




- @2301_79425796
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
R 是一种功能强大且灵活的编程语言,广泛应用于数据科学和统计分析领域。结合人工智能技术,R 不仅为智能系统开发提供了稳健的框架,还为数据处理、建模和分析带来了高效的解决方案
本专栏针对医学研究者面临的数据分析难题,系统介绍了从基础到高阶的完整解决方案。内容涵盖:1)标准分析流程(问题定义、数据清洗、统计建模到可视化);2)R语言在医学统计中的实战应用(包括临床预测模型、生存分析、Meta分析等);3)特色技术模块(机器学习、公共数据库挖掘如NHANES/GBD/SEER等);4)科研绘图体系(传统图表到三维可视化);5)人工智能辅助分析。通过9大篇章、500+节课程,
生成式人工智能的历史可以追溯到上世纪50年代,当时人工智能的概念刚刚萌芽。最初的探索集中在简单的规则和概率模型上。1956年,John McCarthy、Marvin Minsky、Nathaniel Rochester和Claude Shannon在达特茅斯会议上首次提出了人工智能的概念。

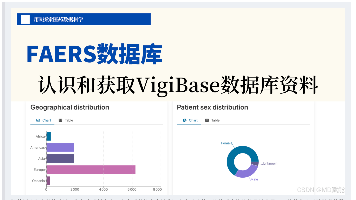
欢迎阅读《9篇3章8节:FAERS联合挖掘,认识和获取VigiBase数据库资料》!
生成式人工智能的产生发展,神经网络到Transformer架构,再到今天的提示词工程

生成式人工智能之路,从马尔可夫链到生成对抗网络

生成式人工智能的历史可以追溯到上世纪50年代,当时人工智能的概念刚刚萌芽。最初的探索集中在简单的规则和概率模型上。1956年,John McCarthy、Marvin Minsky、Nathaniel Rochester和Claude Shannon在达特茅斯会议上首次提出了人工智能的概念。
细说人工智能创作流行音乐的六个标签

神经网络是生成式人工智能的基础,使机器能够生成模仿真实数据分布的新数据实例。

函数可完整呈现高血压人群收缩压的分布形态、集中趋势与离散特征,既支持个体实测数据的分布探索,也能在仅掌握均值、标准差等汇总参数时,直接实现理论概率分布的可视化,清晰展现不同高血压分级人群的血压差异与临床规律,解决了传统工具在模型参数、贝叶斯后验等场景下的表达局限。
