登录社区云,与社区用户共同成长
邀请您加入社区
理解数据中蕴含的信息是一项重要挑战。安全和可互操作的临床数据集的收集和挖掘对科学进步、人工智能训练、药物研究、科学探索、商业调查和精准医疗至关重要。
随着数据科学和人工智能的快速发展,R语言在这些领域的应用前景广阔。R语言在统计分析和数据可视化方面的优势使其在科研和教学中仍然具有重要地位。
《用R探索医药数据科学》专栏系统介绍了R语言在医药数据科学中的应用,涵盖机器学习、统计学、数据可视化、临床试验分析、文献挖掘、公共数据库挖掘等九大模块。文章对比了机器学习与传统统计学的差异,并探讨了R语言与ChatGPT结合在自然语言处理中的潜力。专栏提供5000-9000字的深度技术文章,强调实操性,指导读者从基础到进阶掌握R语言在医药领域的数据处理、建模与可视化技能,助力科研与临床研究。
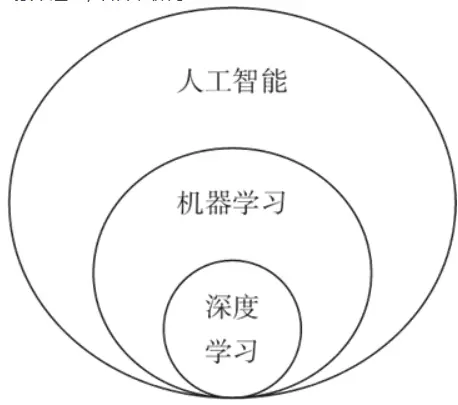
机器学习(Machine Learning,ML)则是人工智能的一个分支,致力于开发能够从数据中学习和改进其性能的算法和统计模型。简而言之,机器学习让计算机通过分析大量数据自行“学习”并做出预测或决策。
机器学习则是人工智能的一个分支,致力于开发能够从数据中学习和改进其性能的算法和统计模型
R 是一种功能强大且灵活的编程语言,广泛应用于数据科学和统计分析领域。结合人工智能技术,R 不仅为智能系统开发提供了稳健的框架,还为数据处理、建模和分析带来了高效的解决方案
本专栏针对医学研究者面临的数据分析难题,系统介绍了从基础到高阶的完整解决方案。内容涵盖:1)标准分析流程(问题定义、数据清洗、统计建模到可视化);2)R语言在医学统计中的实战应用(包括临床预测模型、生存分析、Meta分析等);3)特色技术模块(机器学习、公共数据库挖掘如NHANES/GBD/SEER等);4)科研绘图体系(传统图表到三维可视化);5)人工智能辅助分析。通过9大篇章、500+节课程,
通过创建自定义的RAII包装器类,在构造函数中打开文件或加锁,在析构函数中关闭文件或解锁,可以确保在任何执行路径下资源都能被正确释放,从而编写出异常安全的代码。使用智能指针可以彻底告别手动调用`new`和`delete`的繁琐与危险,大幅减少内存泄露和悬空指针的风险,使得代码更加简洁、安全。开发者无需编写冗长的try-catch块来确保资源释放,只需将资源封装在RAII对象内,资源的释放将由语言机
