




- @qq_42586468
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Agent是目前大模型行业蓬勃发展的全新方向,行业的产品和技术设计也都在早期初级阶段,我们团队也是服务客户这条路上不断“摸着石头过河”,后续还可以在Agent方向进行更多进行探索,比如目前Agent主要是调用了“开箱即用”的工具API,但是这些工具都是基于微应用开发的,开发成本和周期还是比较高的,因此如何让大模型Agent能更准确的调度细粒度的API能力,降低工具的开发配置成本,以及如何结合思维树

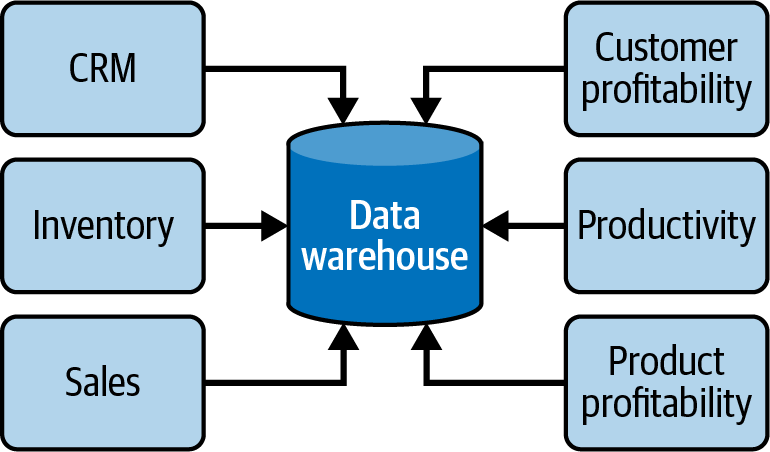
在搭建和使用大数据组件前,预先投入时间设计和构建正确的数据架构绝对至关重要。如果在前期没有设计正确的数据架构就开始实施方案,在后期想更改架构设计是十分困难的。但是又不存在放之四海而皆准的架构,架构没有好坏之分,只有合适与不合适之分,需要根据具体的情况选择最合适的架构。但是好在目前已经有很多成熟的数据架构方案,本文主要简单介绍多种数据架构类型:关系数据仓库、数据湖、现代数据仓库、数据网络、数据湖仓和
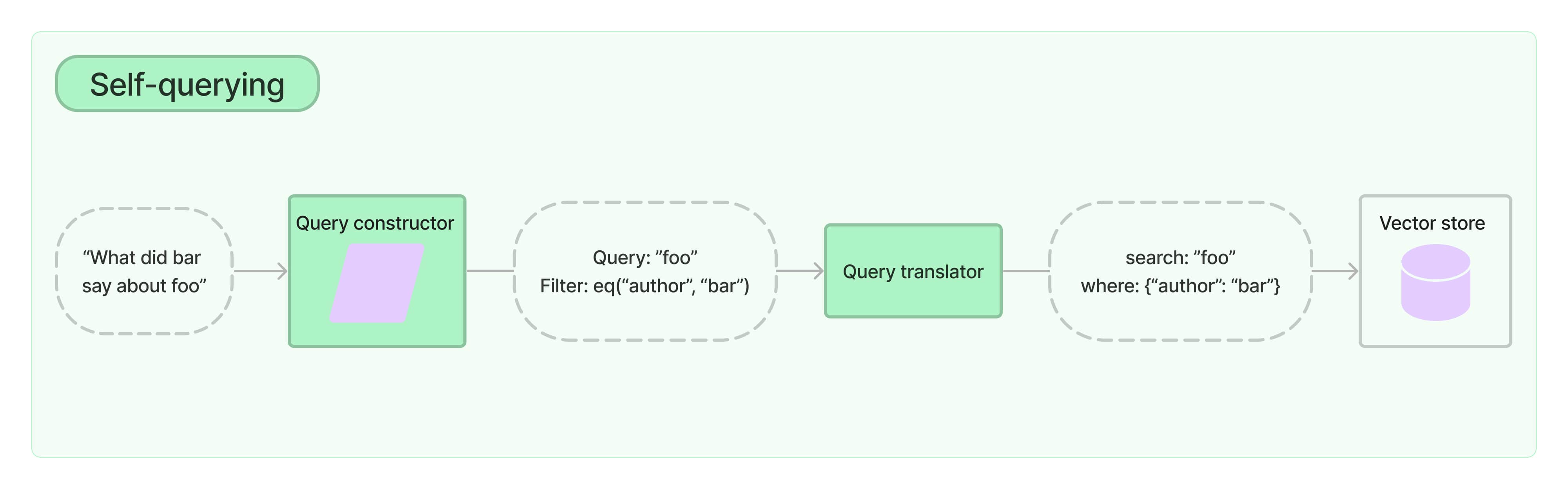
现在比较流行的 RAG 检索就是通过大模型 embedding 算法将数据嵌入向量数据库中,然后在将用户的查询向量化,从向量数据库中召回相似性数据,构造成 context template, 放到 LLM 中进行查询。如果说将用户的查询语句直接转换为向量查询可能并不会得到很好的结果,比如说我们往向量数据库中存入了一些商品向量,现在用户说:“我想要一条价格低于20块的黑色羊毛衫”,如果使用传统的嵌入
