登录社区云,与社区用户共同成长
邀请您加入社区
}// 处理剩余元素if (batch.Any()){foreach (var processed in await ProcessBatchAsync(batch))yield return processed;与传统的IEnumerable<T>不同,IAsyncEnumerable<T>的枚举过程本身是异步的,这意味着在等待下一个元素时不会阻塞线程。C#提供了丰富的LINQ风格扩展方法,用于
后台门户则面向运营商、社区医生、家属三类角色,提供设备管理、数据可视化、报警闭环、电子围栏、用药提醒、远程固件升级等完整功能。智慧养老手表管理系统通过“SSM + Vue”的经典组合,配合 MQTT、InfluxDB、Redis、Flink 等开源组件,构建了一套高可用、可扩展、安全合规的 IoT 后台门户。模板使用 FreeMarker 渲染,支持多语言、夜间静默期。功能有:个人管理,公告管理,
安川机器人各种通讯方式,详细配置丶板卡安装及配置文件生成,有CC-linkEtherCATPROFINETEIP等等与西门子 汇川三菱等plc通讯详细案例在自动化领域,安川机器人凭借其出色的性能备受青睐。而要让安川机器人与不同品牌的 PLC 协同工作,通讯方式的选择与配置就显得至关重要。今天咱们就来深入探讨安川机器人常见的通讯方式,包括 CC - link、EtherCAT、PROFINET、EI
举个栗子,假设你手头有一段心电图信号,高频噪声和低频基线漂移混在一起,这时候直接傅里叶变换就容易翻车——小波可就不一样了,它能同时捕捉时间和频率信息,相当于给信号做了个动态CT扫描。不过别迷信默认参数,实际应用中得根据信号特征调整分解层数——比如处理脑电信号可能需要更多层级,而振动信号可能用symlets基函数效果更佳。上小波分解前得先选个合适的基函数,新手建议从db4开始,这个基函数在医疗信号处
