- @Myx74270512
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
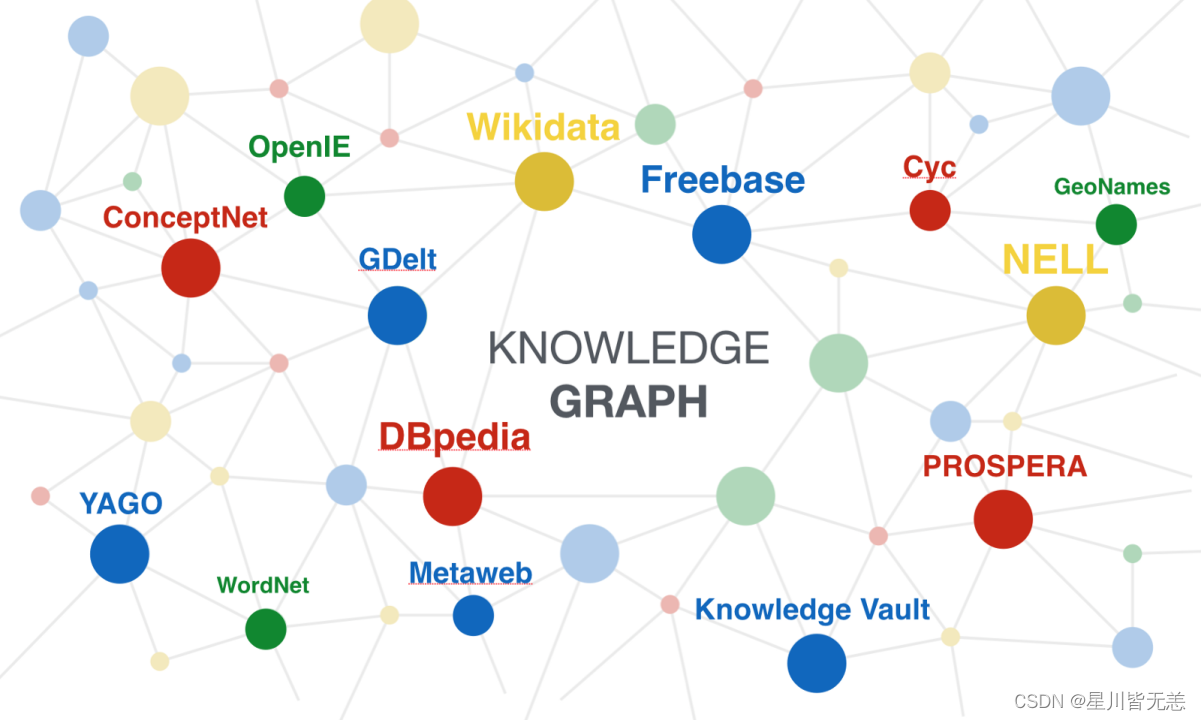
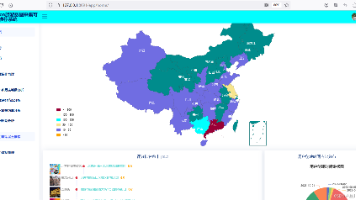
基于知识图谱的百科知识问答系统是一个面向自然语言提问场景的智能问答平台。系统以前端可视化交互页面作为入口,后端通过问题分类、实体识别、图谱查询、答案拼接与百科补全等流程,对用户输入的问题进行语义级响应等

本系统旨在通过分析电商消费者画像提出个性化服务方案,解决传统营销策略难以适配用户个性化需求的问题。技术上采用 Django+Vue 前后端分离架构,整合 Python 爬虫、线性回归算法、Echarts 等工具:以爬虫采集淘宝商品数据(类型、价格、销量等)并存储于 MySQL;通过数据挖掘构建消费者画像,借助线性回归模型预测用户购买行为;以图表、词云等可视化方式呈现分析结果。
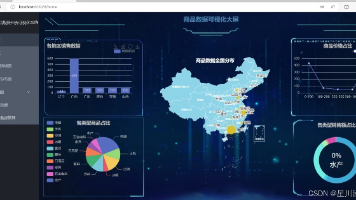
Python豆瓣电影数据分析可视化系统 这是一个完整的Python数据分析实战项目,主要包含以下内容: 项目概述 基于豆瓣电影数据,实现从数据采集到可视化展示的全流程 包含爬虫数据采集、数据清洗、统计分析、可视化展示等完整环节 适用于课程设计、毕业设计、数据分析项目等场景 技术亮点 完整数据处理流程:涵盖数据采集、清洗、存储、分析到可视化的完整链路 多维数据分析:包含电影评分、导演演员、类型地区等

