登录社区云,与社区用户共同成长
邀请您加入社区
大模型边缘推理面临显存瓶颈、低延迟要求与软硬协同复杂性等共性挑战。其核心原理在于高效管理KV Cache内存、降低跨卡通信开销,并依托深度定制的推理引擎实现可观测性与可控调度。技术价值体现在国产硬件上达成可预测的稳定性与能效比,支撑智能客服、工业质检等实时敏感场景。典型应用需兼顾HBM2e显存特性、MindIE日志调试能力及ATC模型转换规范。本文聚焦Atlas 300I Duo在70B级模型落地
本文详细介绍了在昇腾AI环境下的Qwen3-32B大模型部署流程。首先配置系统内核参数并安装Docker及Compose工具,然后下载华为MindIE推理引擎镜像和魔塔社区的Qwen3-32B模型。部署过程包括创建目录结构、修改模型配置、导入镜像等步骤,重点配置了mindie-service的各项参数,包括服务端口、安全证书、NPU设备分配等。最后设置了模型部署参数,如最大序列长度2048、世界大
本文详细介绍了如何使用昇腾MindIE服务化框架部署Qwen2-7B大语言模型,实现高并发API服务。从环境配置、模型准备到核心参数调优,再到RESTful API设计和性能优化,手把手教你搭建生产级推理服务,解决实际部署中的性能瓶颈和安全问题。
本文详细介绍了MindIE与vLLM框架的深度集成实践,包括环境配置、安装部署、模型推理及性能调优。通过结合MindIE在昇腾芯片上的优化能力和vLLM的高效服务框架,显著提升大模型推理性能,适用于多种AI应用场景。
本文全面解析了华为昇腾推理引擎MindIE的应用实践,从模型迁移到高效推理的全流程。通过MindIE-Torch组件,开发者可快速将PyTorch模型迁移至昇腾平台,显著提升推理性能。文章详细介绍了模型迁移、服务化部署及性能优化技巧,并结合智能客服系统等实战案例,展示MindIE在AI推理加速中的卓越表现。
本文详细解析了如何利用昇腾MindIE框架部署Qwen2-7B模型,构建高并发API服务。从环境配置、模型部署到性能调优,涵盖全链路实战经验,特别介绍了Continuous Batching技术如何提升LLM服务化推理效率。文章还提供了代理环境问题处理方案,助力企业级应用落地。
本文详细解析了昇腾MindIE性能调优的关键技巧,从环境配置到批处理参数优化,再到并发控制策略,帮助开发者避免常见配置错误并显著提升吞吐率。通过实战案例和数据分析,揭示了硬件资源与算法特性的最佳平衡点,为AI推理服务的高效部署提供专业指导。
本文详细介绍了如何在昇腾Atlas 200I A2硬件平台上使用MindIE框架高效部署DeepSeek-R1大语言模型。从环境准备、驱动配置到模型调优和服务启动,提供完整的部署流程和性能优化建议,帮助开发者快速实现AI模型在边缘计算场景的高效运行。
本文详细介绍了如何在昇腾MindIE平台上部署和优化Qwen2-7B大语言模型(LLM)服务,实现高并发推理。从环境配置、模型准备到RESTful API接口设计,再到性能调优和高并发压力测试,提供了一套完整的实战指南。特别针对首token时延、吞吐量等关键指标,给出了具体的优化参数和策略,帮助开发者构建稳定高效的LLM服务。
本文详细介绍了如何使用昇腾MindIE框架部署GLM4-9B-Chat模型,从环境配置到避坑指南的全流程解析。涵盖硬件要求、基础依赖安装、MindIE深度配置、模型部署实战及性能优化技巧,帮助开发者高效完成百亿参数模型的本地化部署。
本文详细解析了华为昇腾NPU与MindIE框架在镜像制作过程中的常见问题与解决方案,涵盖环境配置、组件安装、权限设置及服务启动等关键环节。通过实战案例和具体指令,帮助开发者高效解决如动态库加载失败、端口冲突等典型问题,提升AI计算部署效率。
本文详细介绍了昇腾MindIE多机集群部署实战,帮助用户在5分钟内快速搭建Deepseek R1/V3推理环境。通过自动化部署工具、性能调优技巧和避坑指南,显著提升分布式推理效率,适用于大规模AI模型部署场景。
