登录社区云,与社区用户共同成长
邀请您加入社区
为遵守国家网络实名制规定,未绑定将限制内容发布与互动
你有没有遇到过这种情况——做 AI 应用,每轮对话都要把几千 Token 的历史记录重新拼一遍,代码里一堆 messages.append(),服务器带宽烧得心疼,延迟还越来越高。然后 OpenAI 说:别拼了,我来管,你只管传个 ID。听起来很美好,对吧?但当你真去用的时候,发现坑比想象的多:数据存哪了?Token 真省了吗?换模型怎么办?历史能改吗?我花了三天把 OpenAI 的 Respon
本期重点测最颠覆的 AI 代理:把目标网址和你要的字段用中文描述一遍,它先生成结构化 schema 让你确认,再自动写出采集逻辑,点一下测试运行,几分钟就拿到了干净的表格化数据——我一行代码没写。而自愈只要用大白话描述"哪里采不到了",它就自动分析、重写受影响代码,数分钟修复并一键发布,不限你用哪种方式建的爬虫。最后我们还用 CLI 命令行直接跑通了同一个爬虫,把结果导出成 JSON——说明它既能
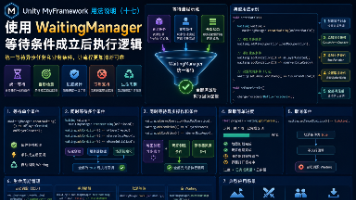
上一篇介绍了 AsyncTaskGroup,它适合等待多个异步操作全部完成。实际业务中,流程开始的条件不一定都是异步任务。例如进入战斗前,除了等待地图加载,还可能需要等待玩家创建完成、服务器场景数据到达。MyFramework 提供了 WaitingManager,用于把这些等待条件统一封装起来。
"产出全套可直接上线商用工程包" ↔ 我的 Case 1;"少提示自主完成,几乎不返工" ↔ 我的 Case 2;"不是修 bug 数量领先的,而是改到了导致 bug 的架构根因" ↔ 我在长仓库里感到的"多想一步"。如果你也想给家人做个小东西,或者自己搭个效率工具,Evolving + TRAE 是个低门槛的入口。它适合长程任务、大仓库、需要多轮迭代的真实工程。下周我打算让它帮我加个"家族对战"
这次测试的AI去反光和AI鉴伪小程序 ,我的脑子里一直盘旋两个词——"看清"和"看透"。AI深度渗透时代,可信信息通道就是底层基础设施。从一张反光照片还原的细节,到一段被判深伪的视频,再到一份被识别为AI生成的文本——每处都是"真实"与"虚假"的较量。
本书系统讲解人工智能大模型(如BERT、GPT、Stable Diffusion等)所需的数学基础,涵盖线性代数、微积分、概率与统计三大核心领域,并结合实际案例与Python代码,解析数学原理在模型架构、训练与优化中的关键作用。第6章和第7章阐述概率与统计基础及其在大模型中的体现;从数学公式到智能模型,打通AI底层逻辑——线性代数、微积分、概率与统计三大支柱,结合BERT、GPT、Stable D
本文介绍了智能对话技能(Skill)开发后阶段的完整生命周期管理,包括测试体系、发布流程和运维监控三大部分。测试体系采用分层策略,涵盖单元测试(配置验证、触发条件匹配)、集成测试(插件调用模拟)和端到端测试(多轮对话流程),通过代码示例展示了pytest框架和异步测试的实现。发布流程采用灰度策略,逐步扩大用户范围并收集反馈。运维监控则通过日志分析和性能指标确保技能稳定运行。文章强调测试自动化、渐进
看完速成的文章,Python还是很好学的,语法也很简单,没有那么多弯弯绕绕的规范。最近也是有一点迷茫了,作为前端开发,感觉看到头了,ai现在能替代掉90%的前端了吧,前端的职业生涯就要到头了,我感觉自己也没什么优点,也没有什么很擅长的事情,感觉并没有为团队做出什么贡献,很迷茫,不知道何去何从,很想努力,不知道往哪努力,好吧,我只能再慢慢摸索一下啦,虽然我很迷茫,但是安排给我的工作,我都会保质保量的
用了一周 Bright Data CLI,我最大的感受是:它把代理管理、CAPTCHA 解决、JS 渲染、结构化数据提取、AI 爬虫生成、AI Agent 集成——这些传统爬虫开发里最耗时的环节——全部压缩进了几条终端命令。一次登录,零配置启动,每月 5,000 次免费额度,不用信用卡。如果你是后端开发者、DevOps 工程师或 AI 工程师,需要一个能直接融入 Shell 脚本和自动化流水线的网
开源免费分享基于SpringBoot+Vue的汽车服务管理系统管理系统设计与实现【Java+MySQL+MyBatis完整源码】可提供说明文档 可以通过。Boot 与前后端分离架构,累计原创技术博文 200+ 篇;👨🎓博主简介 ❤计算机在读硕士 | CSDN 专业博客 | Java 技术布道者 ❤深耕实验室一线,痴迷 Spring。AIGC**技术包括:MySQL、VueJS、Element