登录社区云,与社区用户共同成长
邀请您加入社区
本项目基于Django+Vue2开发“校园美食推荐系统”,通过Python爬虫自动采集校内餐厅评分、价格、销量数据,经Hadoop离线清洗后存入MySQL;后端用k-means对三维特征聚类,实时生成高性价、爆款、小众等标签并预测新菜名,前端Echarts可视化首页排行榜与个人收藏,学生一刷即得个性化推荐,管理后台一键更新菜品与资讯,上线后平均选餐时间缩短一半。
Java Stream API的延迟执行特性是其强大功能的核心所在,通过合理利用这一特性,开发者可以编写出既简洁又高效的代码。深入理解延迟执行的机制和优化原则,结合实际应用场景做出恰当的设计选择,是充分发挥Stream API潜力的关键。随着对Stream API理解的加深,开发者能够在保持代码可读性的同时,实现卓越的性能表现。
通过这个C++实现,我们完整地展示了K-Means聚类算法的核心思想和实现细节。K-Means虽然简单,但在实际应用中需要注意数据预处理、参数选择和算法优化等问题。核心思想:通过迭代优化质心位置来最小化簇内距离实现重点:质心初始化、数据点分配、质心更新。
std::vector`等容器的数据结构,仅当拷贝构造与移动构造均为`noexcept`时,才会调用其`exception-spec`上的操作,否则回退更安全的算法(如`reserve`预分配)。- 标记拷贝构造为`noexcept(false)`,并为容器选择`std::deque`而非`vector`(`deque`的insert扩容算法对`noexcept`依赖更低)。C++20正式弃用`t
李勃吴. 基于后验概率特征的改进无监督语音检测[J]. 信息工程大学学报, 2015.张兴明. 基于PCA的段级特征在说话人识别中的应用[J]. 电子技术应用, 2011.参考代码 基于PCA+k-means聚类的语音识别算法。
摘要:C++智能矿山调度系统通过矿石开采、运输调度、设备监控及安全管理实现高效作业。测试面临多矿区异构接口、实时性需求、复杂作业场景等挑战。采用分层自动化测试策略,包括单元测试、接口测试、集成测试等,结合GoogleTest、仿真平台等工具验证系统功能与性能。优化后测试覆盖率提升至90%,作业效率提高30%,响应时间缩短25%。CI/CD集成加速迭代,确保系统在多矿区复杂环境下的稳定运行。未来将结
摘要: C++智能建筑能源管理系统(BEMS)通过多设备协同与实时调度优化建筑能耗,其测试面临异构接口、高频调控、复杂场景等挑战。本文提出分层自动化测试策略,结合GoogleTest、协议模拟及性能压测工具,覆盖单元、接口、集成及端到端测试,并融入CI/CD流程。实践表明,该方法提升缺陷发现率35%,降低延迟25%,优化能耗效率30%,通过故障注入与数据驱动验证,确保系统高可用性与安全性。未来将进
本文介绍了基于k-means算法的校园美食推荐系统开发项目。系统采用Python语言开发,运用Scrapy爬虫技术采集校园周边美食数据(包括名称、店铺、价格、评分等),并借助Hadoop框架进行分布式存储与计算处理。后端使用Django框架搭建,MySQL数据库管理数据,实现美食信息的高效检索与个性化推荐。项目包含完整的开发流程(需求分析、设计、实现、测试)和技术路线(支持多框架扩展)。系统通过可
Python的re模块提供了强大的正则表达式功能,包括匹配、查找、替换和分割操作。关键函数对比:re.match()仅匹配开头,re.search()扫描整个字符串,re.findall()返回所有匹配结果。该模块支持替换(re.sub)、分割(re.split)等核心功能,并提供group()、span()等匹配对象方法。常用元字符包括".、*、+"等,修饰符如re.I可忽略
