登录社区云,与社区用户共同成长
邀请您加入社区
享元模式是一种结构型设计模式,通过共享对象来有效支持大量细粒度对象。它将对象状态分为内部状态(固定可共享)和外部状态(可变不可共享),通过享元工厂管理共享对象。该模式适用于对象数量多且相似的情况,能显著减少内存占用和对象创建开销,但会增加系统复杂度。文中以围棋棋子为例展示了代码实现,并对比了单例、原型等模式,指出其核心优势在于对象复用。Java的Integer缓存机制是典型应用。
本文系统阐述了不可变对象与享元模式在并发编程中的应用。首先详细解析了不可变对象的定义、线程安全原理及实现规范,重点介绍了保护性拷贝技术及其在JDK中的典型应用。其次深入探讨了享元模式的核心概念、设计原则和实现方法,包括在JUC中的实际应用案例。最后通过一个极简连接池的完整实现,展示了如何基于BlockingQueue等JUC组件构建线程安全的资源池,详细说明了连接获取、归还及关闭的核心流程。文章强
前言:享元模式(Flyweight Pattern)是Java设计模式中最实用的“内存优化神器”之一,属于结构型模式,核心是“通过共享技术复用大量细粒度的相似对象,减少对象创建数量,降低内存占用”。很多Java开发者在面对高并发、大量重复对象的场景(如游戏棋子、字符串常量、数据库连接池)时,容易写出“创建大量重复对象”的臃肿代码,导致内存飙升、系统性能下降;面试时被问到“享元模式的核心是什么”“J
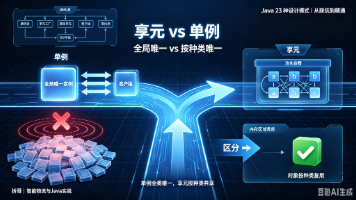
摘要:单例模式和享元模式都能减少对象创建、节约内存,但单例保证的是“全类唯一实例”,享元实现的是“每种内部状态一个共享实例”。本文从文本编辑器字符共享和数据库连接池两个场景出发,结合代码对比、UML 分析和 Integer.valueOf()、Spring 单例 Bean 等 JDK 源码,帮你彻底分清这对“节约资源型”模式。
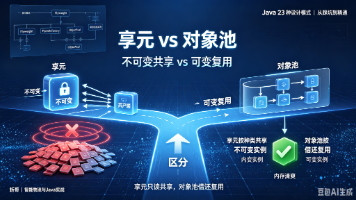
摘要:享元模式和对象池模式都能减少对象创建、节约内存,但享元的核心是不可变对象的共享——相同内部状态的客户端拿到的是同一个只读实例;对象池的核心是可变对象的复用——客户端借出、用完归还,对象状态随时变化。本文从字符共享和数据库连接池两个场景出发,结合代码对比、UML 分析和 Integer.valueOf()、HikariCP 等 JDK 源码,帮你彻底分清这对“池化型”模式。
