务场景的"掌握能力"级任务型智能体。该智能体采用意图识别+实体识别模式,支持精细化权限控制,具备两大核心功能:智能问数(自动识别用户查询意图并展示数据表格及分析结论)和流程发起(引导用户完成业务流程)。技术架构上实现了对话框表格展示、动态WebAPI调用等创新机制,并配套提供提示词配置、意图管理和服务记录查询等运维功能,有效支持企业核心业务的AI化改
夜里十一点,办公区只剩下报表团队的灯还亮着,屏幕上排满了各种复杂表格与冗长 SQL 语句,报表工程师们仍紧锁眉头,埋头制作着一个个报表而仅一墙之隔的开发团队区域,早已人去灯熄,曾经常年加班、被称为“公司守夜人”的他们,自从用上 AI 编程助手后,不仅效率翻倍,下班时间也变得越来越早只有报表团队的键盘声,在寂静的夜里显得格外清晰“如果报表开发也有 AI 助手就好了,”这个念头不止一次出现在报表工程师
还在为找数据、写 SQL 头疼?OntoFlow 本体建模平台的元数据探查功能来了!本文拆解其核心能力:兼容全品类数据源、可视化盘点数据资产,更能用自然语言直接 “问数”,同时结合元数据管理引擎与 Palantir 前沿实践,看它如何打通数据到知识的链路,让企业数据真正 “活” 起来。
图表数据新增标签显示机制,支持MySQL SSL安全连接。
从这个角度看,UINO 这类基于本体论的方法,至少说明一件事:国内智能问数并不一定只能停留在“自然语言转 SQL”这条路线,也开始有人尝试把问题提升到“对象—关系—指标—计算”的业务语义层去解决。因为未来企业真正需要的,很可能不是一个“会回答问题的机器人”,而是一个“能理解业务对象、能调用知识、能执行分析、还能衔接动作”的智能体。对于单表查询、结构清晰、口径稳定的问题,它当然有意义。也就是说,企业
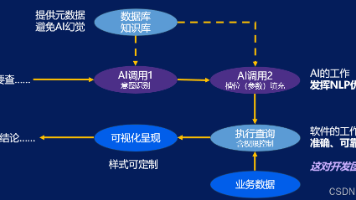
自然语言处理(NLP)与数据库查询的结合,正通过大语言模型(LLM)的语义理解能力,将非结构化的用户问题转化为精确的结构化查询语言(SQL)。其核心原理在于利用向量化检索与上下文学习,实现从业务术语到数据表字段的精准映射。这一技术的核心价值在于大幅降低数据查询与分析的门槛,让业务人员无需掌握SQL语法即可直接获取数据洞察,从而提升企业数据驱动决策的效率与敏捷性。其典型应用场景包括企业内部的业务自助
AI 时代,到处都在说“智能问数”,用大白话直接问,数据就给你整得明明白白。理想很美好,可真要一探究竟,大家心里就打了鼓:这玩意儿是不是得养个 AI 科学家团队?是不是得买几十上百万的 GPU 服务器?查出来的数要是不准,谁敢拿来做决策?别急,润乾 ChatBI 带来了一条不同的路——一条让中小企业、普通开发团队都能轻松上车、用得安心、花得明白的路。不依赖“黑盒”大模型去猜,而是用一套清晰的“规则
如果你也被文档数据处理效率低、多格式文件无法统一分析、统计计算繁琐困扰,今天这款 Langflow 官方预置模板 ——**CSV Query Assistant(自动化文档分析助手)** 能彻底解决痛点:可视化拖拽搭建、支持多格式文件上传、自然语言提问、内置计算器自动完成统计运算,几乎零代码就能搭建专属数据智能分析流水线。
MCP服务功能增强,数据源支持自定义数据类型。
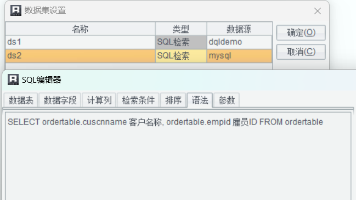
上图中我们配置了deepseek的API接口地址,配置了模型为deepseek-chat模型,以及最大token量等参数,并将自己的APIKey填入deepseek.txt文档,放在WEB-INF目录下。目前汉语查询功能采用了小型的规则引擎,还不能识别非常灵活的口语命令,比如当我们使用“查询上周发货到华北的订单”等口语化描述查询数据时,规则引擎无法理解就会报错。我们的参数模板有控件雇员ID,显示值
AI 一天不解决幻觉问题,这个步骤就不可能 100% 可靠。这些手段都只能减少幻觉,不能根除幻觉。学术界的研究已经给出了令人警惕的证据。在真实企业数据环境下的 Spider 2.0 基准测试中,曾在 Spider 1.0 上达到 86% 准确率的 GPT-4o,在 Spider 2.0 上的整体成功率骤降至。
思迈特软件基于长期行业实践,持续积累普遍适用的分析指标、业务维度和方法体系,并逐步沉淀为上千个行业 Know-how,让 AI 不只是回答问题,更成为可使用、可验证、可持续进化的企业级能力。围绕企业真实数据分析流程,白泽 V5 将简单查数、归因分析、多源融合、仪表盘创建、分析报告生成和智能填表等能力,组织成一条从提问到分析、再到成果交付与结果复核的完整链路。比如,在分析报告生成后,系统不仅输出最终