本文介绍了K-Means聚类中确定最优K值的两种常用方法——肘部法则和轮廓系数的Python实现。肘部法则通过SSE曲线寻找下降拐点,轮廓系数则评估聚类的内聚性和分离性。文章提供了完整的代码实现,包括数据生成、SSE和轮廓系数计算、可视化图表绘制等步骤,并针对常见问题给出解决方案。通过模拟数据集演示,直观展示了如何找到最优K值(K=4)并进行效果验证,为数据分析任务提供了实用工具。代码简洁高效,适
本文介绍了如何使用PyFlink ML的KMeans算法对二维向量进行聚类。主要内容包括:1)环境准备,需安装Java 8、Python 3.7/3.8和PyFlink ML SDK;2)代码实现步骤:创建执行环境和Table环境,构造训练数据表,配置KMeans模型参数并训练,使用模型进行预测;3)完整示例代码展示了如何将6个二维向量聚成2个簇,并输出每个向量所属的簇ID。该程序支持本地运行和集
本文介绍了三种机器学习算法的实现与应用:支持向量机(SVM)、K-means聚类和DBSCAN密度聚类。SVM部分详细讲解了线性核函数的使用、参数调优(如正则化参数C的选择)以及标准化处理和交叉验证方法。K-means部分重点阐述了通过轮廓系数确定最佳聚类数的方法,并展示了可视化过程。DBSCAN部分则强调了数据标准化的重要性,解析了邻域半径(eps)和最小样本数(min_samples)参数的影
不需要重新写一遍Python脚本去适配新客户端,也不用手动翻译成另一种语法风格——同一个网站审计技能,在不同的终端下运行,核心逻辑不变,差异仅在于调用方式微调,平台已帮你预置好各版本。点进去看描述是否匹配你的需求,确认后复制安装命令,粘贴到你的编辑器终端中执行即可。如果你常被类似的问题困扰:“这段SQL怎么加注释才能让AI准确理解意图”、“Markdown转HTML时怎样保留下划线样式”、“Git
直到有人分享了一个叫“Skills”的东西——一段能直接被AI理解并执行的专业操作指令,比如“把这段JSON自动生成TypeScript类型定义”,或者“根据Figma设计稿输出React组件代码”。回看整个过程,所谓“新基建”,未必是多酷的技术底座,有时只是提供了一种稳定可靠的连接方式——把分散的经验沉淀下来,变成别人可以踮脚就够着的小台阶。这也引出了另一个现实问题:当每个人都能快速获得一项专业
K-Means是机器学习中无监督聚类算法的核心代表,简单来说,它的目标是:把一堆没有标签的数据,按照“相似度”自动分成K个类别——相似的数据被归到同一类,不同类的数据差异尽可能大。举个直观例子:电商平台用K-Means把用户分成“高消费高频次”“低消费高频次”“高消费低频次”等群体,针对性做营销;外卖平台用它划分配送区域,优化骑手调度。核心特点:简单、高效、易落地,适合处理大规模数据;适用场景:用
宏观营收可视化快速定位渠道、时段、月度业务问题;LRFM 四维指标比传统 RFM 更全面衡量用户忠诚度与价值;无监督聚类自动完成用户分群,替代人工筛选,效率更高;分层运营能精准分配营销预算,降低获客成本、提升留存与营收。
掌握了K-Means聚类的核心原理:通过迭代优化,最小化簇内距离。学会了使用肘部法则和轮廓系数科学地确定最佳簇数K。在鸢尾花数据集上完整实现了K-Means聚类流程,并进行了可视化分析。建立了关键联系:通过将聚类结果与真实标签对比,以及将聚类特征作为输入,直观展示了无监督学习如何为监督学习提供价值。K-Means虽简单,却是理解聚类、原型学习和数据降维思想的基石。它的局限性(如需预设K、假设球形簇