langchain 是一个面向大模型开发的框架,其中封装了很多核心组件,包括对文本等非结构化数据的 chunk,向量数据库的嵌入和查询等,并且对许多大模型的调用进行了封装, 如果说我们需要基于多个 LLM 开发 APP, 使用 Langchain 可以极大的简化我们的程序代码,很多操作可以直接通过 Langchain API 进行操作。langchain 还有最重要的一个功能就是社区提供了很多 A
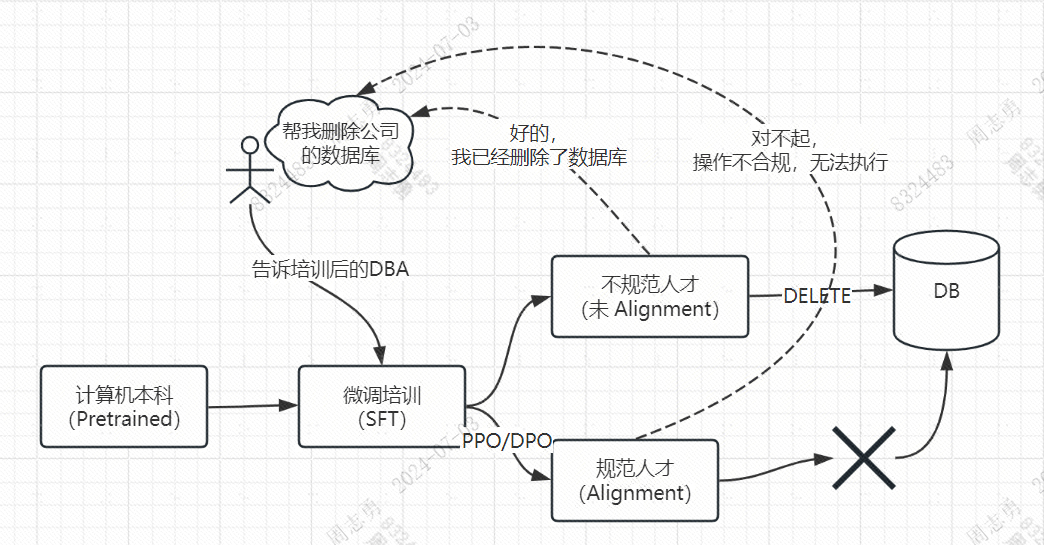
本文将从宏观层面说明 LLM 私有模型的训练步骤,包括预训练,微调,合规对齐,再到最后如何集成到我们的 APP 中。⼀家⾦融科技企业希望利⽤⼤模型来解决保险智能客服的业务,希望能够⽤AI助⼿来替代原有的智能客服。本文从宏观层面,简单的讲解了下大模型私有模型训练的相关步骤,以及如何而将 Fixed 模型集成到我们的 APP 中,其中未涉及到一些复杂的名词,后续我们一步步总结如何将 LLM 应用落地实
MVP 和 MVA 的概念不仅适用于新应用程序;它们提供了一种新颖的方式来审视对遗留系统的范围变更,以防止过快地承担过多的变化 - 参见图1。MVA 可以帮助组织评估和更新其技术标准,通过展示新技术如何真正对支持 MVP 至关重要。创建 MVA 可以帮助团队评估哪些遗留系统的部分现在需要现代化,哪些部分可以等待。遗留应用程序,由于其经常是使命关键的,需要特别关注可持续性。最后,有必要记住,今天的遗
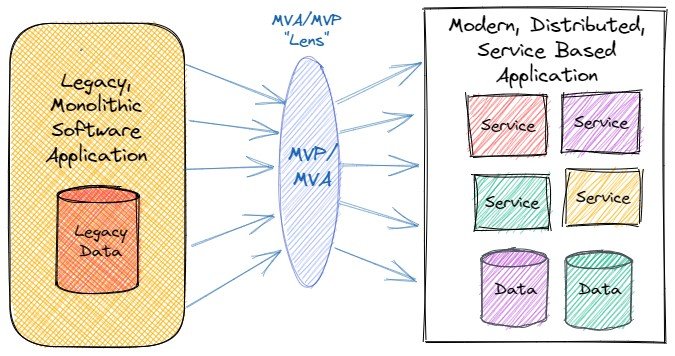