哇哦,享元模式是不是超级厉害呀!它就像一个魔法小助手,让你的程序变得更加高效和优雅。下次写代码的时候,不妨试试这个 “内存小管家”,让你的程序在内存的世界里轻松奔跑吧!掘友们,赶紧去试试享元模式,让你的代码变得更加酷炫吧!😎。
与传统的for循环相比,Stream操作可以并行执行,充分利用多核处理器的优势,显著提升大数据集的处理效率。### 核心特性与优势Stream API的核心特性包括惰性求值、无状态操作和有状态操作的组合,以及强大的链式调用能力。开发者可以通过filter、map、reduce等操作快速实现复杂的数据转换和聚合,而无需编写冗长的循环代码。例如,从用户列表中筛选出活跃用户、计算订单金额总和、按部门对员
掌握基本的编译命令(如g++ -std=c++17)和调试工具(如GDB)是入门的第一步。其强大的性能、灵活的内存控制以及对多种编程范式的支持,使之成为高性能计算、游戏开发、嵌入式系统等领域的首选语言。现代C++(通常指C++11及之后的标准)引入了大量新特性,如自动类型推导、智能指针、lambda表达式等,显著提升了开发效率与代码安全性,同时保持了与C语言的兼容性。从简单的函数模板到复杂的类模板
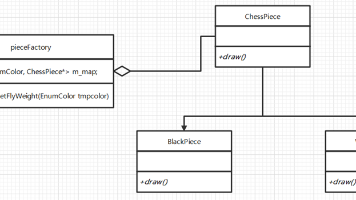
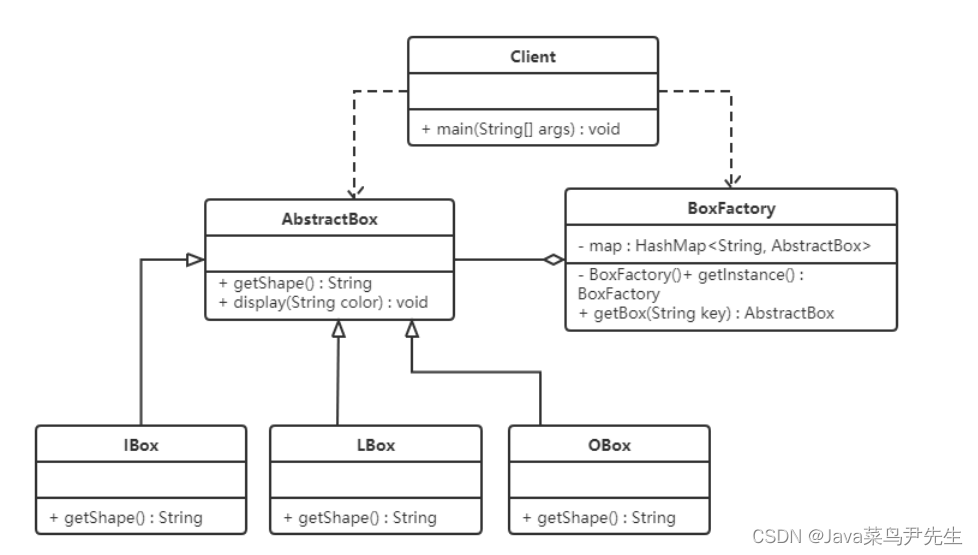
运用共享技术有效地支持大量细粒度的对象(的复用)。**内部状态:**存储在享元对象内部,一直不会发生改变的状态。这种状态可以被共享。**外部状态:**随着外部环境和各种动作因素的改变而发生改变的状态,这种状态不可以被共享。**享元模式的目的:**减少对象数量,节省内存,提高程序运行效率。享元模式的三种角色:1 抽象享元类:ChesePiece类,通常是一个接口或者抽象类。2 具体享元类:抽象享元类
享元模式是一种通过共享对象来减少内存使用和提高性能的设计模式。它的核心思想是:如果多个实例中有相同的部分,那么这部分可以被共享,而不需要为每个实例都创建一份。想象一下,如果你需要创建1000个具有相同外观的棋子对象,每个棋子只有位置不同,而外观(颜色、形状等)相同。如果不使用享元模式,你可能需要创建1000个完整的棋子对象,每个都包含外观信息。而使用享元模式后,外观信息可以被共享,只需要创建一份,