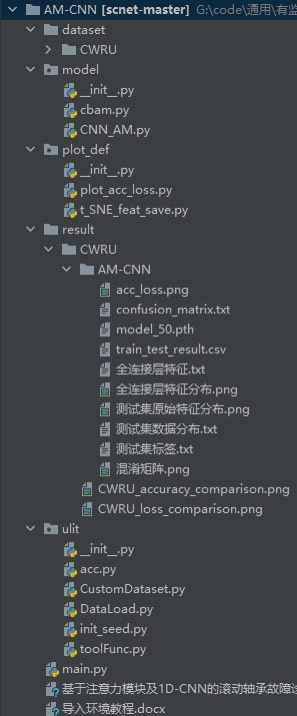
基于注意力模块及1D-CNN的滚动轴承故障诊断故障诊断代码 复现针对传统的卷积神经网络对特征的辨识性差的问题,提出一种将注意力模块与一维卷积神经网络相结合的滚动轴承故障诊断模型首先以加入噪声的振动信号作为输入,利用“卷积+池化”单元提取信号的多维特征,然后通过注意力模块对特征赋予不同的权重,利用双池化层取代传统卷积神经网络中的全连接层进行特征的再次提取及特征信息整合,最后通过 Softmax层完成
count控制采集数量,存到本地准备训练模型。有趣的是当画面里出现多人脸时,程序会疯狂保存所有检测到的人脸——得手动加个防误触机制。"这个画面在计算机实验室里被我们复现了——用Python搞了个能自动识别班级考勤的系统,比传统点名有趣多了。⑩ 信息添加功能,如: 课表添加,班级信息添加,个人信息添加(后续添加)⑩ 信息添加功能,如: 课表添加,班级信息添加,个人信息添加(后续添加)基于opencv
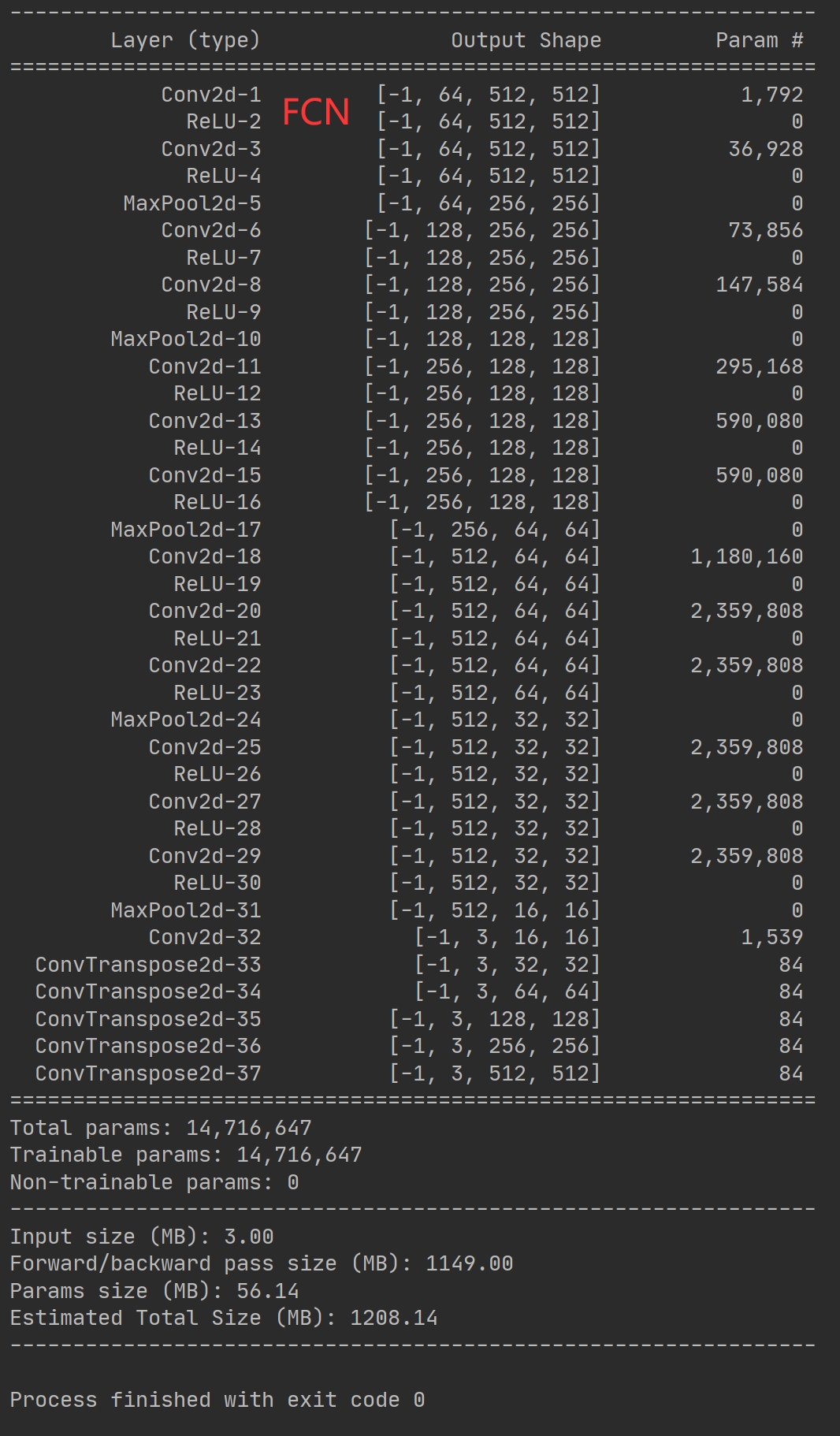
图像分割语义分割unet、 deeplab3、FCN、Resnet网络等基于pytorch框架制作全套项目,包含网络模型,训练代码,预测代码,直接下载数据集就能跑,拿上就能用,简单又省事儿在计算机视觉领域,图像分割一直是个热门话题,无论是语义分割、实例分割还是全景分割,都有着广泛的应用场景,比如医学图像分析、自动驾驶中的场景理解等。
