




- @CodingKitten
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
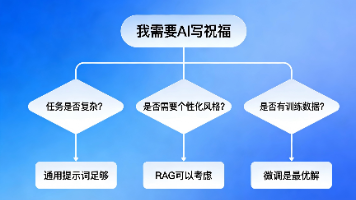
微调大模型确实需要一些技巧,但绝不像很多人想象的那么难。参数设置是平衡艺术:没有“最佳参数”,只有“适合你任务和硬件的参数”从简单开始:先用小学习率、中等轮数、较低LoRA秩开始实验重视数据分析:花时间分析数据长度分布,合理设置截断长度显存不够有技巧:梯度累积、Liger Kernel、DeepSpeed都是你的“省显存神器”找一个中等大小的数据集(2000-5000条)选择7B左右的模型平衡效果

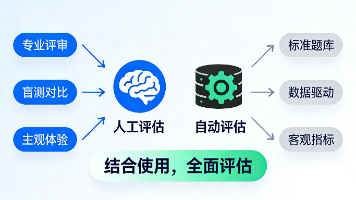
评估是必须的:没有评估的微调就像蒙眼射击两条腿走路:人工评估抓“感觉”,自动化评估抓“数据”评估要全面:既要看专项提升,也要防通用能力倒退工具能提效:善用OpenCompass等框架,让评估自动化迭代是关键:评估 → 调整 → 再评估,循环优化。
他面对你的需求时,是基于对“关系”和“场景”的深刻理解,进行“创作”,而非“拼凑”。模型在学习的过程中,会反复地看到:当用户的需求包含“王总”、“客户”、“印象深刻”、“商务得体”这些关键词时,一个优秀的“人类助手”会如何组织语言,如何在表达尊敬的同时拉近距离,如何巧妙地把“马术”这个共同话题融入到马年的祝福里。因为它不再是在“写”,而是在“表达”。微调后的模型,不仅记住了“科技风”,还把“算力”

我们需要做的,是把我们脑子里那些关于“关系”和“分寸”的隐性知识,变成模型能够理解的数据结构,然后“喂”给它。通过这次小小的实践,我们不仅得到了一个更“懂人事”的AI助手,更重要的是,我们亲手体验了如何让一个通用模型向“个性化”迈出关键一步。,它就提供了一个非常友好的界面,你甚至不需要写代码,就可以按照它的引导,一步步地构建出自己的训练数据集。它会显得很“碎”,像是在拼凑你的聊天记录,而不是在创作
特别是到了马年,满屏的“龙马精神”、“马到成功”,看多了,也就成了“正确的废话”。这其实是我们目前使用AI的一个缩影:通用大模型很聪明,上知天文下知地理,但用到具体的人和事上,它就像一个不太熟的朋友,客气、周到,但就是走不进心里。今天,我就把这份完整的手记分享出来,不仅带你走一遍流程,更重要的是,和你聊聊背后的原理——我们到底是怎么“调教”AI,让它学会说人话、懂人情世故的?在这个马年,希望我们发

很多人做AI应用容易犯一个错误:拿到模型就想微调,但连“好”的标准是什么都没定义清楚。坐下来,把人际关系掰开了揉碎了,拆成计算机能理解的维度。维度作用举个例子称呼决定了亲密程度“王总” vs “老王” vs “老爸”关系决定了行为边界客户不能调侃,恋人不能太官方交往细节让祝福“专属化”的关键“去年合作马术项目”场合微信 vs 当面说,语感完全不同微信可以带表情包,口头要顺溜风格整体情绪基调传统喜庆

这需要创意,更需要记性——记得你们一起熬过的夜,记得他提过的爱好,记得你亏欠的那句“辛苦了”。通用大模型读了几万亿个tokens,它知道“春节”要接“快乐”,“客户”要接“财源广进”,但它不懂你和“王总”去年在北京饭局上聊过马术,也不懂你老爸虽然是个老码农,但你只想祝他bug少一点。发的人没走心,收的人当任务。这个区别,模型是猜不出来的,你得把它拆成公式,喂进它的脑子里。这是现在最主流的“以小博大

我试过直接用Qwen3-32B、Llama-3这些开源模型,输入“给客户写马年祝福”,出来的东西长这样:“值此丙午新春之际,谨向您致以最诚挚的问候……”要素全对,但你会发吗?反正我不会。这根本不是“微信对话框里的拜年”,这是。所以在春节前我干了件事:用低门槛的微调工具,让大模型学会辨认“谁在跟谁说话”。今天这篇干货,就把整个技术链路拆开揉碎了讲给你听,。

这个春节项目做下来,我最大的感触其实和技术本身关系不大。我们总在追求更长的上下文、更低的困惑度、更高的榜单分数。你懂不懂我?通过LoRA和量化,我们把一个32B的庞然大物塞进了有限的显存;通过精心构造的数据集,我们让它学会了“人情世故”。未来专属模型的竞争力,不取决于你调用了多少张卡,而取决于你喂进去了什么样的生活。如果你也想在这个马年,让AI帮你记住那些重要的关系细节,不妨动手试试上面这套流程。

有人问我:你花这么多时间,就为了教AI写几句祝福语,值得吗?值得。过去几年,我们谈论AI,谈的最多的是“效率”——一分钟写周报,两分钟做PPT,三分钟读一本20万字的书。这些都很酷,但它们解决的是“快不快”的问题。而祝福语这件事,解决的是“对不对”的问题。在这个“复制、粘贴、群发”成为默认选项的年代,愿意花时间为你写一句独一无二的话,本身就是一种稀缺的心意。如果AI能帮我们把这份心意更好地表达出来