享元模式(Flyweight Pattern)是一种结构型设计模式,它通过共享技术有效地支持大量细粒度对象的复用,从而减少内存消耗和提高系统性能。这种模式特别适合当系统中存在大量相似对象,且这些对象的大部分状态可以共享的场景。
享元模式(Flyweight Pattern)是一种结构型设计模式,它通过共享多个对象中相同的部分(内部状态),来减少内存占用和对象数量,从而提高系统性能。其核心思想是:将对象的状态分为内部状态(可共享、不随环境变化的部分)和外部状态(不可共享、随环境变化的部分)。通过共享内部状态,复用已创建的对象,仅在必要时通过外部状态区分不同场景。
享元模式是一种结构型设计模式,通过共享相似对象的内部状态(如材质、款式)来减少内存占用,而将可变的外部状态(如颜色、尺寸)交由客户端维护。该模式包含抽象享元类、具体享元类、享元工厂和客户端四个角色,适用于存在大量相似对象的场景(如家具生产)。实现时需严格区分内部与外部状态,注意线程安全和工厂管理成本。合理使用享元模式能显著提升系统性能,但需权衡复用收益与管理开销。
享元模式是一种结构型设计模式,通过共享大量细粒度对象来减少内存占用。它分离内在状态(共享部分)和外在状态(上下文相关部分),适用于需要创建大量相似对象的场景(如游戏粒子、文字字符)。Python实现通常使用工厂类管理共享对象,结合不可变数据类型确保安全性。该模式可显著优化内存使用,尤其适合对象种类有限但数量庞大的应用。
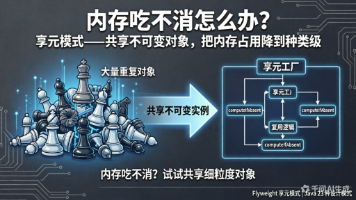
大量重复对象撑爆内存?享元模式把对象状态拆成不可变的“共享部分”和随场景变化的“外部部分”,用 computeIfAbsent 线程安全地复用实例,内存从“数量级”降到“种类级”。结合 Integer.valueOf()、字符串常量池、Record 类,一次性讲透。
