




- @weixin_38235865
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
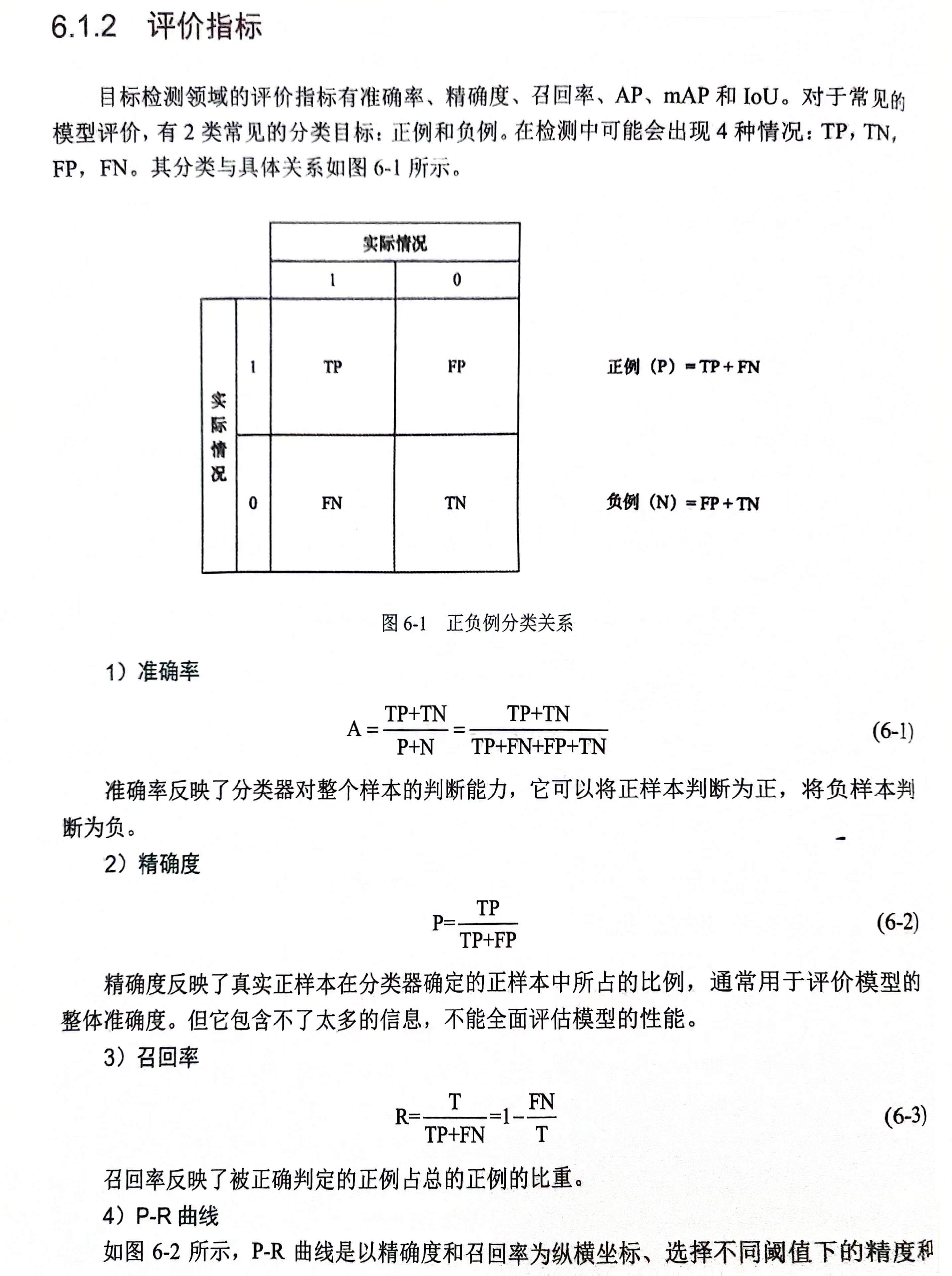
减少目标定位的准确度减少背景干扰提高目标定位的准确度目标检测系统常用评价指标:检测速度和精度提高精度:有效排除背景,光照和噪声的影响提高检测速度:精简检测流程,简化图像处理算法算法概述:传统目标算法、基于候选区域的两步算法、基于回归的单步算法1.传统目标算法对于区域选择,传统目标检测最常用的两种模型是滑动窗口模型与缩放窗口模型。滑动窗口模型,顾名思义,是通过设计好的窗口在图像上进行滑动来检测目标。
是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。不仅能够 实现强大的GPU加速,同时还支持动态神经网络.PyTorch提供了两个高级功能:1.具有强大的GPU加速的张量计算(如Numpy)2.包含自动求导系统的深度神经网络与tensorflow,caffe区别TensorFlow和Caffe都是命令式的编程语言,而且是静态的,首先必须构建一个神经网络,然后一次又一次使
通过计算词语的词频,实现一个字典,字典键为名字,值为出现的次数,词频归一化 当前词语的出现次数/出现最多的词语次数-出现最少的词语次数,current_value/(max_value - min_value),循环每个词语的字段,最后构建字典{名字第一个字符:[(名字,对应频率),(),…]},类似{“病”:[[“病毒感染”,0.1],[“病毒性上呼吸道感染”,0.001],]计算词频关键代码:
spark支持多种输入源常见3种数据源文件格式与文件系统spark可以访问很多种不同的文件格式,包括文本文件、JSON、SequenceFile、protocol buffer.Spark SQL结构化数据源包括针对JSON、Apache Hive在内的结构化数据数据库与键值存储spark自带库和一些第三方库,可以用来连接Cassandra、HBase、Elasticsearch以及JDBC源文件
spark主要的机器学习API是基于DataFrame的一组模型,它们包含在spark.ml包中。包的概述在顶层,该软件包公开了3个主要的抽象类:转换器、评估器、管道。转换器通常通过一个新列附加到DataFrame来转换数据。常用转换器:Banarizer:根据指定的阈值将连续变量转换对应的二进制值Bucketizer:与Banarizer类似,该方法根据阈值列表,将连续变量转换为多项值Hashi
pyspark数据预处理实践数据预处理目的数据可能由重复数据,异常数据,未观测数据,等问题,就算数据集可以视为干净的,未了清理数据集进行建模,还需要检查数据特征的分布并且确认它们符合定义的标准PySpark使用简介python中初始化sparkContext先创建一个SparkConf()对象配置应用,然后基于这个SparkConf()创建一个SparkContext对象conf = SparkC
减少目标定位的准确度减少背景干扰提高目标定位的准确度目标检测系统常用评价指标:检测速度和精度提高精度:有效排除背景,光照和噪声的影响提高检测速度:精简检测流程,简化图像处理算法算法概述:传统目标算法、基于候选区域的两步算法、基于回归的单步算法1.传统目标算法对于区域选择,传统目标检测最常用的两种模型是滑动窗口模型与缩放窗口模型。滑动窗口模型,顾名思义,是通过设计好的窗口在图像上进行滑动来检测目标。
一、基于MLlib的机器学习MLlib是Spark中提供机器学习函数的库,该库专为集群上并行运行的情况而设计MLlib设计理念:把数据以RDD形式表示,然后在分布式数据集上调用各种算法。归根结底,MLlib就是RDD上一系列可调用的函数的集合。注意:MLlib只包含能够在集群上运行良好的并行算法,包括分布式随机森林算法,K-means,交替最小二乘法等,如果用小规模数据集,单节点用scikit_l
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE log4j:configuration PUBLIC "-//APACHE//DTD LOG4J 1.2//EN" "http://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/xml/doc-files/log4j.d.