




- @BASK2311
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在 Kubernetes 中,
MyBatis 是一款优秀的持久层框架,一个半 ORM(对象关系映射)框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。

在 Node.js 项目中,使用辅助库很常见,明显这些库不会在生产环境中使用,例如如果我们使用了 test 库,在部署声到生产环境之前,移除这些不会在生产环境运行的库,减小 docker 构建的体积,也能加快构建速度。在生产环境运行并不需要开发环境的内容,优化开中各种问题,就成了开发者必须面对的一道题了,下面是我们对 Docker + Remix、Next 框架事件一些探索的总结。做选型的时候做好

为了不让大家反感,我这里只简单介绍几句话,有兴趣的朋友可以访问主页哦这里是传送门。以下是imglib已有的主要功能:Imglib是一个轻量级的 JAVA 图像处理库,立足于简化对图像的常见处理。除了生成用户头像外,还可以创建其他图像以及截取屏幕图像、从 GIF、PDF 等文档中提取图像;对图像的常见处理如缩放、裁剪、旋转、图像水印、格式转换、添加边框、马赛克、圆角、灰度化、二值化、绘制形状等;拆分

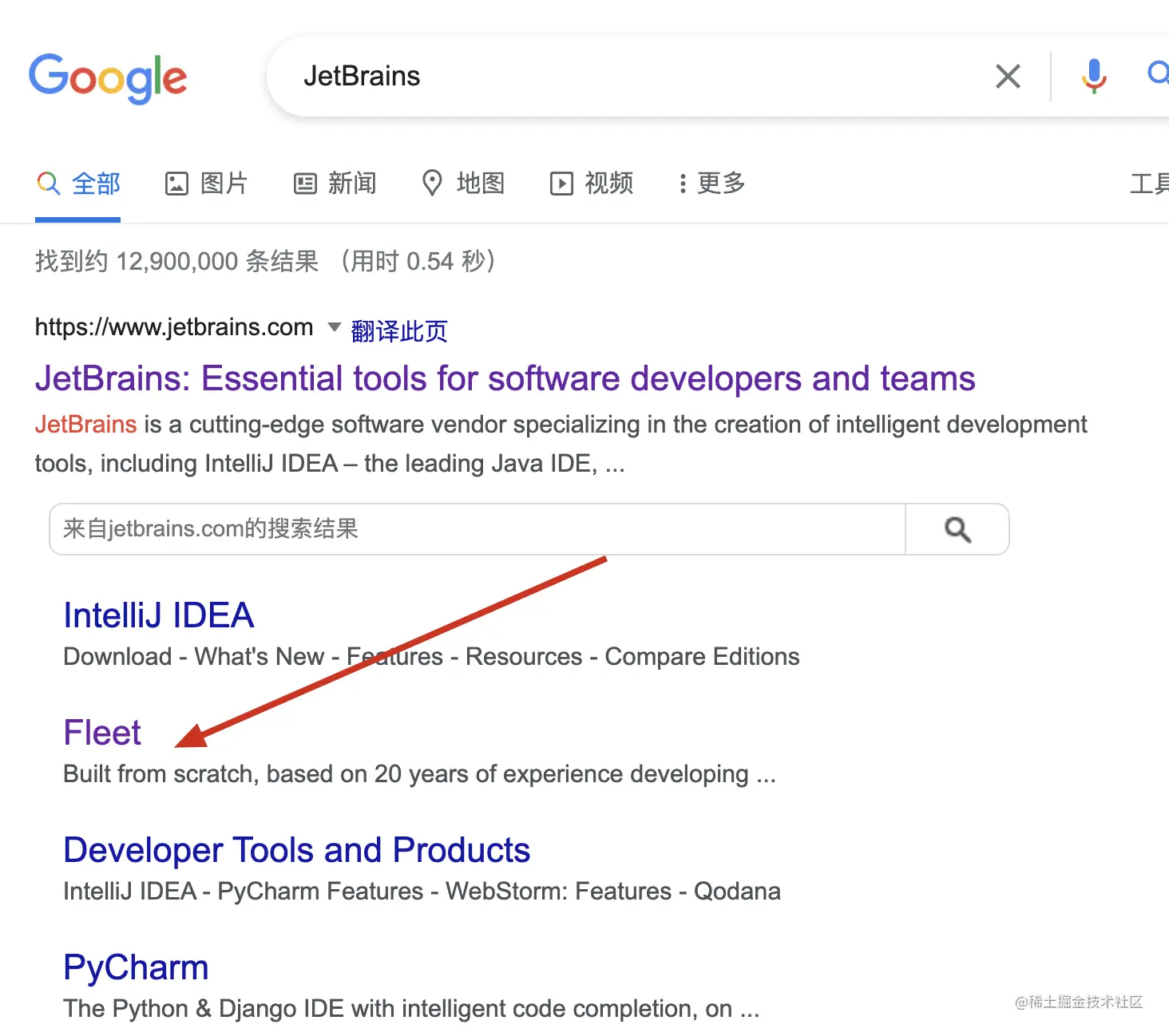
这几天,JetBrains Fleet 可以说是闹的沸沸扬扬,官方的态度很明确,我们是下一代 IDE,使用了 IntelliJ 代码处理引擎,并且是建立在 20 年的 IDE 开发经验的基础之上。听起来口气就很大,网上也是铺天盖地吹。今天我也来体验一把,看看这玩意到底能不能干掉 VScode,毕竟微软的 VScode 在轻量级这方面就是妥妥的标杆,Fleet 到底牛不牛逼,肯定是要以 VScode
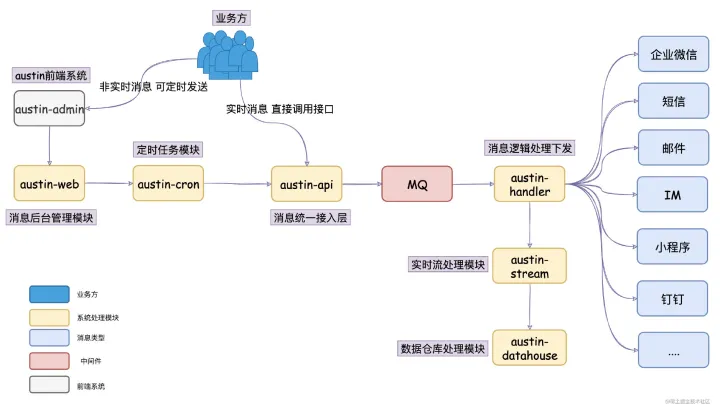