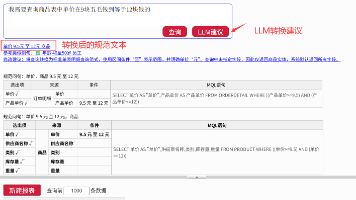
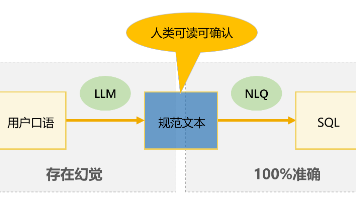
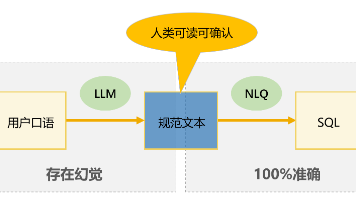
润乾NLQ提出了一种创新的Text2SQL解决方案,通过规范文本作为中介语言实现100%准确率。其核心在于将自然语言查询先转换为规范文本(如"去年上半年签单客户"),再通过规则引擎确定性地编译为SQL,避免了传统大模型直接生成SQL的不稳定性。该方案采用DQL语义层处理多表关联,支持单表明细、单表聚合等四种查询范式,覆盖大部分BI场景需求。配合LLM可将口语转换为规范文本,同时
本文介绍了SQLBot的部署与集成方法。部署部分提供了两种Docker部署方案(命令行和Compose),强调需配置SERVER_IMAGE_HOST参数并开放8000/8001端口。集成方面详细说明了MCP工具的mcp_start和mcp_question接口用法,以及如何与MaxKB4J平台对接,包括创建智能体模板、配置MCP工具参数等步骤。部署成功后可通过8000端口访问,默认账号admin
赛事聚焦新一代信息技术、人工智能、新能源等8大前沿领域,严选103个榜题,并在相关领域产业链较为完整、产业发展较为集聚的8个城市(区)分领域设立主擂台,打造集科研攻关、成果展示、行业交流、项目孵化于一体的国家级科创平台。,该产品以多智能体协同与 ReAct推理架构为核心,可实现自动归因分析、智能报告生成与零门槛仪表盘构建,依托统一指标底座与多源数据融合能力,兼具高准确性、高安全性与私有化部署优势,
过去两年,无数推进过AI数据项目的团队都经历过这个时刻——有的卡在Demo阶段,有的走得更远:项目立项、场景验收、系统上线,然后交给更多用户去用,才发现很多问题根本回答不了,和当初期望的差了十万八千里。这正是SmartBI白泽做的事,不是又一个AI问数工具,而是一套为企业数据决策场景专门搭建的Harness——语义层、执行层、治理层、交付层,四层协同,缺一不可。有了这层,"上个月华东区净利润同比"
对于智能问数而言,最核心的成熟度分水岭,通常不在“大模型能不能回答”,而在企业是否已经具备可持续的数据语义治理、指标治理和跨系统连接能力。
本文系统探讨了ChatBI在企业智能化转型中的定位与价值。通过"祛魅三部曲"破除对ChatBI的过度神化后,提出其应定位于"副驾驶"式的AI辅助角色,而非决策主导者。研究聚焦企业中坚力量的数据困境,揭示ChatBI在需求澄清、分析引导和文化培育三方面的核心价值:作为"教练"培养分析思维,作为"挖掘机"提炼真实需求,作为
造 Agent 越来越容易,但壁垒不在模型,在数据语义层。养虾热闹,虾能不能活取决于水质。
这种以“语义”为牵引、以“自动化”为支撑的治理范式,标志着数据治理从“成本中心”走向“价值引擎”的关键跃迁,为企业在数据洪流中构建高效、可信、敏捷的数据赋能体系提供了全新范式。企业可以考虑设立专门的“语义架构师”角色,其核心职责是统筹业务术语的标准化、语义模型的设计与维护,充当业务需求与技术实现的“翻译官”与仲裁者。数据治理是企业级的管理体系,其核心在于确保数据的可用性、一致性、完整性、安全性与合
智能问数
——智能问数
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AtomGit AI 社区
AtomGit AI 社区

 AI Agent技术社区
AI Agent技术社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 DAMO开发者矩阵
DAMO开发者矩阵



 脑启社区
脑启社区
 openEuler 社区
openEuler 社区

 EazyDevelop社区
EazyDevelop社区
 MCP技术社区
MCP技术社区


 CSDN-OPC开发者社区
CSDN-OPC开发者社区

 AtomGit开源社区
AtomGit开源社区



 2048 AI社区
2048 AI社区

 龙虾开发者社区
龙虾开发者社区







 魔乐社区
魔乐社区