WinCaps3的帮助文档是藏在安装目录下的CHM文件,但Win10/11默认会阻止这类文件打开。调试机械臂本身已经够头秃了,别再让软件安装消耗你的发量。官方给的安装包经常是多个版本的混合体,有次我手滑装了2021版驱动结果把2019的runtime搞崩了。最近在调试DENSO机械臂的时候,发现不少同行在WinCaps3的安装和授权环节翻车。今天就结合自己的踩坑经验,聊聊怎么搞定这个工业机器人界的
函数可完整呈现高血压人群收缩压的分布形态、集中趋势与离散特征,既支持个体实测数据的分布探索,也能在仅掌握均值、标准差等汇总参数时,直接实现理论概率分布的可视化,清晰展现不同高血压分级人群的血压差异与临床规律,解决了传统工具在模型参数、贝叶斯后验等场景下的表达局限。
《医药数据科学R语言实战专栏》是一套系统全面的学习资源,覆盖从基础到高阶的医药数据分析全流程。专栏包含300多篇深度文章(每篇5000-9000字),已超190万字,持续更新最新技术趋势。内容涵盖临床试验统计、机器学习、数据可视化、公共数据库挖掘(NHANES/GBD/FAERS/GEO等)等核心领域,提供完整的数据处理、建模分析和论文写作指导。相比市面上同质化的入门资料和昂贵培训班,本专栏以39
《医药数据科学R语言实战》专栏系统讲解R语言在医药数据分析中的应用,内容涵盖统计建模、机器学习、临床试验、公共数据库挖掘等全流程技术。专栏包含300+篇深度文章(190万字),每周更新,提供从基础到高阶的系统化学习路径。特色在于:1)针对医药领域定制化内容;2)详细解析NHANES、GBD等主流公共数据库的实战应用;3)结合最新AI技术;4)提供持续更新的知识库。相比市面同类产品,该专栏以399元
在大数据时代,数据已成为企业和组织的重要资产。通过对海量数据的分析,能够挖掘出有价值的信息,为决策提供有力支持。然而,原始数据往往存在各种问题,如缺失值、重复数据、错误数据等,这些问题严重影响了数据分析的准确性和可靠性。因此,数据清洗作为大数据分析的关键前置步骤,显得尤为重要。本文将深入探讨大数据分析中的数据清洗技巧,并通过实战案例展示如何有效运用这些技巧。