Matlab肺结节分割(肺结节提取)源程序,也有GUI人机界面版本。使用传统图像分割方法,非深度学习方法。使用LIDC-IDRI数据集。工作如下:1、读取图像。读取原始dicom格式的CT图像,并显示,绘制灰度直方图;2、图像增强。对图像进行图像增强,包括Gamma矫正、直方图均衡化、中值滤波、边缘锐化;3、肺质分割。基于阈值分割,从原CT图像中分割出肺质;4、肺结节分割。肺质分割后,进行特征提取
本文介绍了一个基于C++和Slint开发的轻量级URDF渲染框架,旨在解决Rviz在Qt环境中渲染背景框的问题。该框架利用urdfdom解析URDF文件,通过Ogre实现STL模型渲染、光照和相机设置,并支持OpenCV图像输出。开发者提供了完整的API接口,可实时获取渲染帧图像,适用于需要轻量级URDF可视化解决方案的场景。项目已开源,欢迎使用和反馈。
Carsim 是一辆基于实际汽车的虚拟测试平台,允许开发人员在虚拟环境中进行车辆测试和验证。它提供了一个真实的车辆动态模型,可以模拟车辆在各种行驶条件下的行为。Simulink 是一种功能强大的建模和仿真工具,常用于控制系统的设计和验证。两者结合使用,可以为AEB提供一个更加逼真的仿真环境,从而更好地测试系统的性能和可靠性。通过结合Carsim和Simulink的联合仿真技术,我们可以搭建一个逼真
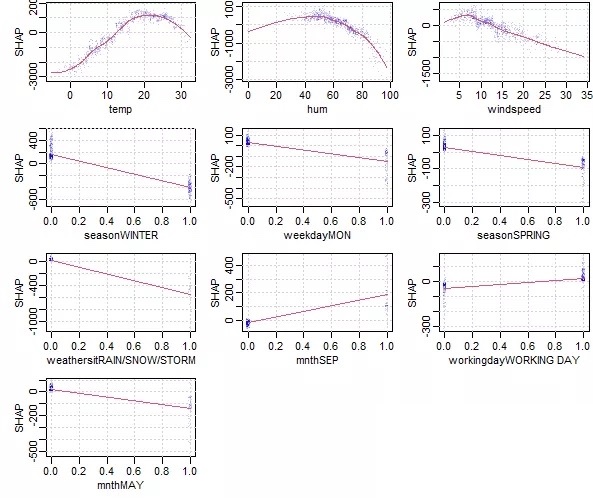
SHAP值计算与排序:对任意XGBoost或LightGBM模型,计算每个特征的SHAP值并按其重要性排序特征重要性可视化:生成特征重要性条形图,直观展示各特征对模型输出的平均影响SHAP摘要图:使用蜂群图展示特征值的分布及其对模型输出的影响方向和大小SHAP依赖图:分析单个特征与SHAP值之间的关系,揭示特征影响的潜在模式交互效应可视化:展示特征间的交互作用对模型预测的影响这套基于R的SHAP可
