登录社区云,与社区用户共同成长
邀请您加入社区
MFU(Model Flop Utilization,模型浮点运算利用率)是衡量大模型训练 / 推理效率的核心指标,用于量化硬件(如 GPU)的浮点运算能力被模型实际利用的比例。其计算原理围绕 “理论最大算力” 与 “模型实际消耗算力” 的比值展开,直接反映了硬件资源的利用效率。在深度学习领域,评估模型的计算量通常涉及到多个指标,其中MACs(Multiply-Accumulate Operati
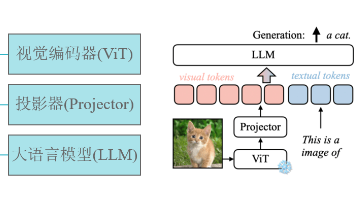
VILA 是由 NVIDIA Research 和 麻省理工学院 联合开发的一系列高性能视觉语言模型,它融合了计算机视觉和自然语言处理两大领域的技术,旨在实现更加智能和自然的图像理解和语言交互。VILA 是一种将视觉信息引入 LLM 的视觉语言模型,由视觉编码器、LLM 和投影仪组成,它们桥接了来自两种模态的嵌入。为了利用强大的 LLM,VILA 使用视觉编码器将图像或视频编码为视觉标记,然后将这
本文从宏观的角度梳理了训练的大致流程,分析了精度问题在训练流程中的表现,梳理了针对训练各环节进行相应数据采集和分析的工具。 概览图 基本概念 训练流程 概览图的上半部分展示了一个大模型训练的完整流程,从数据输入到权重更新,大体上分为以下五个部分: 准备阶段 (START 之前):左侧的“weight、dataset、env(sys env)、CANN/CUDA、config”代表训练所需的输入条件
前言本篇文章分为2个部分,第一部分主要搭建了机器人的仿真环境(ROS2 MuJoCo等),运行了机械臂及移动机器人相关示例程序;第二部分运行了OrangePi AIpro系统自带的示例程序及昇腾社区官方的示例程序;最后总结使用体验。 一、开发板软硬件 1.1 硬件介绍及准备这里我找了几块开发板,左边为
拥抱香橙派AIPro,解锁目标检测智慧算力,香橙派AIPro,由香橙派联合华为精心打造,建设人工智能新生态的高端产品,采用昇腾AI技术路线,拥有8TOPSAI算力,8GB/16GB的LPDDR4X内存
昇腾AI大模型
——昇腾AI大模型
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 脑启社区
脑启社区
 人工智能6S服务平台
人工智能6S服务平台
 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区