本文详细介绍了在MindIE环境中部署DeepSeek-V3.2-Exp-W8A8模型后Function Call失效的修复方法。通过修改chat_template和源码解析逻辑,解决了提示词构造缺陷和响应解析缺失问题,确保模型能正确识别和调用function。适用于流式和非流式推理模式,提升AI应用开发效率。
本文详细介绍了在昇腾环境下使用MindIE框架部署和优化DeepSeek-R1大语言模型的实战指南。从环境准备、驱动安装到模型适配、性能调优,提供了关键参数配置和常见问题解决方案,帮助开发者高效实现大模型推理部署。
本文详细介绍了如何利用AES-256加密技术保护MindIE大模型的权重文件,从算法选型到工业级实现方案。通过分层分块加密、密钥管理体系和优化解密推理流程,确保模型安全的同时保持高性能。特别针对LoRA微调场景提供了差分加密方案,有效解决精度损失问题。
基于华为NPU部署Qwen2.5-3B大模型,通过MindIE实现OpenAI兼容接口,并结合Xinference运行Embedding模型,完成Langchain-Chatchat本地知识库搭建,适用于小规模知识场景的高效推理方案。
基于MindIELLM2.2.RC1源码分析,解析推理混部场景Prefill和Decode调度的决策逻辑。
前提:docker、docker-compose、固件、驱动、MindIE、Ascend镜像等已被正确安装。
本文详细介绍了在昇腾MindIE环境下高效部署Qwen2.5-VL-32B多模态AI模型的5个关键步骤,包括硬件选型、环境配置、模型部署、参数调优和服务化API搭建,并提供了实用的避坑指南和性能优化建议,帮助开发者快速实现本地多模态AI应用。
使用MindIE部署DeepSeek-V3.2-Exp,完整、详细。
执行nohup ./g.sh > ./g.log &后台下载即可。可以编辑shell文件,把链接都提取存好后台执行。
基于华为NPU P310芯片,使用MindIE部署Qwen2.5-3B大模型,通过Docker镜像启动并配置OpenAI兼容接口。结合Xinference运行Embedding模型,实现本地知识库问答系统搭建,适配langchain-chatchat项目全流程。
昇腾推理引擎:快速迁移、高效压缩、调试调优、服务对接。
在 MindIE 服务化运行过程中,为了及时掌握服务的运行状态、性能表现以及发现潜在问题,提供了服务监控指标查询接口(普罗(Prometheus)格式)。点击 Prometheus 安装目录下的 promethrus.exe 和 Grafana 安装目录下的bin/grafana-server.exe 启动 Prometheus 和 Grafana。修改 prometheus 安装目录下的 pro
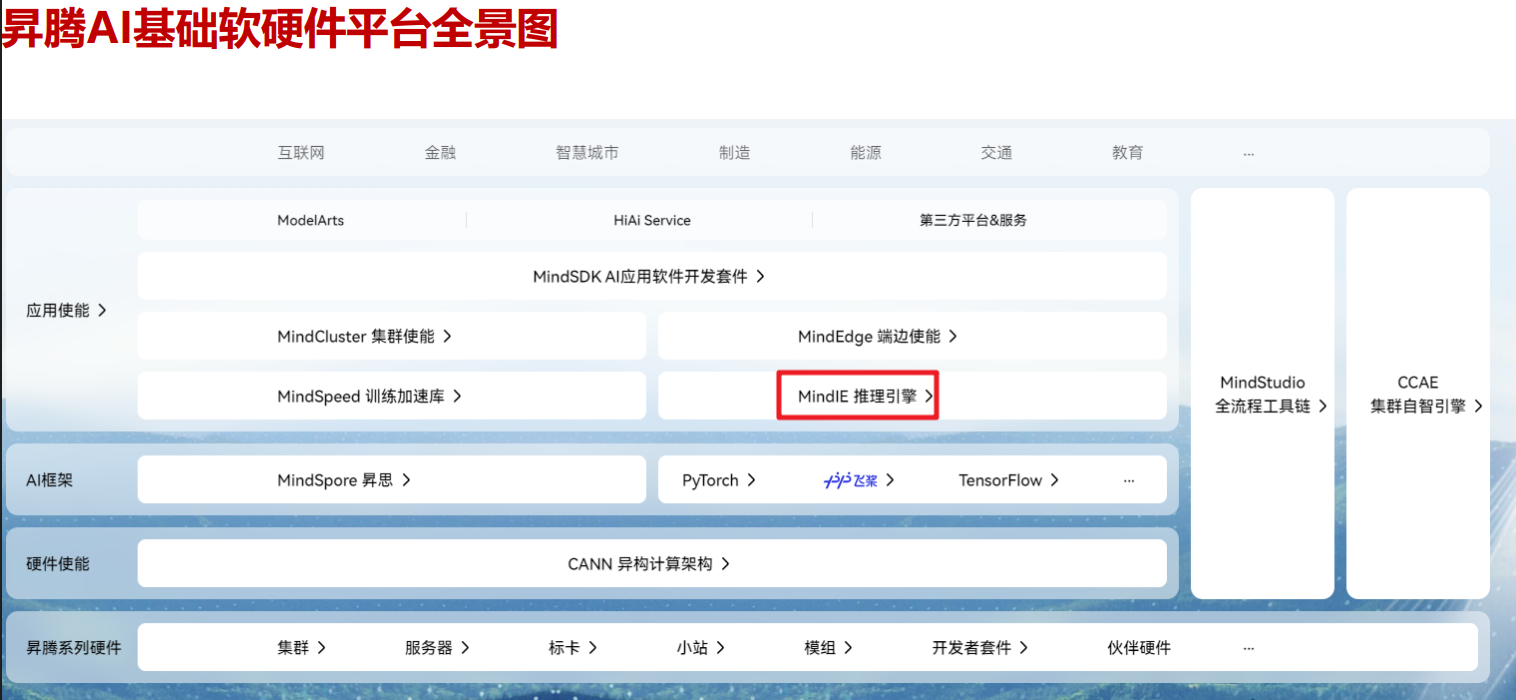
MindIE(Mind Inference Engine,昇腾推理引擎)是华为昇腾针对AI全场景业务的推理加速套件。通过分层开放AI能力,支撑用户多样化的AI业务需求,使能百模千态,释放昇腾硬件设备算力。向上支持多种主流AI框架,向下对接不同类型昇腾AI处理器,提供多层次编程接口,帮助用户快速构建基于昇腾平台的推理业务。主要包括模型推理引擎 MindIE和模型服务化 MindIE-Service。
MindIE下的atb-model源码库(修正function call),改正后,可支持流式和非流式推理
MindIE
——MindIE
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 脑启社区
脑启社区

 DeepSeek技术社区
DeepSeek技术社区

 昇腾开源生态专区
昇腾开源生态专区










 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区



 智能体开发者社区
智能体开发者社区