享元模式是一种通过共享相同状态对象来减少内存占用的设计思想,在Java中既体现为JVM内置机制(如String常量池、Integer缓存),也需开发者在业务场景中主动实现。其核心原理是分离内在状态与外在状态,依托不可变性保障线程安全,并依赖高效缓存(如ConcurrentHashMap)实现复用。技术价值在于显著降低堆内存压力、减少GC频率,尤其适用于高频重复字段(如状态码、设备ID、类目标识)的
享元模式摘要 享元模式是一种结构型设计模式,通过共享相似对象中的可复用部分来减少内存占用。它区分内在状态(可共享)和外在状态(不可共享),将共享部分集中管理,非共享部分由调用方传入。典型应用场景如地图标记点渲染,相同类型的标记共享图标、颜色等样式信息,避免重复创建。实现包含享元对象、享元工厂和上下文对象三个关键角色,工厂负责复用控制。Java中的Integer.valueOf()就是享元模式的实例
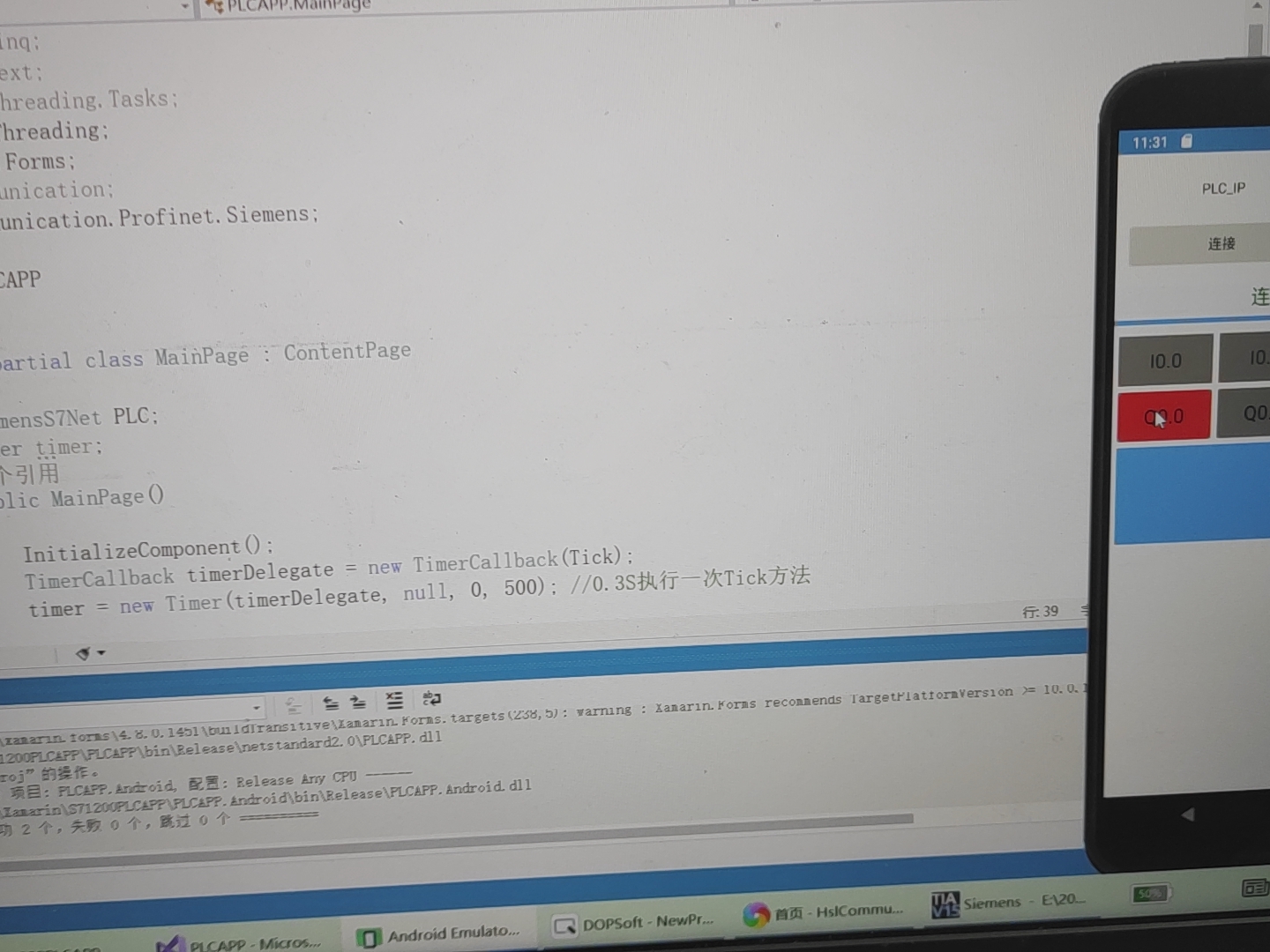
折腾两小时才发现是车间WiFi的DHCP把IP池用完了——PLC的固定IP被路由器分配给了保洁阿姨的智能手机。所以源码包里专门加了个IP冲突检测工具,这事教会我工业无线通信不仅要懂编程,还得会修路由器。这段代码里的门道在于CpuType要选对型号,IP地址得和PLC的Profinet配置一致。实测发现不同品牌的安卓机对后台服务的限制差异很大,小米得单独设置电池优化白名单,华为要允许应用自启动。1,
simulink电子节气门控制模型发动机电子节气门控制模型,有说明文档,教程。在汽车工程领域,发动机电子节气门控制对于优化发动机性能起着关键作用。而Simulink作为强大的系统建模与仿真工具,为创建高效的电子节气门控制模型提供了便利。今天咱们就来深入探讨一下这个Simulink电子节气门控制模型,并且还有详细的说明文档和教程哦。
享元模式是一种通过对象共享来优化资源利用的设计模式,特别适用于处理大量细粒度对象的场景。在实际开发中,该模式常用于图形渲染、游戏开发、缓存系统等需要高效管理资源的领域。享元模式(Flyweight Pattern)是一种结构型设计模式,其核心思想是通过共享对象来减少内存使用和提高性能。该模式通过将对象的状态分为。(不可共享的变化部分),并缓存已创建的对象,从而避免重复创建相同的对象。(可共享的不变
