




- @xiaocheng121212
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
当 AI 大模型的“炫技式应用”逐渐褪去热度,你会发现企业真正关心的问题浮出水面:AI 能否从“对话助手”进化为“业务伙伴”,切实解决合同审核、报告生成、知识管理等核心业务痛点?阿里通义 DeepResearch 给出了答案:一套围绕“业务价值闭环”构建的企业级 AI 架构,让大模型从“实验室玩具”真正走进“生产线”,成为能落地的生产力工具。DeepResearch 破局的关键,在于跳出“单一模型

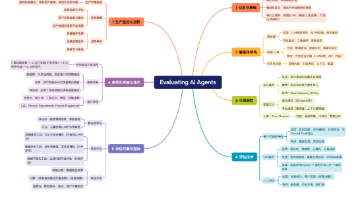
吴恩达《Evaluating AI Agents》课程系统介绍了AI智能体评估方法论。课程从智能体架构(路由器、技能、内存)入手,强调通过OpenTelemetry和Arize Phoenix实现运行可观测性。核心提出三种评估技术:代码评估(确定性高)、LLM裁判(灵活性好)和人工标注(准确性优),并演示如何评估路由器决策、技能输出和执行路径效率。课程创新性地提出"评估驱动开发"
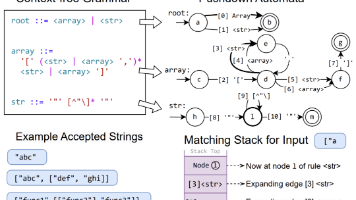
本文探讨了大语言模型(LLM)生成结构化输出的技术演进与实现方法。传统LLM主要生成自由文本,难以被机器直接解析。结构化输出通过强制模型遵循JSON、XML等预定义格式,使输出具备可预测性和机器可读性,成为AI应用的关键接口。 报告从"软"到"硬"分析六大技术路径:Prompt工程通过指令和示例引导生成;验证修复框架对输出进行事后保障;约束解码进行事前硬性限
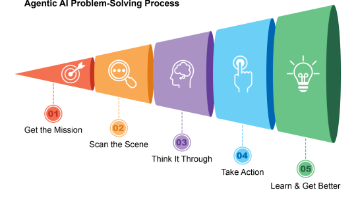
AI智能体的演进与未来展望 AI智能体正从简单的语言模型发展为能感知环境、规划行动并自我学习的复杂系统。其发展经历了四个阶段:基础LLM、工具增强型、战略规划型,直至当前协同工作的多智能体系统。未来五大趋势包括:1)全能型通才智能体的出现;2)深度个性化服务;3)具身化与物理世界交互;4)智能体驱动的新经济模式;5)目标导向的自适应多智能体系统。这些发展将重塑工作方式和经济结构,预计到2034年市
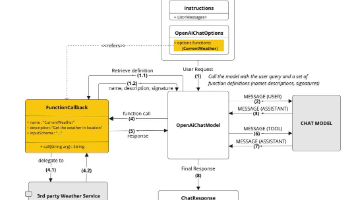
文章摘要 大型语言模型(LLM)存在知识过时、无法执行外部操作和生成结构化指令不可靠等局限性。Function Calling机制通过让LLM识别用户意图并生成结构化JSON请求,连接语言能力与外部功能,实现了从文本生成到任务执行的转变。该机制基于JSON Schema定义工具能力,使LLM能可靠选择并调用外部函数,形成"意图识别→函数选择→执行→结果整合"的闭环工作流。相比传
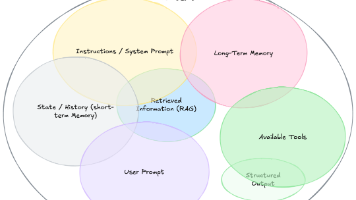
摘要 随着AI系统复杂度提升,传统"提示工程"已无法满足需求,"上下文工程"(Context Engineering)应运而生。这一新兴AI系统工程方法包含系统设计、动态信息管理和多模态优化三大组件,通过整合RAG技术、高级检索、状态管理和工具编排等能力,使AI系统能处理更复杂的上下文信息。相比单纯的提示工程,上下文工程更具系统性和持续性,已应用于企业OA、
AI Agent框架2025年趋势解析 2025年AI Agent框架生态呈现多元化发展,七大核心框架各具特色: LangChain:模块化架构,适合高度定制化单Agent应用 LangGraph:图结构工作流,支持多Agent复杂协作 CrewAI:角色驱动,结构化分工提升商业场景效率 AutoGen:对话式协作,适合创造性探索任务 Semantic Kernel:企业级集成,兼容传统系统 选型
这篇论文探讨了AI代理设计中的哲学思考,提出在AI日益普及的背景下如何平衡技术赋能与人类自主性的问题。作者批判当前中心化AI系统可能带来的操控风险,主张转向"哲学对话"范式,让AI扮演质疑者而非决策者角色。核心建议包括:采用苏格拉底式提问促进用户反思、构建去中心化探究网络、确保系统透明性和模块化设计等。文章呼吁从"数字修辞"转向"哲学探究"

中国天才少年Peak Ji提出AI Agent核心突破:上下文工程。随着AI执行复杂任务时上下文窗口膨胀导致性能下降的问题,季逸超团队总结出五大策略:上下文卸载、缩减、检索、隔离和缓存。Manus实践表明,通过KV-Cache优化、文件系统作为上下文等技术,可将性能提升10倍。Peak Ji强调初创公司应优先采用上下文工程而非模型微调,并分享了"压缩与总结"的艺术。他认为优秀的
摘要:DeepSeek-OCR通过视觉Transformer和大语言模型相结合,实现了从传统文字识别到视觉语义理解的突破。其核心技术是视觉压缩范式,可将整页文档压缩为视觉token,大幅提升处理效率同时保持结构完整性。该技术支持多种文档格式,提供不同规模的模型版本,适用于智能文档处理、科研论文解析等场景。DeepSeek-OCR代表着AI从语言智能向视觉语言智能的转变,为下一代文档理解系统开辟了新