Quarto是RStudio推出的新一代开源科研出版系统,作为RMarkdown的全面升级版本,它实现了跨语言支持(R/Python/Julia等)和多格式输出(HTML/PDF/Word等)的统一平台。Quarto采用标准化#|语法规范代码块参数,支持40+输出格式,内置科学写作扩展功能,显著提升了多语言协作效率。与RMarkdown相比,Quarto具有更简洁的语法结构、更智能的错误提示和更强
河北医科大学申晓刚博士最新研究发现,能量代谢衰退是衰老的核心特征,老年机体能量消耗仅为年轻时50%,并伴随脂代谢紊乱。研究创新性提出**"能量消耗衰老指数(EEAI)",通过6项代谢参数精准预测生物学年龄。实验证实,中医经典名药八子补肾胶囊**可显著逆转衰老代谢,使老年小鼠生物学年龄年轻27周,其机制包括减少内脏脂肪、改善脂肪肝、激活线粒体功能及抗炎性衰老等。该研究为气络学说指导下的抗衰老干预提供
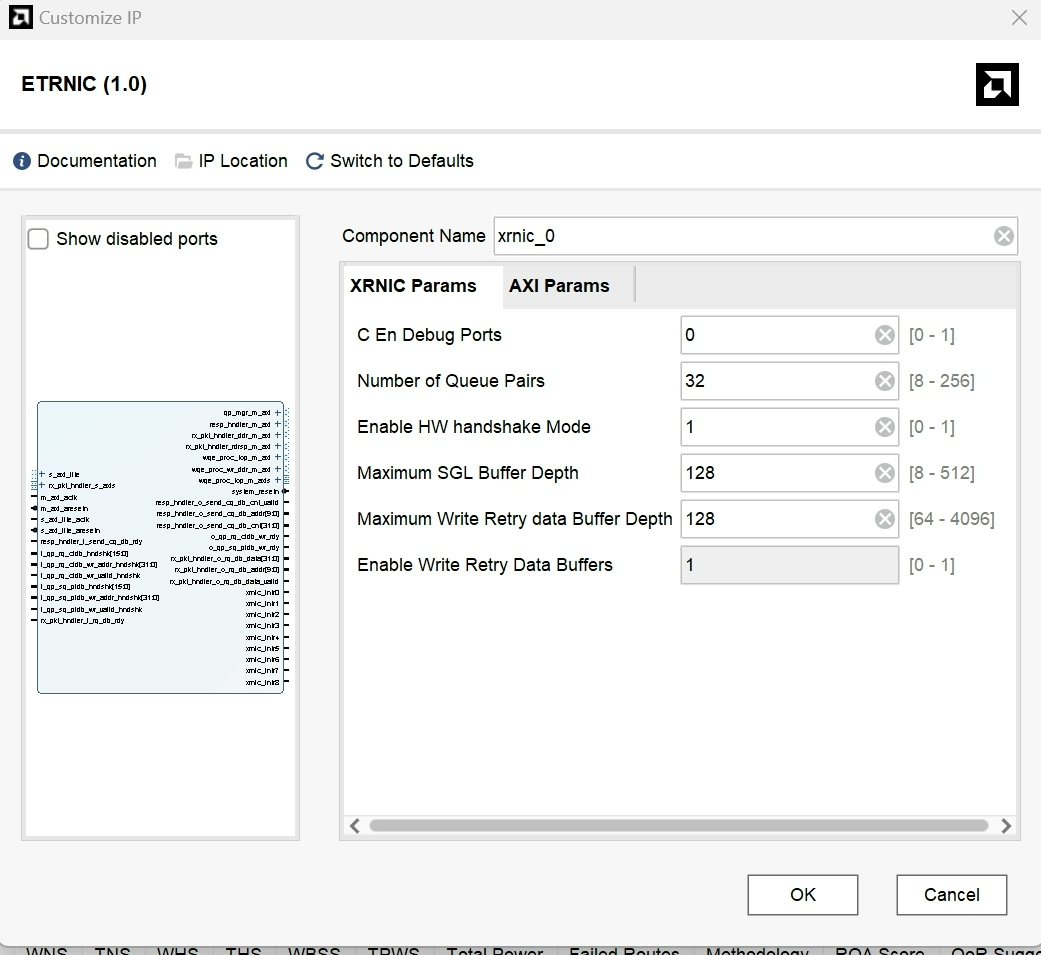
基于NVMEOF和RNIC实现RDMA上NVME存储扩展fpga实现,通过RoCE连接多个SSD终端。包含:nvmof和rnic的ip源代码,有参考设计工程,上位机软件,计算机驱动,凌晨三点的实验室里,调试器的绿灯第三次熄灭时,我终于在Xilinx Vivado的波形图里逮到了那个调皮的跨时钟域bug。这个基于NVMe-oF的FPGA存储扩展方案,正在用RoCE协议把八块PCIe SSD拧成一股4
《用R探索医药数据科学》专栏深度解析医药数据全流程,涵盖统计分析、机器学习、公共数据库挖掘等核心内容。该专栏已超220万字,包含330+篇5000-9000字的实战文章,每周持续更新追踪最新技术趋势。相比市面同质化严重的入门资料,本专栏系统讲解NHANES、GBD、FAERS等主流医药数据库的实际应用,从数据获取到论文撰写完整路径。定价399元仅为线下培训的1/10,但提供持续更新的知识库,支持反
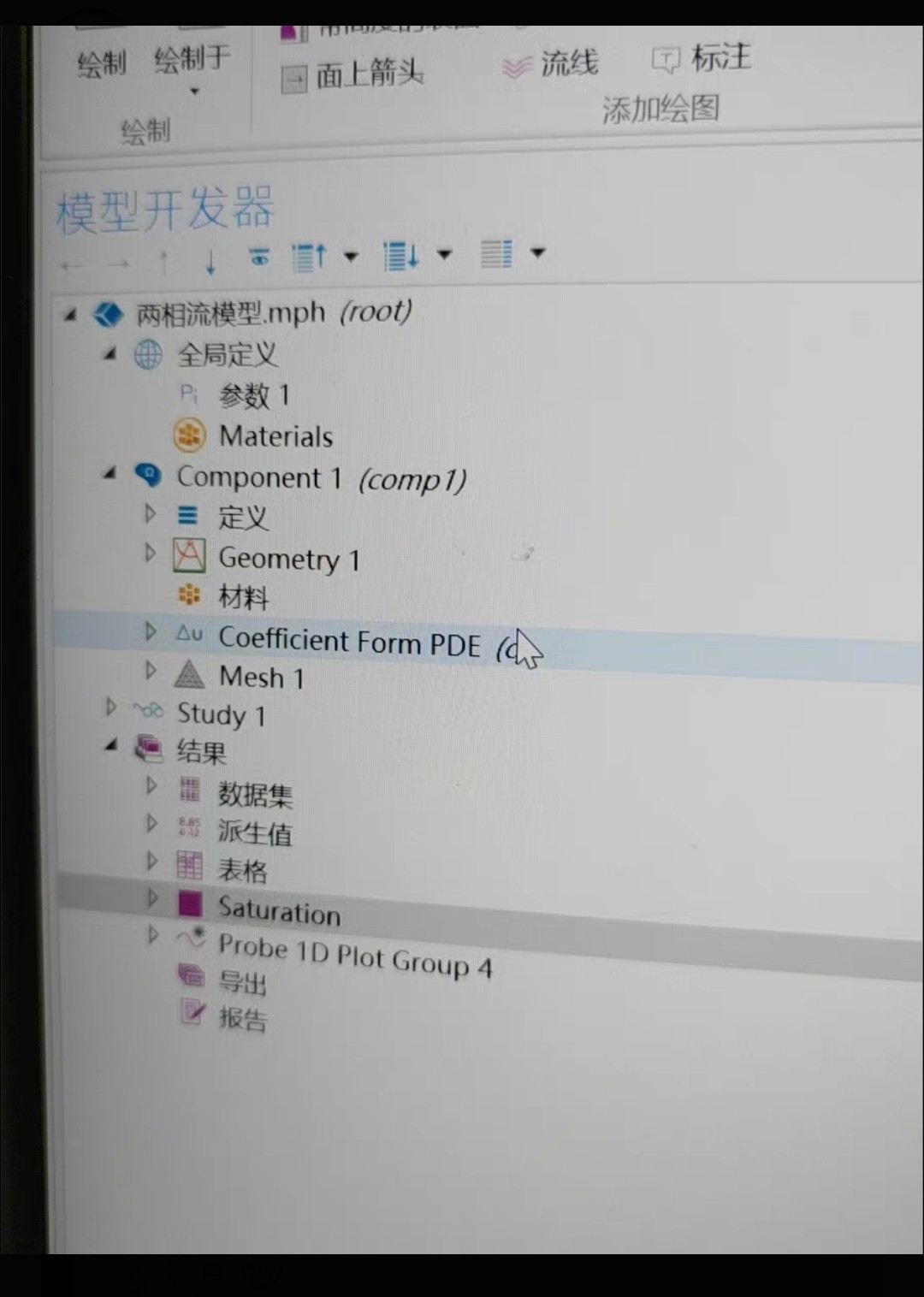