有效应对大规模对象场景下的资源消耗问题。其核心价值在于平衡内存占用与性能,但需注意状态划分的合理性与线程安全。在涉及高并发或资源敏感型系统(如游戏、编辑器)中,合理应用享元模式可显著提升效率,但需避免过度设计导致复杂度失控。(内部状态)来支持大量细粒度对象的复用,而可变状态(外部状态)由客户端维护,从而减少重复对象的创建。例如,在文档编辑器中,字符的字体、颜色作为内部状态共享,而位置坐标作为外部状
享元模式(Flyweight Pattern)是一种结构型设计模式,它的核心思想是通过共享对象来减少内存占用,特别适用于需要大量相似对象的场景。享元模式的基本原理是:如果一个对象实例的状态不可变,则多次创建相同实例没有必要,可以直接返回共享的对象实例。这样不仅能够节省内存,还能提高系统的性能,避免频繁地创建和销毁对象。
享元模式(Flyweight Pattern)是一种结构型设计模式,用于高效共享大量细粒度对象,从而减少内存消耗。它通过分离对象的状态为内部状态(Intrinsic)和外部状态(Extrinsic),使得多个对象可以共享相同的内部状态,而外部状态则在使用时动态传入。// 棋子接口项目描述内部状态color 字段:所有相同颜色的棋子共享该实例。外部状态Position 对象:每次调用 display
本文展示了一个使用享元模式(Flyweight Pattern)实现的树木绘制系统。项目采用Maven构建,包含核心类:TreeType(享元对象,存储树木共享属性)、TreeContext(外部状态,存储位置信息)和Tree(组合类)。ColorType枚举定义了树木颜色类型。通过工厂模式管理TreeType对象,实现内存优化。系统可高效绘制大量树木,共享内在属性,仅保存位置等外在状态差异。代码
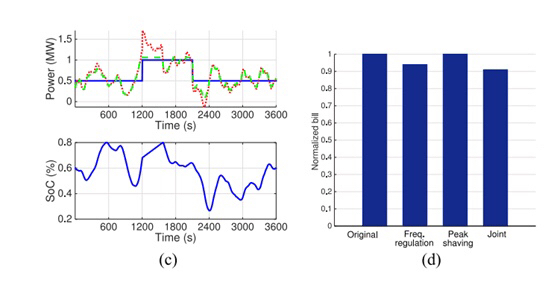
本文介绍一个基于 MATLAB 实现的储能系统联合优化模型,旨在通过储能设备同时参与电力系统的调峰(Peak Shaving)与调频(Frequency Regulation)任务,实现经济性与运行效率的协同优化。该模型利用凸优化工具 CVX 对储能充放电策略进行全局优化,综合考虑电价成本、需量电费、电池损耗以及调频市场收益与偏差惩罚,适用于楼宇级或区域级储能系统的运行策略设计。该联合优化模型为储
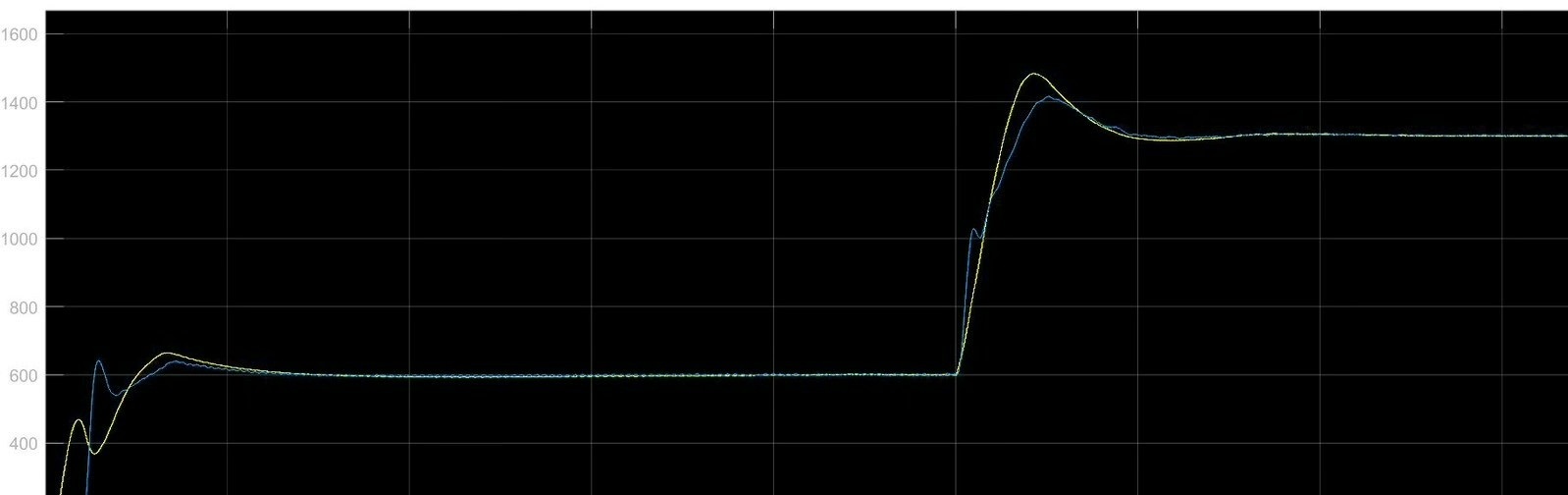