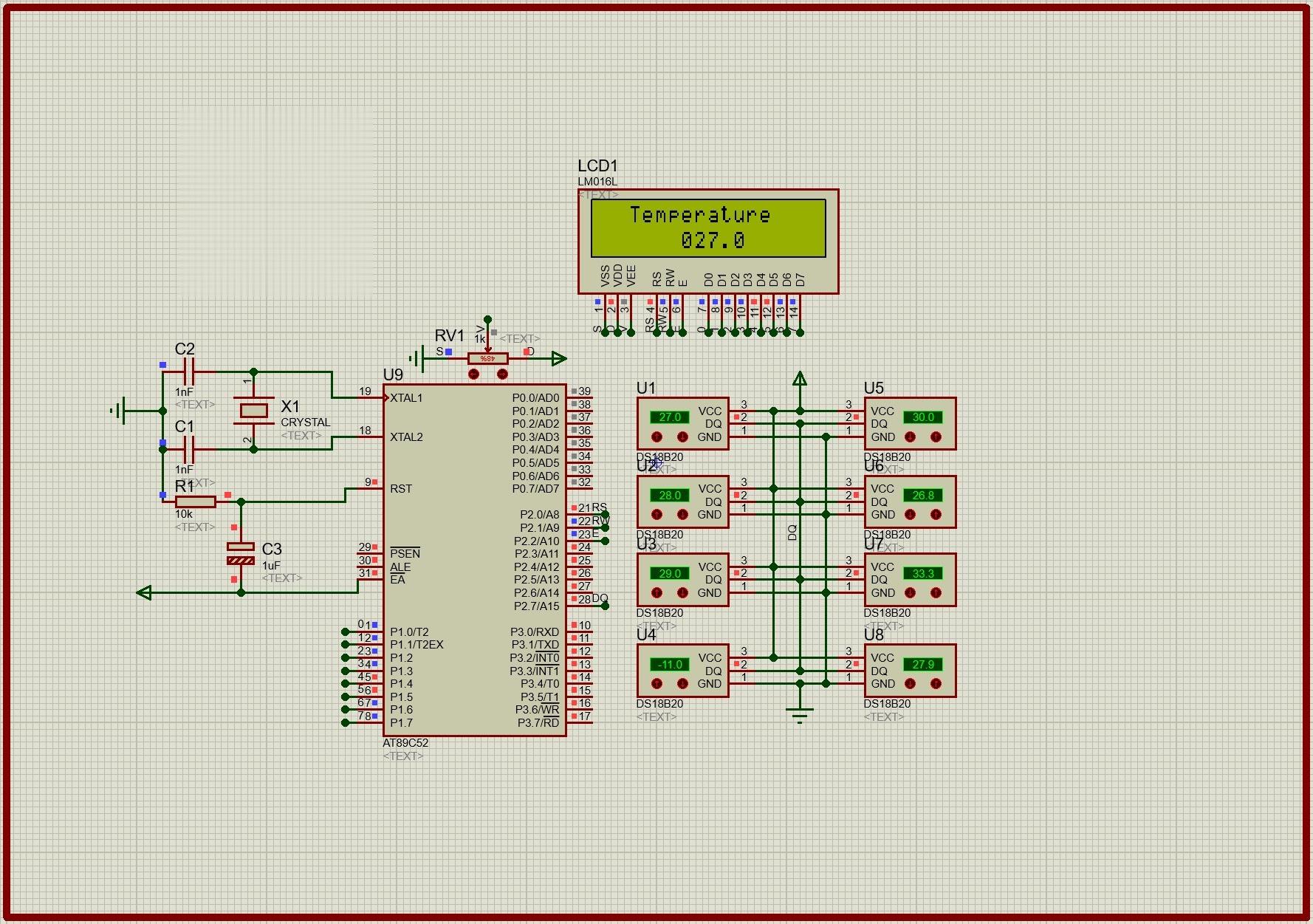
51单片机多路温度采集系统(二) C程序、proteus仿真、报告、仿真操作视频!实现对温度进行多路检测并准确显示支持LCD1602循环显示当前8组温度值最近在研究51单片机的多路温度采集系统,今天来和大家分享一下实现过程,包括C程序代码、proteus仿真,还有一些仿真操作的要点,最后也会提到报告相关内容。
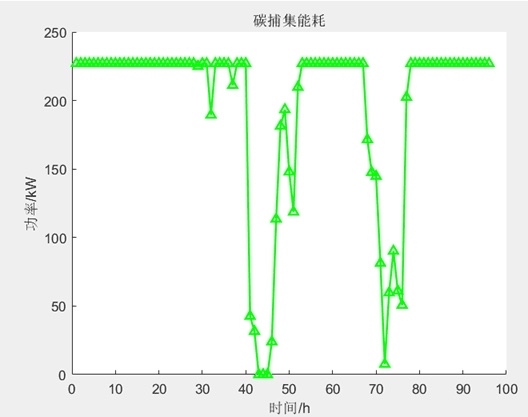
本项目基于 MATLAB 平台,构建了一个计及碳捕集电厂低碳特性与需求响应机制的电热综合能源系统多时间尺度调度模型。模型涵盖日前调度与实时调度两个阶段,通过源荷协调优化,实现系统经济性与低碳性的统一。火电机组(3台):考虑碳捕集能耗与净出力约束。燃气轮机(2台):提供电、热联供。风电机组:预测出力参与平衡。电锅炉:实现电-热转换。
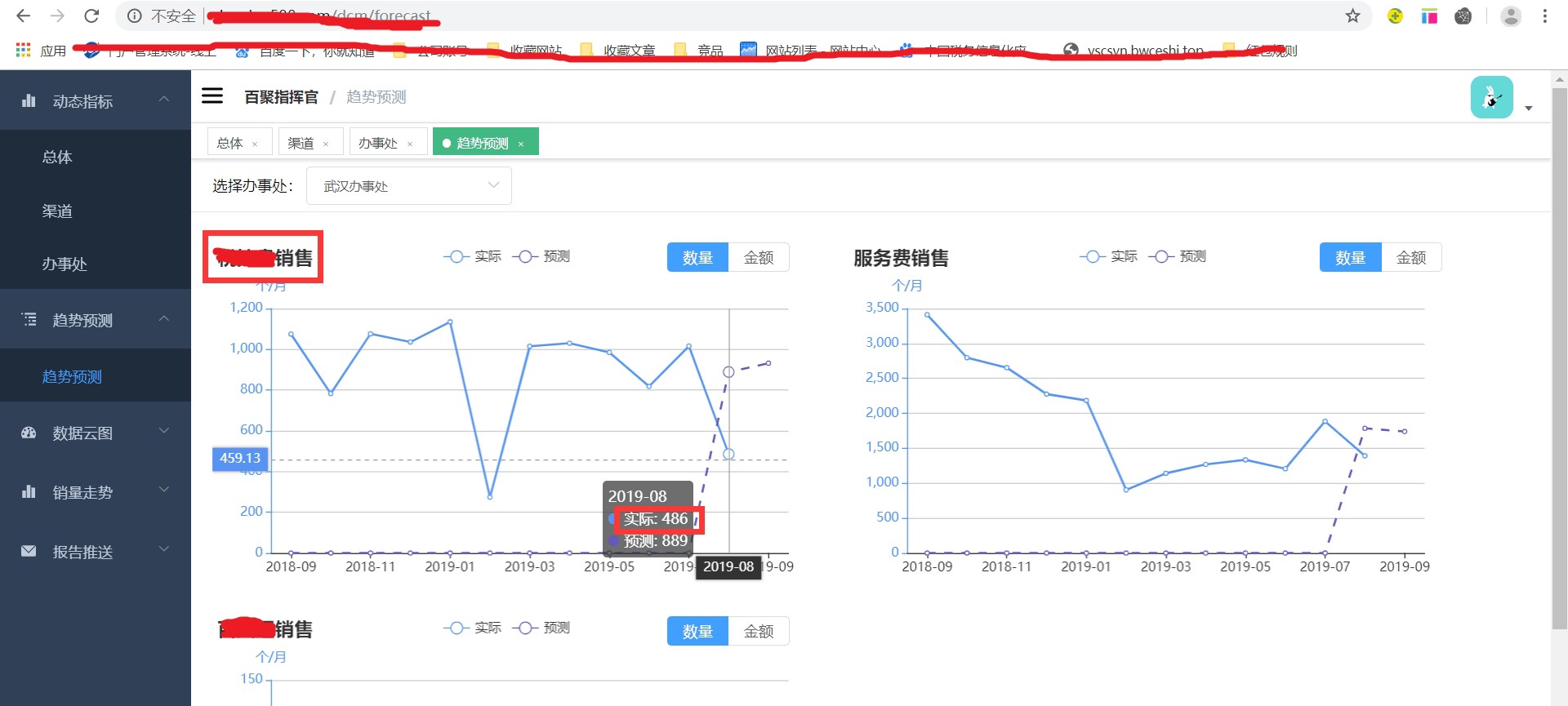
X00307-基于ARIMA时间序列的销量预测模型源码和数据集ARIMA模型提供了基于时间序列理论,对数据进行平稳化处理(AR和MA过程)、模型定阶(自动差分过程)、参数估计,建立模型,并对模型进行检验。在Python中statsmodel提供了全套的解决方案,包括窗口选择、自动定阶和平稳性检测等等算法。每月分上中下旬三个点预测,每月预测三次当月销量。这么做的好处是,月上旬和中旬的实际销量可以作为
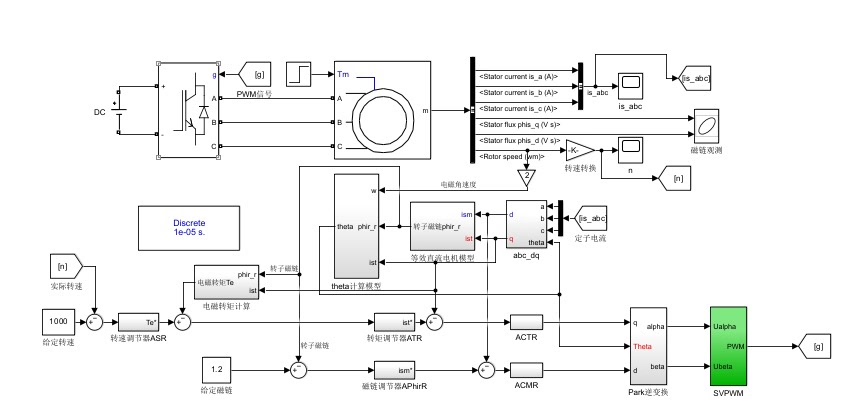
