




- @weixin_34910922
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文详细介绍在Ubuntu 20.04系统下配置Nginx静态资源服务器的完整流程。包括Nginx安装、常用命令操作、防火墙端口放行(16010/tcp)、配置文件编写(/etc/nginx/conf.d/img_com.conf)以及权限设置。重点说明如何通过独立alias映射实现/files/和/imgs/路径的分离访问,配置静态资源缓存策略,设置跨域访问支持,并添加安全防护措施。最后提
目录1、概述2、算法流程3、函数4、示例代码1、概述Grabcut是基于图割(graph cut)实现的图像分割算法,它需要用户输入一个bounding box作为分割目标位置,实现对目标与背景的分离/分割。Grabcut分割速度快,效果好,支持交互操作,因此在很多APP图像分割/背景虚化的软件中经常使用。2、算法流程在图片中定义含有(一个或多个)物体的矩形;矩形外的区域被自动认为是背景;对于用户
损失由两部分组成,分别是类别误差损失以及定位误差损失。1、分类损失采用一个二分类的softmax loss用来做分类,分类损失如下:其中,Sj为最后一层的softmax输出,T为类别数,yi为对应的真值标记。2、smooth L1 Loss常用的L1、L2损失定义如下:smooth L1 用来做回归,公式如下:其中x、y、w、h分别为目标的中心点及宽高,ti为真值、ui为对...

实战教程,持续更新中。
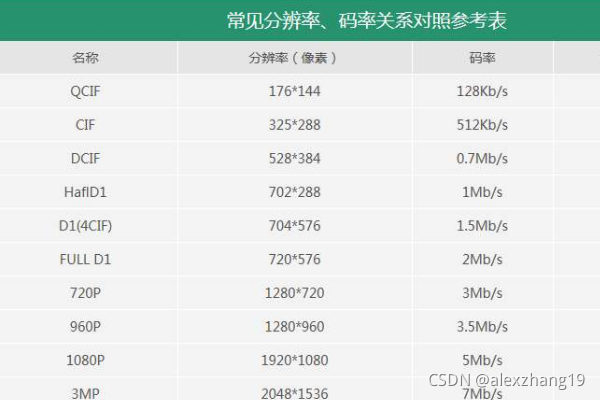
1、视频码率视频码率就是数据传输时单位时间传送的数据位数,一般我们用的单位是kbps即千位每秒。通俗一点的理解就是取样率,单位时间内取样率越大,精度就越高,处理出来的文件就越接近原始文件。但是文件体积与取样率是成正比的,所以几乎所有的编码格式重视的都是如何用最低的码率达到最少的失真,围绕这个核心衍生出来的cbr(固定码率)与vbr(可变码率),都是在这方面做的文章,不过事情总不是绝对的,举例来看,
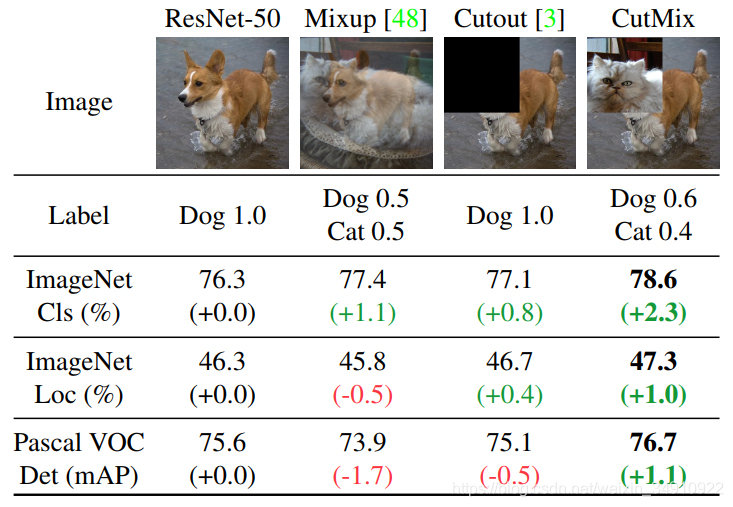
1、数据增强的作用1)避免过拟合。当数据集具有某种明显的特征,例如数据集中图片基本在同一个场景中拍摄,使用Cutout方法和风格迁移变化等相关方法可避免模型学到跟目标无关的信息。2)提升模型鲁棒性,降低模型对图像的敏感度。当训练数据都属于比较理想的状态,碰到一些特殊情况,如遮挡,亮度,模糊等情况容易识别错误,对训练数据加上噪声,掩码等方法可提升模型鲁棒性。3)增加训练数据,提高模型泛化能力。4)避
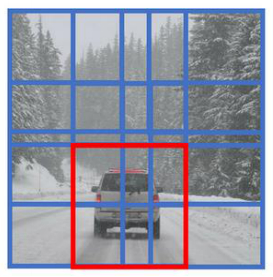
声明:本文引用吴恩达教授的DeepLearning课程内容。1、基于滑动窗口的目标检测算法首先固定一个于滑动窗口区域,然后将滑动窗口在图像上按照指定步长进行滑动,对于每一次的滑动得到区域进行预测,判断该区域中存在目标的概率。调整滑动窗口的大小、滑动步长,继续以同样的方式滑动,预测。滑动窗口目标检测算法也有很明显的缺点,就是计算成本,因为你在图片中剪切出太小方块,卷积网络要一个个地处理。如果你选用的
ubuntu系统下,常常因为国内网络原因无法访问github官网或者也无法使用使用git clone指令,搭建梯子又过于复杂,可使用修改hosts文件,添加IP地址的方法改进。3、Ubuntu上Github下载慢的问题解决方法记录(linux自带工具查看网址的DNS)2、输入github域名:http://github.com,点击检测。2、解决ubuntu无法正常访问github的问题(添加的域

VS Code官网下载地址:Visual Studio Code - Code Editing. Redefined。搜索chinese,点击install下载安装中文插件。VS Code是一个高级的编辑器,只能用来写代码,不能直接编译代码。所以,可使用 Windows平台下的一个gcc编译器MinGW-w64进行代码编译。MinGW-w64编译器套件的下载:https://sourceforge
asyncio是"多任务合作"模式(cooperative multitasking),允许异步任务交出执行权给其他任务,等到其他任务完成,再收回执行权继续往下执行。协程(Co-routine),也可称为微线程,或非抢占式的多任务子例程,一种用户态的上下文切换技术(通过一个线程实现代码块间的相互切换执行)。我们从asyncio模块中直接获取一个EventLoop的引用,然后把需要执行的协程扔到Ev