- @weixin_63253486
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文主要介绍了智能体ABM(Agent-Based Modeling)建模的综述。首先,讨论了大数据挖掘与ABM仿真建模的范式互补关系,指出二者相互补充可以提高模型的准确性和可解释性。接着,分析了ABM仿真模拟范式的研究优势,包括其能够对复杂系统进行动态建模、模拟多个智能体的相互作用等特点。最后,详细介绍了ABM仿真模拟的核心特征和逻辑流程,包括智能体建模、环境建模、行为规则设计等内容。通过本文的

本博客介绍了BDA适用的各种分析技术领域。
学者常误将研究问题等同实践痛点,导致方案难落地。关键在于区分三层问题:实践问题(真实业务痛点)、研究问题(解决方案方向)与科学问题(底层机理)。在AI与风控领域,落地能力体现在将智能体嵌入业务流程,形成感知、决策、行动的闭环,最终解决“谁在何种场景下的具体问题”,完成从解释世界到改变世界的跨越。

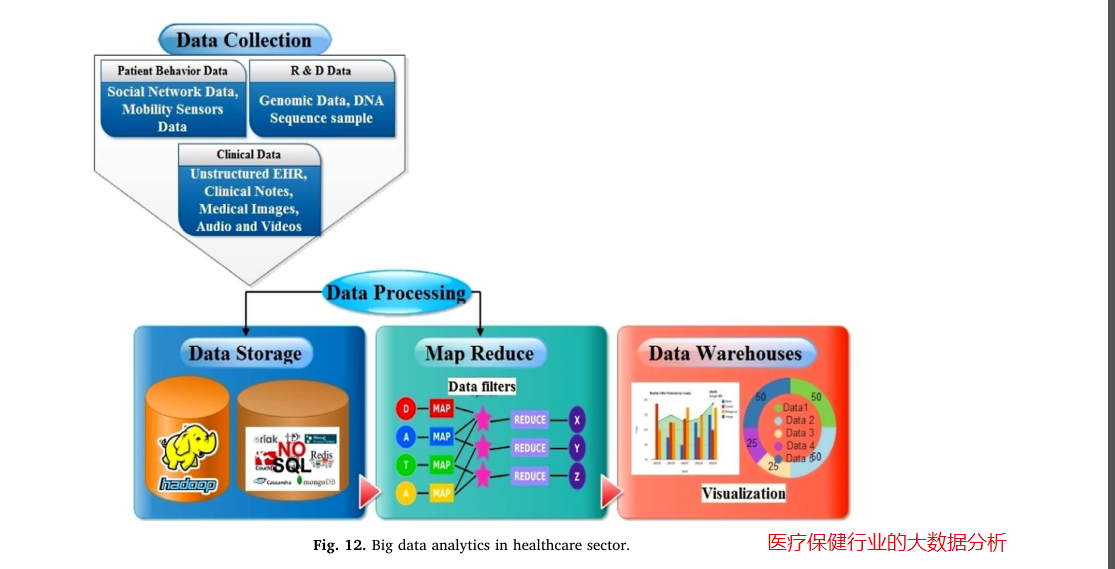
本文介绍了云服务器(Elastic Compute Service,简称 ECS)的基本概念、特点、分类及如何根据需求选择合适的云服务器类型。云服务器是一种基于云计算技术的虚拟服务器,允许用户按需租用计算能力、存储空间和网络带宽,具有弹性扩展、按需付费和高可用性等特点。与传统物理服务器相比,云服务器无需购买和维护硬件,更加灵活且成本效益高。云服务器的配置通常包括 CPU 核心数(如 1 核)、内存
本片博客介绍自己在最新版的mac上搭建vscode以及python环境时所注意的问题以及具体操作步骤。

强化学习是一种通过不断尝试和错误反馈来学习规律、实现目标的机器学习方法,类似于计算机通过虚拟老师(如反馈分数)来决定哪些行为在特定环境中能获得高分或避免低分。与监督学习不同,强化学习无需预设数据和标签,而是在实际环境中持续探索和学习。实际应用中,如AlphaGo利用强化学习在围棋比赛中取得胜利,展示了其强大潜力。强化学习中提及的算法,如Q-Learning和Deep Q Network,通过模拟环
强化学习领域探讨了多种方法,包括模型自由和模型基于的策略。模型自由方法直接从反馈中学习,无需理解环境;而模型基于方法通过建立环境模型,增强预测能力。基于概率的方法聚焦于动作的概率,旨在最大化成功概率;相比之下,基于价值的方法侧重于选择具有最高价值的动作,追求最优策略。讨论还涉及了按回合更新与单步更新的策略,以及在线学习与离线学习的区别。以Q-learning、Policy Gradients、De

运营或者日常活动中难免会遇到需要下载视频,并对视频进行编辑,本博客就是致力于批量处理已下载视频和图片的水印和字幕。

AI先驱理查德·萨顿警示:大语言模型存在根本性缺陷,而非真正的智能路径。作为强化学习奠基人,他指出当前大模型只是"博闻强识的模仿者",依赖静态文本数据,缺乏对现实世界的理解和交互能力。真正的智能应像婴儿般通过"一手经验"学习,在动态环境中试错、预测和构建世界模型。萨顿认为,未来AI发展需转向"大模拟"环境,培养自主决策能力,而非依赖人类知识结晶。这一观点或将引发AI研究范式转移,从大数据转向实时物

深度 Q 网络(deep Q-network,DQN):基于深度学习的 Q 学习算法,其结合了价值函数近似(value function approximation)与神经网络技术,并采用目标网络和经验回放等方法进行网络的训练。状态-价值函数(state-value function):其输入为演员某一时刻的状态,输出为一个标量,即当演员在 对应的状态时,预期的到过程结束时间段内所能获得的价值。状