异步电机矢量控制simulink模型在电机控制领域,异步电机矢量控制技术凭借其高性能的调速能力,一直占据着重要地位。而Simulink作为强大的系统建模与仿真工具,为我们构建异步电机矢量控制模型提供了便利。今天咱就来深入聊聊这异步电机矢量控制Simulink模型。
原本用PyTorch跑一帧要15ms,优化后直接干到3ms,足够应付120Hz的实时控制需求。实测发现这个-20的碰撞惩罚值最微妙,太小了无人机会头铁硬闯,太大了又容易吓得不敢动。在仿真测试中,对比ReLU激活的版本,tanh能让突发避障的成功率提高17%左右。,这操作相当于只拿LSTM最后一个时间步的输出做决策,既保留时序信息又避免算力爆炸,实测能让推理速度提升3倍以上。而不是原始环境,因为原始
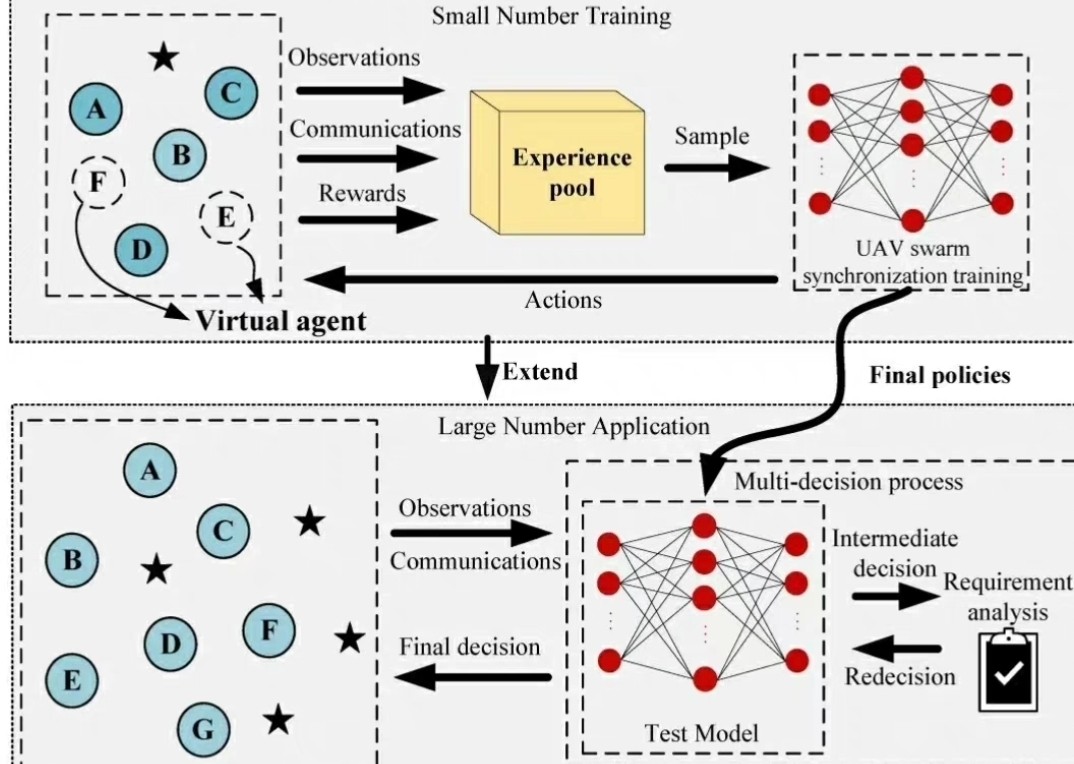
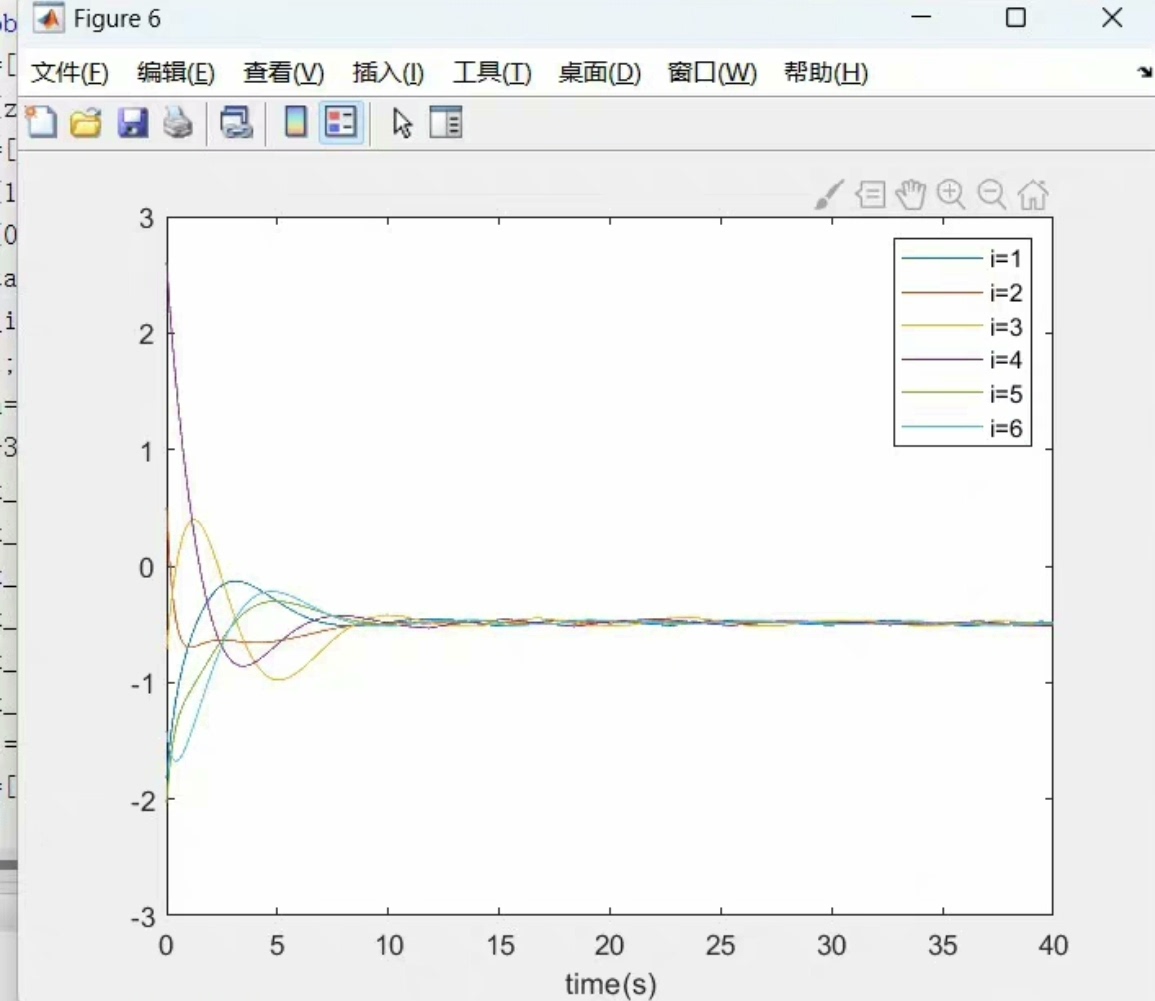
简单来说,多智能体系统一致性就是让一群智能体(比如机器人、传感器或者无人机)在没有中心控制的情况下,通过局部通信和协调,最终达到某种一致的状态。比如,所有智能体的运动速度一致,或者位置一致。这个问题在分布式计算、机器人协作等领域非常重要。通过这次研究,我对动态事件触发机制在多智能体系统一致性中的应用有了更深入的理解。动态事件触发机制不仅能够有效减少通信次数,还能保证系统的快速收敛。希望这篇博文能够
在学术江湖的刀光剑影中,期刊论文发表堪称"华山论剑"——既要选题独步天下,又要逻辑无懈可击,更要格式严丝合缝。当无数研究者困在选题迷雾、逻辑迷宫和格式炼狱中时,一款名为的智能工具横空出世,以六大核心功能构建起期刊论文写作的"六脉神剑",让学术小白也能在顶刊战场游刃有余。