1.代码模型说明:针对手动调节PID参数困难、难以找到参数最优值的问题,首先建立了基于PID的simulink模型的评价指标,用以描述模型仿真结果的优劣,其次编写了粒子群优化代码对simulink模型中PID参数进行自动调节。1.代码模型说明:针对手动调节PID参数困难、难以找到参数最优值的问题,首先建立了基于PID的simulink模型的评价指标,用以描述模型仿真结果的优劣,其次编写了粒子群优化
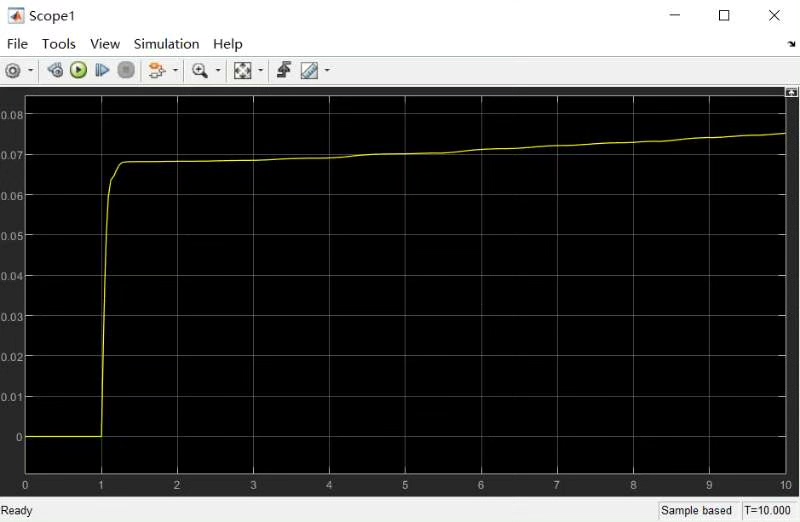
今天把Matlab2021b的仿真模型掏出来给大伙瞅瞅,这个模型最骚的操作是直接0速闭环启动——当然这属于仿真特技,真实硬件里咱还是得老老实实做开环启动。foc滑膜观测器(SMO+PLL)matlab模型,仿真里面是直接0速闭环启动的效果,当然这是仿真,应用到硬件肯定要加开环启动,目前已经在M4的硬件中实现了,效果还不错,现在出这个模型,matlab 的版本是2021b。最后给想复现的老铁们提个醒
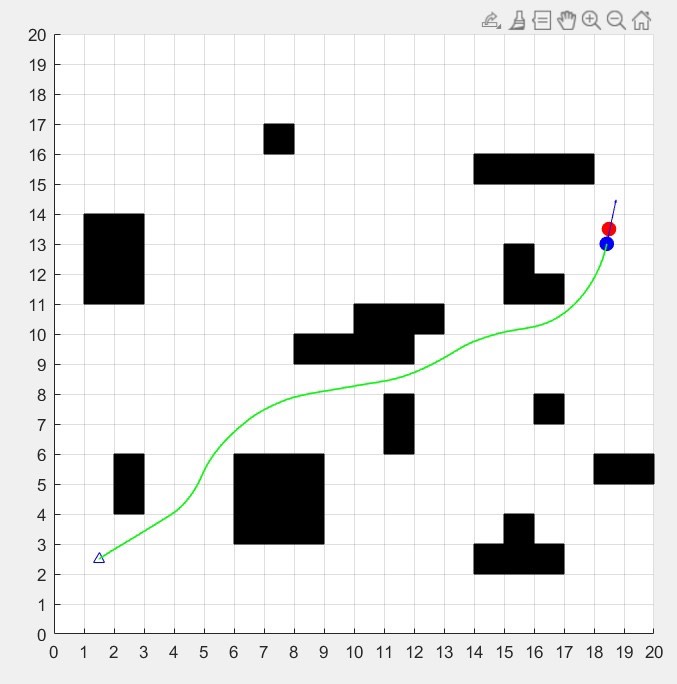
目标距离(Gd):机器人当前位置与目标的直线距离,取最小值3m(距离目标过远时,权重调整逻辑趋同);目标方位角(Hd):机器人航向与“机器人-目标连线”的夹角(范围:-π~π),转化为角度(-180°~180°);障碍物最小距离(Od):机器人当前位置与所有障碍物的最小距离(范围:0~3m)。本算法通过“动态窗口采样-轨迹评价-模糊权重调整”的核心逻辑,实现了传统DWA算法的优化升级。模糊控制的引
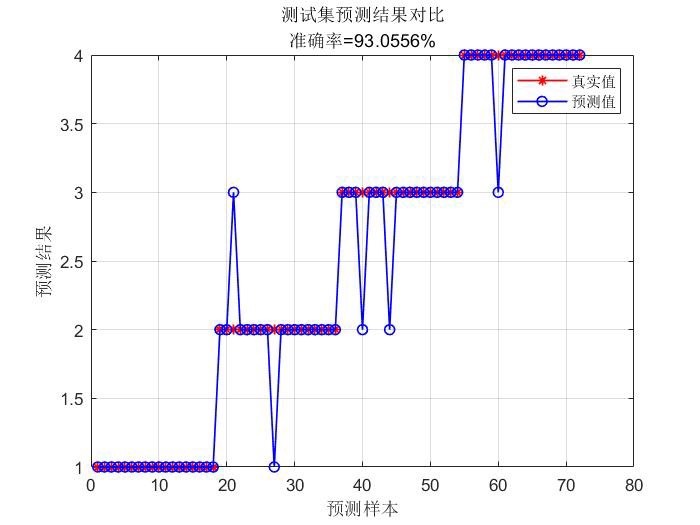
通过上面的代码示例,大家应该能很清晰地看到如何用遗传算法优化 SVM 的c和g参数来解决分类问题啦。如果是回归问题,只需要把svmtrain和svmpredict函数换成回归版本的函数,同时调整适应度函数,比如可以用均方误差(MSE)等回归评估指标作为适应度。只要按照这个框架,把数据换成你自己的,就能轻松上手解决实际的分类或回归预测问题。希望大家都能在自己的项目里用上这个方法,提升模型性能。怎么样
使用蚂蚁金服的 ant-design UI 组件库的移动端组件时,最近遇到一个问题。具体需要怎样解决呢?