KMeans划分式聚类DBSCAN密度聚类。本文基于啤酒数据集,从零实现两大聚类案例,同时讲解:轮廓系数silhouette_score怎么评估聚类效果循环遍历K值,绘制折线图寻找最优聚类数为什么DBSCAN必须做数据标准化StandardScaler新手代码高频报错点逐行解析轮廓系数silhouette_score:通用聚类评估指标,越大聚类效果越好,所有无监督聚类都可以用它打分sklearn模
摘要:本文设计并实现了一个基于Python的涉军微博舆情分析系统,重点阐述了数据爬取实现过程。研究首先通过Chrome浏览器调试端口配置和WebDriver初始化,建立高效的数据采集环境。系统采用Selenium控制远程调试模式下的浏览器,避免重复启动以提升爬取效率。该技术方案为后续的舆情数据预处理、情感分析和可视化展示奠定了数据基础,对涉军舆情监测具有实践价值。(98字)
本研究设计并实现了一个基于JSP的游戏资讯网站系统,采用JAVA语言、MySQL数据库和SSM框架。系统要求用户注册登录后使用功能,管理员可对用户信息进行全面管理。随着信息技术发展,该系统为游戏资讯提供智能化服务,改进了传统管理方式,实现了高效准确的信息管理。研究成果为游戏资讯网站系统的开发应用提供了实用参考。
本文设计并实现了一套基于Java的学士服租赁管理系统,该系统采用SpringBoot+Vue+MySQL技术栈构建,分为用户和管理员两大功能模块。用户端提供服装浏览租赁、公告查看、归还续租申请及个人中心管理;管理员端涵盖用户管理、服装信息维护、租赁订单处理、数据统计等全流程管理功能。系统通过B/S架构实现跨平台访问,采用RESTful API接口和组件化前端设计,有效提升租赁效率和管理水平。经测试
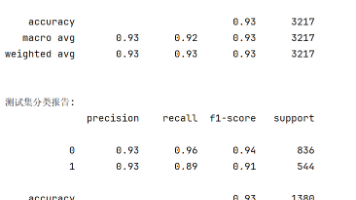
本文介绍了一套基于K-Means聚类算法的电商客户分群系统,旨在解决传统电商运营模式难以满足个性化需求的问题。系统采用Java语言开发,基于Django、Vue和MySQL构建,包含用户端、管理员端和商家端三大模块。用户端提供注册登录、商品选购、订单管理等基础功能;管理员端负责系统管控、用户管理及K-Means聚类分析;商家端则通过聚类结果优化商品策略。系统通过数据驱动的运营决策,提升了商品推荐精
K - means算法是一种常用的聚类算法,基本流程包括假设将数据分成k个cluster,从所有点中随机选k个点作为初始中心点,计算其他点与这些中心点的距离,将点划分到距离最近的簇中,然后根据簇内的点重新计算簇中心,不断重复这个过程。通过引入麻雀搜索算法对K - means算法进行优化,克服了K - means算法在初始化阶段容易陷入局部最优的问题,从而提高了图像分割的精度,能够更精确地对图像中的
摘要:乳腺肿瘤诊断数据集(Breast Cancer Wisconsin)包含569例细针抽吸样本的30个细胞核量化特征(半径、纹理、凹度等),用于良恶性分类。该数据集优势在于:1)特征与临床诊断强相关;2)提供完整预处理方案(标准化、标签编码);3)支持监督学习(线性回归预测准确率95%)和无监督学习(K-means聚类匹配率92%)。通过代码实现特征标准化、3折交叉验证和肘部法则优化,可快速构
C题:古代玻璃制品的成分分析与鉴别丝绸之路是古代中西方文化交流的通道,其中玻璃是早期贸易往来的宝贵物证。早期的玻璃在西亚和埃及地区常被制作成珠形饰品传入我国,我国古代玻璃吸收其技术后在本土就地取材制作,因此与外来的玻璃制品外观相似,但化学成分却不相同。
基于SVM与K-means的图像分割实现
kmeans
——kmeans
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区












 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 快递鸟社区
快递鸟社区


 DAMO开发者矩阵
DAMO开发者矩阵