本文介绍了一个基于列约束生成法(Column-and-Constraint Generation, CCG)的两阶段鲁棒优化问题的MATLAB实现。该代码构建了一个完整的两阶段鲁棒优化求解框架,通过主问题与子问题的迭代求解,有效处理不确定性环境下的优化决策问题。这个CCG算法实现展示了两阶段鲁棒优化问题的标准求解流程,通过主问题与子问题的交互迭代,有效平衡了决策的鲁棒性和经济性。代码结构清晰,模块
2025年,一个不容忽视的转折点正在发生:据某知名调研机构报告显示,AI生成式搜索(Generative Search)已占据全球搜索流量的48%以上,并预计在年内突破50%大关。这意味着,传统依赖关键词排名与静态内容优化的SEO策略,正迅速失去对用户注意力的掌控力。更严峻的是,大量企业在AI搜索结果中“集体失声”——当用户向AI提问“哪家企业能提供高效碳中和解决方案?”时,系统可能推荐了行业报告
生成式搜索不是短暂的技术风潮,而是人机交互范式的永久迁移。2025年,企业若仍停留在传统SEO思维,无异于在数字世界中自我放逐。GEO不是可选项,而是关乎品牌能否在AI时代继续“被看见、被信任、被选择”的生存命题。智小虎GEO所提供的,不仅是一套工具,更是一种面向未来的战略框架——帮助企业从被动响应转向主动塑造,在AI生成的答案中牢牢掌握品牌叙事权。当你的竞争对手还在为关键词排名焦虑时,先行者已在
我们正站在搜索范式迁移的历史节点上。未来的品牌可见性,不再取决于你在搜索结果页的位置,而取决于你是否存在于AI的答案之中。GEO优化已超越传统营销范畴,成为企业数字资产建设的底层能力。对于决策者而言,关键问题不再是“是否要布局GEO”,而是“如何高效、可持续地构建GEO能力”。依赖零散尝试或临时团队,难以应对AI生态的复杂性与动态性。唯有通过数据驱动决策、依托专业化GEO工具,才能在生成式搜索的浪
