




- @pae_train_group2
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
WeMM 是 WeChatCV 推出的最新一代多模态大语言模型。WeMM 具备动态高分辨率图片下的中英双语对话能力,在多模态大语言模型的榜单中是百亿参数级别最强模型,整体测评结果(Avg Rank)位居第一梯队。本文记录了将WeMM多模态大模型适配到MindIE-LLM推理框架的完整过程,迁移过程中重点解决了模型结构分析、权重转换、Embedding融合和服务化对接等关键技术挑战。
本文将系统介绍 MLP 的结构原理、核心特性、典型应用场景,并结合昇腾 NPU 的硬件优势,探讨其在实际部署中的优化路径。
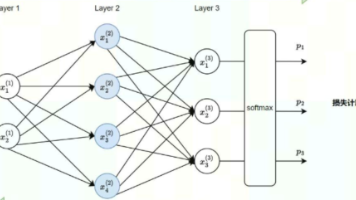
MFU(Model Flop Utilization,模型浮点运算利用率)是衡量大模型训练 / 推理效率的核心指标,用于量化硬件(如 GPU)的浮点运算能力被模型实际利用的比例。其计算原理围绕 “理论最大算力” 与 “模型实际消耗算力” 的比值展开,直接反映了硬件资源的利用效率。在深度学习领域,评估模型的计算量通常涉及到多个指标,其中MACs(Multiply-Accumulate Operati
本文基于VeRL开源框架,针对Qwen3-VL-8B模型在Atlas 800T A2硬件平台上的GRPO后训练流程,系统性地开展性能瓶颈分析与优化,通过推理与训练双路径协同调优,实现端到端性能提升30%。
昇腾实战派 * silas。
昇腾实战派 * silas。
MFU(Model Flop Utilization,模型浮点运算利用率)是衡量大模型训练 / 推理效率的核心指标,用于量化硬件(如 GPU)的浮点运算能力被模型实际利用的比例。其计算原理围绕 “理论最大算力” 与 “模型实际消耗算力” 的比值展开,直接反映了硬件资源的利用效率。在深度学习领域,评估模型的计算量通常涉及到多个指标,其中MACs(Multiply-Accumulate Operati
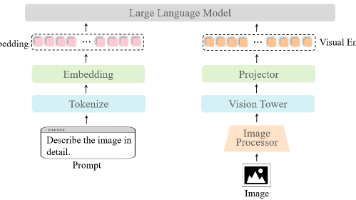
多模态大模型(Multimodal Large Language Models, MLLMs)通过整合图像、文本、语音、视频等多种信息形式,实现跨模态的语义理解与生成能力。
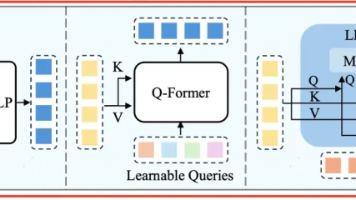
随着大模型时代的到来,训练千亿参数级别的深度神经网络对显存、计算资源和通信效率提出了前所未有的挑战。传统的单机单卡训练模式已无法满足需求,分布式训练成为主流。然而,数据并行带来的显存冗余、流水线并行的高通信开销等问题严重制约了训练效率。在此背景下,DeepSpeed作为由微软开源的高性能深度学习优化库,凭借其创新的ZeRO内存优化技术、灵活的并行策略与高效的通信原语,为大规模模型训练提供了系统性解
关注公众号:AI 模力圈作者:昇腾实战派【多模态-模型基础算法】Transformer基础 【多模态-生成经典模型】T5 模型【多模态-生成经典模型】DiT原理及代码实现【多模态-生成模型实战】多模态生成强化学习框架DanceGRPO+FLUX模型部署【多模态-理解模型实战】Qwen3vl-8B基于veRL的强化学习训练适配流程【多模态-理解模型实战】Qwen2.5VL-72B模型128K长序列性