comsol 两相流模型附带视频和源文件 采用PDE建模在工程和科学领域,两相流现象随处可见,从化工过程中的气液混合,到生物医学里的血液流动(可简化为固液两相),理解和模拟两相流显得尤为重要。而Comsol作为一款强大的多物理场仿真软件,在处理两相流模型方面有着出色的表现,特别是基于偏微分方程(PDE)的建模方式,为我们深入研究这类复杂现象提供了有力工具。
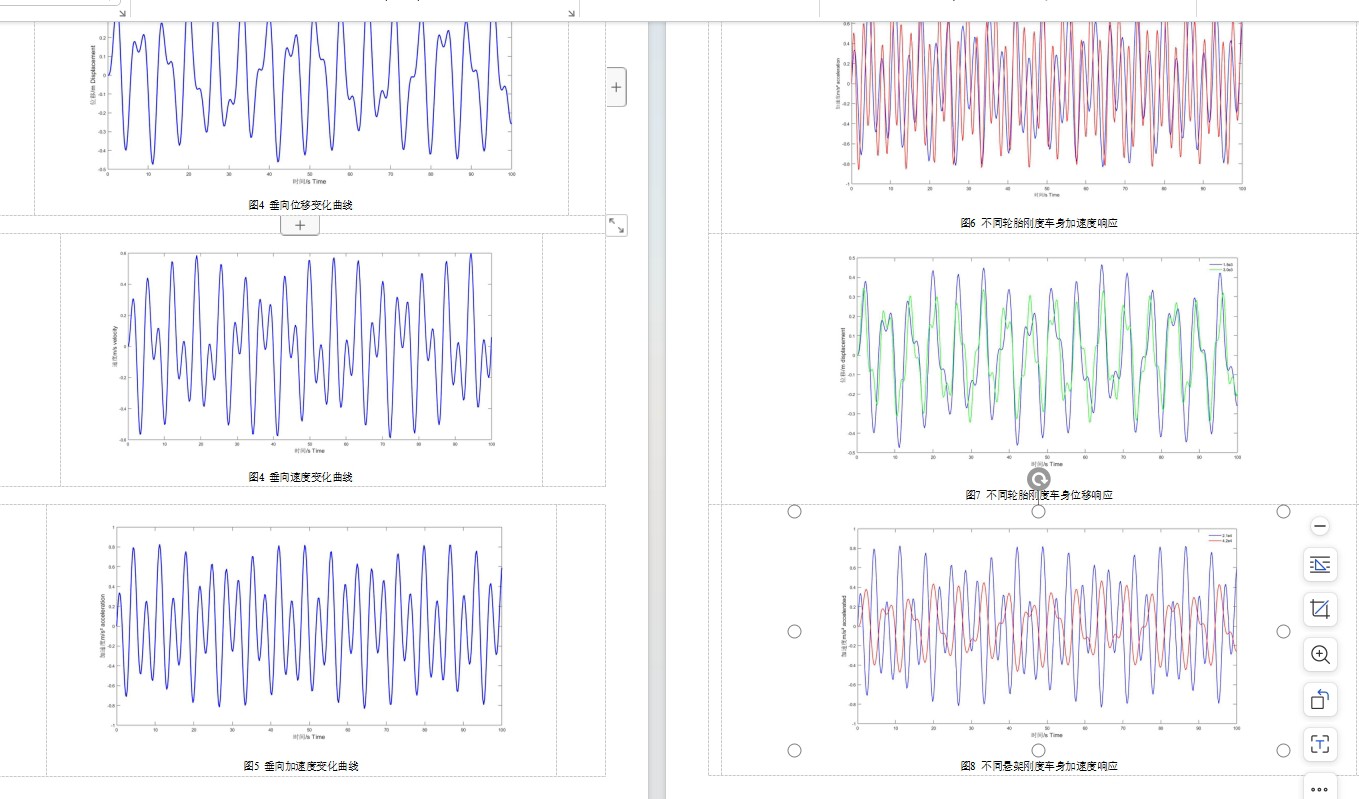
阻尼系数c的变化最有意思。注意看m1的加速度计算,既要扛住轮胎变形(kt项),又要处理悬架系统的弹簧阻尼组合拳。咱们玩的就是这个阻尼器的半主动控制,不过今天先不聊控制算法,重点看看基础模型怎么蹦跶。输入的路面激励仅为两个正弦函数的叠加,所以输出的结果在大尺度上仍然具有周期性的变化,并且车辆行驶中具有固定的频率,外部输入的频率等于车辆频率,将会发生共振。输入的路面激励仅为两个正弦函数的叠加,所以输出
临床科学家是连接医学研究与临床实践的复合型人才,他们以临床问题为导向,运用科学方法推动诊疗创新。随着大数据和AI技术的发展,临床数据科学家成为新兴分支,通过数据分析优化医疗决策。美国NIH构建了完善的资助体系,支持临床科学家从培训到独立研究的发展路径。我国高校如清华大学、北京大学等也推出"卓越医师-科学家"等项目,采用双导师制培养医学与科研兼备的复合人才。这种"医学+
系统讲解R语言中的mlr3包,该包整合了绝大多数机器学习算法,是目前堪比python做机器学习的工具
本方案聚焦于低压无感无刷直流电机(BLDC)的方波控制,采用反电动势与比较器检测电机位置的技术路径,同时集成带载满载启动能力,具备启动速度快、程序可移植性强等优势。方案核心包含传统三段式启动优化、基础方波控制实现,以及可扩展的进阶功能支持,适用于对电机控制精度、启动性能有一定要求的低压应用场景,如小型家电电机驱动、微型机器人动力系统等。
在工业级场景中,复杂的神经网络模型受到计算资源、存储约束、延迟要求以及能源效率的限制,需通过高效的优化策略实现性能提升。如Google的`AutoML`和`TensorFlow Model Optimization Toolkit`,可自动生成优化策略并适配硬件。通过框架内置加速(如TensorFlow的`XLA`或PyTorch的`torch.jit.script`)优化计算图。利用数据流水线技