项目描述:消息推送平台承接着站内对各种类型渠道的消息下发,每天承载亿级流量推送。项目主要对用户侧的召回(营销)以及通知消息触达,也同时负责对内网的告警和通知消息发送。项目角色:项目主要负责人项目技术栈:SpringBoot、Flink、Redis、Apollo等系统设计亮点全类型渠道消息的生命周期链路追踪:在每个关键处理的阶段上进行埋点,将点位收集到Kafka,Flink统一清洗处理。实时数据写入
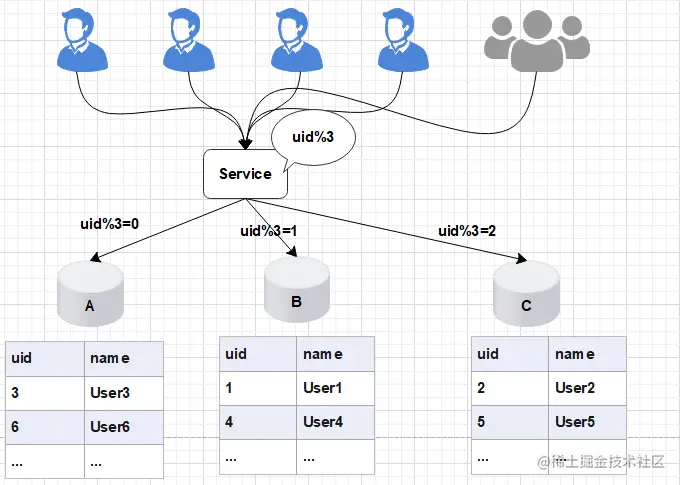
8. CMS算法的过程,CMS回收过程中JVM是否需要暂停(这块回答较好,也可以只是看毕玄的Java分布式开发或网上文章的学习, 可以结合JVM启动参数常见配置,jstat等命令,看下动手能力,意愿;比如第一个线程读取到值是3,第二个线程也读取了3,然后第一个线程+1放入了write区,第二个线程+1也放到了write区,那么两个线程的值都是4,期望值是5,这时候还是会造成并发问题。比如,第一个参

Quarkus与GraalVM的技术共振,不仅解决了Java在云原生时代的生存危机,更开创了性能与开发效率兼得的新范式。当传统框架还在追赶云原生浪潮时,Quarkus已经站在下一个技术革命的潮头,指引着Java开发者走向更广阔的云上疆域。
但是在极限情况下, 即便通过上面的数据校验处理, 也有可能出现99.99%数据一致, 不能保障完全一致,这个时候可以在旧库做一个readonly只读功能, 或者将流量屏蔽降级,等待日志增量同步工具完全追平后, 再进行新库的切换。日志增量同步过程随时可能会产生新的数据, 新库与旧库的数据追平也会是一个无限逼近的过程。修复切换异常数据:在切换过程中, 如果出现,Canal未同步,但已切换至新库的请求(
ISO/OSI参考模型和TCP/IP模型是计算机网络的两种核心架构理论。ISO/OSI模型七层架构理论完善,但实现复杂,主要用于教学和理论研究;TCP/IP模型四层架构简洁高效,基于实际需求发展,是互联网的基石,广泛应用于实际网络工程。两者互补,OSI模型为理论学习提供框架,TCP/IP模型为实践应用提供解决方案。