本文分享一个基于 Python + Flask + MySQL + ECharts + scikit-learn实现的全国气象数据爬虫可视化预测分析系统,完整讲解项目背景、需求分析、技术选型、系统架构、数据库设计、数据采集、数据处理、图表可视化、机器学习预测、部署说明与运行效果展示。项目适合作为 **Python 项目实战、Flask 项目、数据分析可视化、毕业设计、课程设计** 参考案例,文末整

在Claude-Code项目中,部分MacOS平台用户在使用命令行工具时遇到了API返回400错误的问题。该错误主要表现为系统提示"API Error: 400"并伴随错误信息"invalid_request_error"。这类问题通常与API请求参数不合法或系统配置有关。
本项目基于Python构建了一套微博舆情数据爬虫可视化分析系统,整合了爬虫、NLP情感分析和机器学习技术,实现微博数据的实时抓取、情感分析和可视化呈现。系统功能包括:微博热词统计(年份趋势、情感分析、频率分析)、文章分析(类型占比、评论/转发量、词云)、评论分析(用户性别分布、词云、点赞)以及舆情趋势分析。采用TF-IDF特征提取和朴素贝叶斯分类器进行情感分析,并通过交互式图表展示结果,帮助用户洞
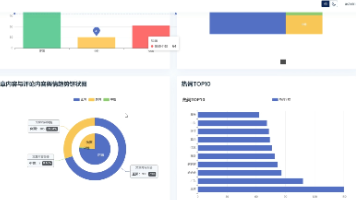
本项目设计并实现了一个基于Python的豆瓣书籍可视化分析系统,整合了爬虫数据采集、MySQL存储、Django后端开发及ECharts可视化技术。系统通过Python爬虫抓取豆瓣图书数据(书名、评分、价格等),经清洗后存入数据库,并利用Django构建Web平台,实现用户管理、数据查询及多维度可视化分析(评分分布、价格区间、词云等)。系统采用分层架构设计,支持响应式布局,兼具学术研究与实践应用价

本系统以去哪儿旅游景区信息为主要数据来源,使用 `requests` 与 `lxml` 完成景区列表、景点详情、用户评论等数据的自动采集与结构化处理,并将采集结果保存至 MySQL 数据库。在系统实现层面,本文基于 Django 搭建了旅游信息管理、用户注册登录、评论交互、数据分析展示和推荐服务等功能模块。在数据分析层面,系统围绕景区等级、地区分布、价格区间、销量情况、评论数量及评分分布等维度进行
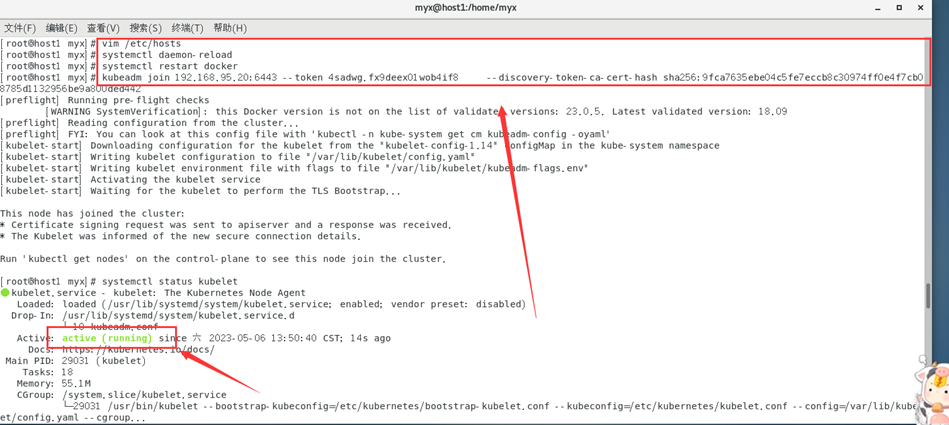
Kubernetes 集群是由多个物理或虚拟计算机组成的集合,用于运行和管理容器化应用程序。集群中的计算机被称为节点,其中包括一个主节点 (Master Node) 和多个从节点 (Worker Nodes)。在 Kubernetes 集群中,主节点负责管理和控制整个集群的操作。它运行了一系列核心组件,如 kube-apiserver、kube-controller-manager、kube-sc
知识图谱,作为人工智能和语义网技术的重要组成部分,其核心在于将现实世界的对象和概念以及它们之间的多种关系以图形的方式组织起来。它不仅仅是一种数据结构,更是一种知识的表达和存储方式,能够为机器学习提供丰富、结构化的背景知识,从而提升算法的理解和推理能力。在人工智能领域,知识图谱的重要性不言而喻。它提供了一种机器可读的知识表达方式,使计算机能够更好地理解和处理复杂的人类语言和现实世界的关系。通过构建知