R Markdown文档分为文档头和正文部分。文档头部分是由YAML(YAML Ain't Markup Language)块组成,由三个短线(-)分隔。在RStudio中新建R Markdown文件后,会自动生成文档头。下面这部分可以设置文档的标题、输出格式、作者信息、关键词、摘要等信息。
本文基于illumina官方发布的原理进行更细致讲解,更适合中国宝宝体质~
抗体分区
Mamba安装和常用命令
回归分析是最经典也是最流行的数据分析的方法,其逻辑取向是充分性分析,回归分析不能发现必要条件,只能发现充分条件。休谟的因果哲学认为X先于Y、有了X就有了Y、“没有X,Y就会不存在”,强调了X对Y的限制作用。多元回归分析中存在多个自变量,可以累加弥补由于X的缺失所对结果Y造成的影响,但必要条件确实无法弥补,这就是NCA针对的gap。回归分析不能发现必要条件,只能发现充分条件。
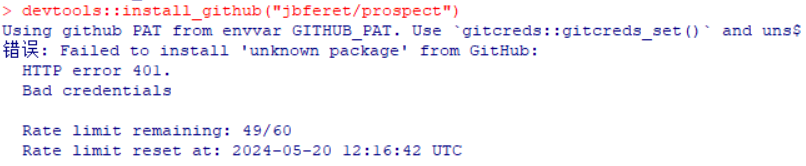
如何正确使用R的devtool包安装内容(看这篇文章的前提是你已经在R中安装了devtool)
r语言-4.2.1
——r语言-4.2.1
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 AtomGit AI 社区
AtomGit AI 社区

 AI Agent技术社区
AI Agent技术社区
 DAMO开发者矩阵
DAMO开发者矩阵

 AtomGit开源社区
AtomGit开源社区

 脑启社区
脑启社区


 腾讯云开发者社区
腾讯云开发者社区



 开源鸿蒙跨平台开发者社区
开源鸿蒙跨平台开发者社区

 2048 AI社区
2048 AI社区


 魔乐社区
魔乐社区

 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区









 中德AI开发者社区
中德AI开发者社区