JVM通过操作系统原生线程映射实现多线程调度,每条Java线程对应一个本地线程,线程状态包括可运行(Runnable)、阻塞(Blocked)、等待(Waiting)、超时等待(Timed Waiting)和终止(Terminated)。当高并发场景引发线程数爆炸时(如每秒千万级请求),线程上下文切换会导致CPU缓存失效与高延迟。需减少线程创建开销,采用线程池复用线程。针对高并发场景,可构建分层调
本系列文章持续更新中...
glTexImage2D详细说明.参数data在上文中说有两种解释:1.当有缓冲区绑定到 GL_PIXEL_PACK/UNPACK_BUFFER 时,这时候使用了PBO(Pixel Buffer Object),此时的data是一个指向缓冲区对象数据的偏移量2.当没有缓冲区绑定到GL_PIXEL_PACK/UNPACK_BUFFER 时,这是data是指向内存中的指针(上文中提到的pBytes)
问题:OGRE - 多个窗口 - 渲染窗口和菜单窗口 我正在使用 OGRE 1.7。我想制作一个有两个窗口的应用程序,第一个渲染场景(一堆 3D 点),第二个必须呈现一组控件(按钮、下拉菜单、标签等)。我目前正在使用 SDKTrays 来组织按钮,但由于有很多控件,它们使场景变得混乱。我想将它们组织在一个单独的视图中。 谁能告诉我如何在 Ogre 中做到这一点?我无法从 OGRE 教程中弄清楚。我
