- @weixin_47723732
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
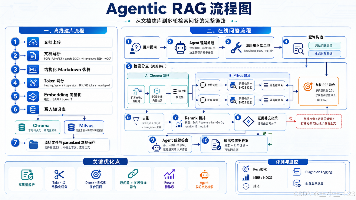
本文探讨了RAG(检索增强生成)技术在实际生产环境中的优化实践。通过同时接入Chroma和Milvus两种向量数据库,构建了一个支持混合检索的知识库系统。系统核心创新点包括:文档解析阶段保留Markdown结构、基于Token的智能文本切分、向量与BM25混合检索策略、查询扩展与RRF融合算法,以及重排序模型的应用。文章详细介绍了技术选型考量、文档处理流程、检索链路设计,并对比了不同方案的优缺点。
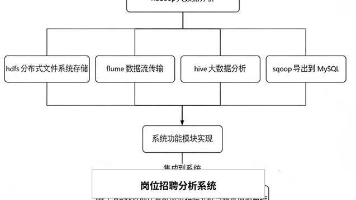
本文介绍了一个基于大数据和机器学习的健康数据分析系统,重点围绕心脏病风险预测展开。系统整合了数据采集、清洗、分布式分析、可视化展示和机器学习预测全流程,采用Hadoop生态进行数据处理,Hive进行统计分析,MySQL存储结果,并通过Flask框架构建Web应用。系统功能包括数据可视化分析、在线风险预测、用户管理等功能模块,支持用户根据个人健康信息进行风险评估。项目亮点在于将大数据处理、机器学习与

摘要: 本项目构建了一套完整的计算机岗位招聘数据分析与可视化平台,涵盖数据采集、清洗、Hadoop存储分析、Web可视化及薪资预测全流程。通过Selenium爬取多维度招聘数据,经Hive多主题离线计算后同步至MySQL,结合Flask+ECharts实现动态大屏展示与交互式图表(如薪资分布、技能热度词云等)。创新性引入CatBoost回归模型预测岗位薪资,并设计管理员后台进行数据维护。系统采用H
本项目是一个完整的二手房交易数据分析与预测平台,集成了数据采集、清洗、存储、可视化和智能预测功能。系统采用分层架构,通过Flask后端和ECharts前端实现房源数据的多维度分析展示,包括价格趋势、区域对比、户型分布等可视化图表,并集成CatBoost回归模型进行房价预测。项目亮点在于构建了端到端的数据处理链路,从原始数据清洗到MySQL存储,再到Web系统交互展示,形成了"数据-分析-

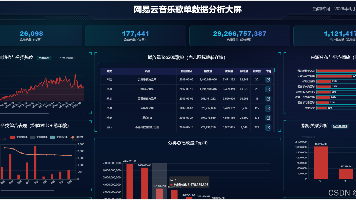
本项目基于网易云音乐歌单数据构建完整分析系统,涵盖数据采集、清洗、离线计算到可视化全流程。通过爬虫获取歌单信息及用户评论,经Hive实现多维度离线分析(分类热度、时间趋势、歌曲排行等),结合文本挖掘提取评论关键词与情感倾向。前端采用Flask+ECharts构建可视化大屏,展示播放量、收藏量等核心指标及评论词云、LDA主题等深度分析结果。系统突出数据工程完整性,提供可扩展的分析框架,适合作为音乐内
本项目基于Hadoop生态系统构建农产品价格数据分析平台,通过多源数据采集、分布式存储和Spark分析,实现价格趋势预测与区域差异分析。系统采用六层架构,包含数据爬取、HDFS存储、Spark预处理、多维分析及ECharts可视化模块,支持农民种植决策、企业市场布局和政府政策制定。平台显著提升农业数据时效性,推动智慧农业发展,已通过热力图、趋势图等形式验证分析效果。完整代码与部署方案可联系作者获取
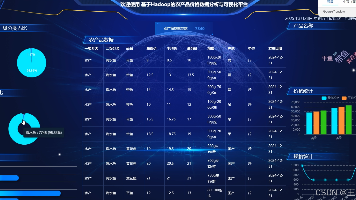
最近整理了一个网络图书数据分析与可视化项目,整体思路是把图书平台上分散的书目信息、评分信息、价格信息和简介文本统一采集下来,再经过清洗、入库、统计分析和可视化展示,最后形成一个可以登录访问、可以切换图表、可以查看大屏的完整系统。价格和口碑有没有明显关系?真正的信息采集发生在详情页:书名、作者、出版社、出版年、页数、定价、评分、评价人数、五星到一星比例、封面链接、详情链接、简介文本等字段都会按页面位

本文介绍了一个完整的图书电商数据分析系统项目,该项目围绕文轩网图书数据,实现了从数据采集、清洗、存储到分析、可视化和价格预测的全流程。系统采用Python爬虫获取数据,经过标准化清洗后存入MySQL,通过Flask+Layui搭建Web平台,集成Pyecharts/ECharts可视化图表和CatBoost价格预测模型。项目亮点包括:两阶段爬虫设计、字段规范化处理、CSV+MySQL双存储方案、2
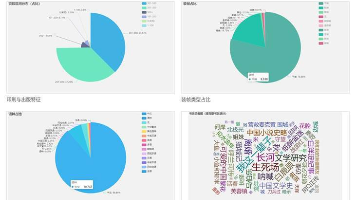
《重庆二手房房价分析与预测系统:从数据采集到Web应用的全流程实现》 摘要:本项目构建了一套完整的重庆二手房市场分析预测系统,通过两阶段爬虫采集链家平台数据,经数据清洗和特征工程处理后,实现多维度可视化分析与机器学习预测。系统整合Pyecharts图表展示、XGBoost模型预测(R²=0.835)和Flask框架的Web应用,包含数据大屏、在线估价和后台管理功能。项目亮点包括:1)针对山地城市特
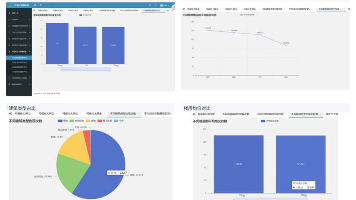
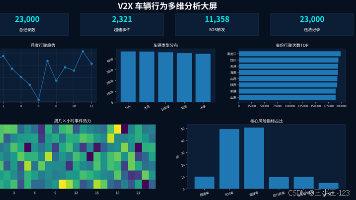
摘要: 本文介绍了一个车联网数据聚合与可视化分析平台,整合了车辆运行数据、异常事件、违法行为等多源数据,实现了数据清洗、统计分析、风险聚类及可视化展示功能。系统采用Flask+MySQL+Layui技术栈,支持用户管理、数据维护及大屏驾驶舱展示,通过ECharts生成多维图表(如趋势图、热力图、风险画像)。项目亮点在于完整的分析链路(数据预处理→聚类建模→可视化)和直观的交互界面,适用于智慧交通、