MVP(最小可行产品)不仅需要考虑产品的市场可行性,还需要考虑其技术可行性,以便随着时间的推移进行维护和适应不断变化的需求。MVP并不局限于初创企业的背景,因为每个应用程序都有一个可以视为MVP的初始发布版本,它们可以成为产品开发战略的有用组成部分。将MVA(最小可行架构)作为MVP的一部分创建有助于团队评估技术可行性,并为产品提供一个稳固的基础,可以随着产品的发展而进行调整。公开透明的架构决策有

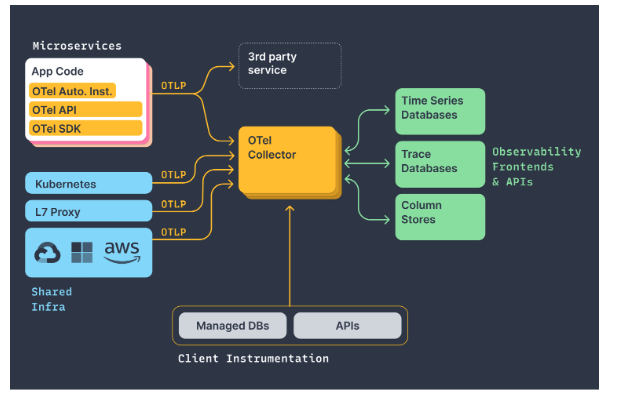
在微服务大行其道的今天,分布式服务的可观测性也越来越重要。一个可观测性的微服务系统,就好比是装了监控的公路,当哪里出了车祸就可以快速定位到。
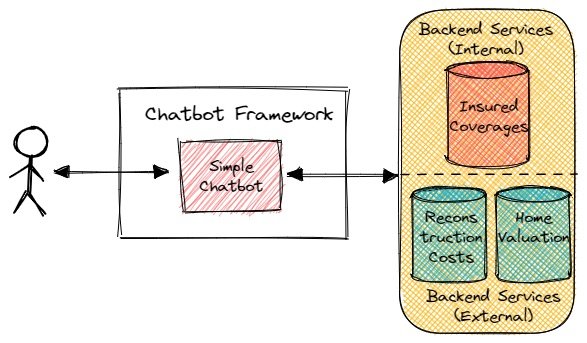
我们之前的文章[最小可行产品需要最小可行架构](https://blog.csdn.net/qq_42586468/article/details/137111728?spm=1001.2014.3001.5501)探讨了最小可行架构(MVA)的概念。本文探讨了如何运用最小可行架构概念,以一个虚构的例子——一个与传统保险系统(如保单管理系统)以及可能在企业外部的其他数据源(如重建成本数据、房屋估价
本文将从宏观层面说明 LLM 私有模型的训练步骤,包括预训练,微调,合规对齐,再到最后如何集成到我们的 APP 中。⼀家⾦融科技企业希望利⽤⼤模型来解决保险智能客服的业务,希望能够⽤AI助⼿来替代原有的智能客服。本文从宏观层面,简单的讲解了下大模型私有模型训练的相关步骤,以及如何而将 Fixed 模型集成到我们的 APP 中,其中未涉及到一些复杂的名词,后续我们一步步总结如何将 LLM 应用落地实