比如,使用 Integer.valueOf() 方法时,实际的代码实现中有一个叫 IntegerCache 的静态类,它就是一直缓存了 -127 到 128 范围内的数值,如下代码所示,你可以在 Java JDK 中的 Integer 类的源码中找到这段代码。通常我们可以结合单例模式来设计具体享元类,为每一个具体享元类提供唯一的享元对象。五子棋中有大量的黑子和白子,它们的形状大小都是一样的,只是出
享元模式(Flyweight Pattern)是一种结构型设计模式,它主要解决的问题是创建大量相似对象时的内存开销问题。该模式通过共享具有相同状态的对象来减少内存使用量。享元模式的思想是:当需要创建一个新对象时,首先检查是否已经存在具有相同状态的对象。如果存在,则返回已经存在的对象,否则创建一个新的对象。因此,如果要创建多个具有相同状态的对象,可以重复使用相同的对象,从而减少内存开销。通过运用共享
在开发过程中,我们经常会遇到创建大量具有相似属性的对象的情况。比如:在一个图形编辑器中,可能有成千上万的小图标或文字字符;在一个游戏中,可能有大量的敌人、子弹等重复元素。如果每个这样的对象都独立存储其所有信息,将会占用大量的内存空间,并可能导致性能问题。为了优化这种情况,我们可以考虑只创建一份包含共同属性的数据副本,然后让不同的对象引用这份数据。同时,各自维护自己的独特属性。这就是享元模式的核心思
摘要:本文我们主要介绍结构型模式中的代理模式、装饰模式、外观模式和享元模式。
享元模式
——享元模式
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区




 AI Agent技术社区
AI Agent技术社区





 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 腾讯云开发者社区
腾讯云开发者社区
 AtomGit开源社区
AtomGit开源社区
 开源鸿蒙跨平台开发者社区
开源鸿蒙跨平台开发者社区





 魔乐社区
魔乐社区
 DAMO开发者矩阵
DAMO开发者矩阵

 2048 AI社区
2048 AI社区


 长沙城市开发者社区
长沙城市开发者社区


 松山湖开发者村综合服务平台
松山湖开发者村综合服务平台


 华为开发者空间
华为开发者空间