问题:Libhand库编译错误使用cmake 我正在尝试在 Ubuntu 12.04 上从libhand.org构建一个手模型库。该库使用 ogre 和 opencv 库。我按照作者提供的说明成功安装了 ogre 和 opencv。不幸的是,当使用 cmake(通过命令“cmake ..”)配置 libhand 库本身时,我收到以下错误: CMake 错误:此项目中使用了以下变量,但它们设置为 N
问题:无法加载动态库 /usr/lib/OGRE/RenderSystem_GL 我正在尝试在 C++ 中运行程序,但出现此错误: terminate called after throwing an instance of 'Ogre::InternalErrorException' what(): OGRE EXCEPTION(7:InternalErrorException): Could
问题:如何从 python 获取已安装的 GDAL/OGR 版本? 如何从 python 获取已安装的 GDAL/OGR 版本? 我知道gdal-config程序,目前正在使用以下程序: In [3]: import commands In [4]: commands.getoutput('gdal-config --version') Out[4]: '1.7.2' 但是,我怀疑有一种方法可以使
ogre
——ogre
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 DAMO开发者矩阵
DAMO开发者矩阵

 脑启社区
脑启社区
 腾讯云开发者社区
腾讯云开发者社区

 AtomGit开源社区
AtomGit开源社区

 AI硬件创业社区
AI硬件创业社区

 魔乐社区
魔乐社区
 2048 AI社区
2048 AI社区







 Ubuntu
Ubuntu
 Python
Python
