- @hooksten
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果只用一句话来定义:OpenClaw 是一个面向 Agent 的自托管网关与运行系统。这个定义比“AI 助手”更准确。原因很简单。消息入口会话路由Agent 工作区工具调用记忆系统插件扩展多 Agent 隔离安全控制所以我们说,OpenClaw 的核心不是“聊天”,而是“把 Agent 跑起来”。从官方首页的描述看,它本身是一个。
首先是安装cuda11.8。

本文详细介绍了向开源项目提交Pull Request(PR)的完整流程。主要内容包括:PR的概念说明(区分PR/MR/CR),从Fork项目到最终Merge的9个标准步骤(Fork→Clone→Branch→Code→Commit→Push→PR→Review→Merge),以及分支命名规范、Commit Message规范、PR描述模板等重要细节。文章还提供了代码同步、处理Review反馈等实用
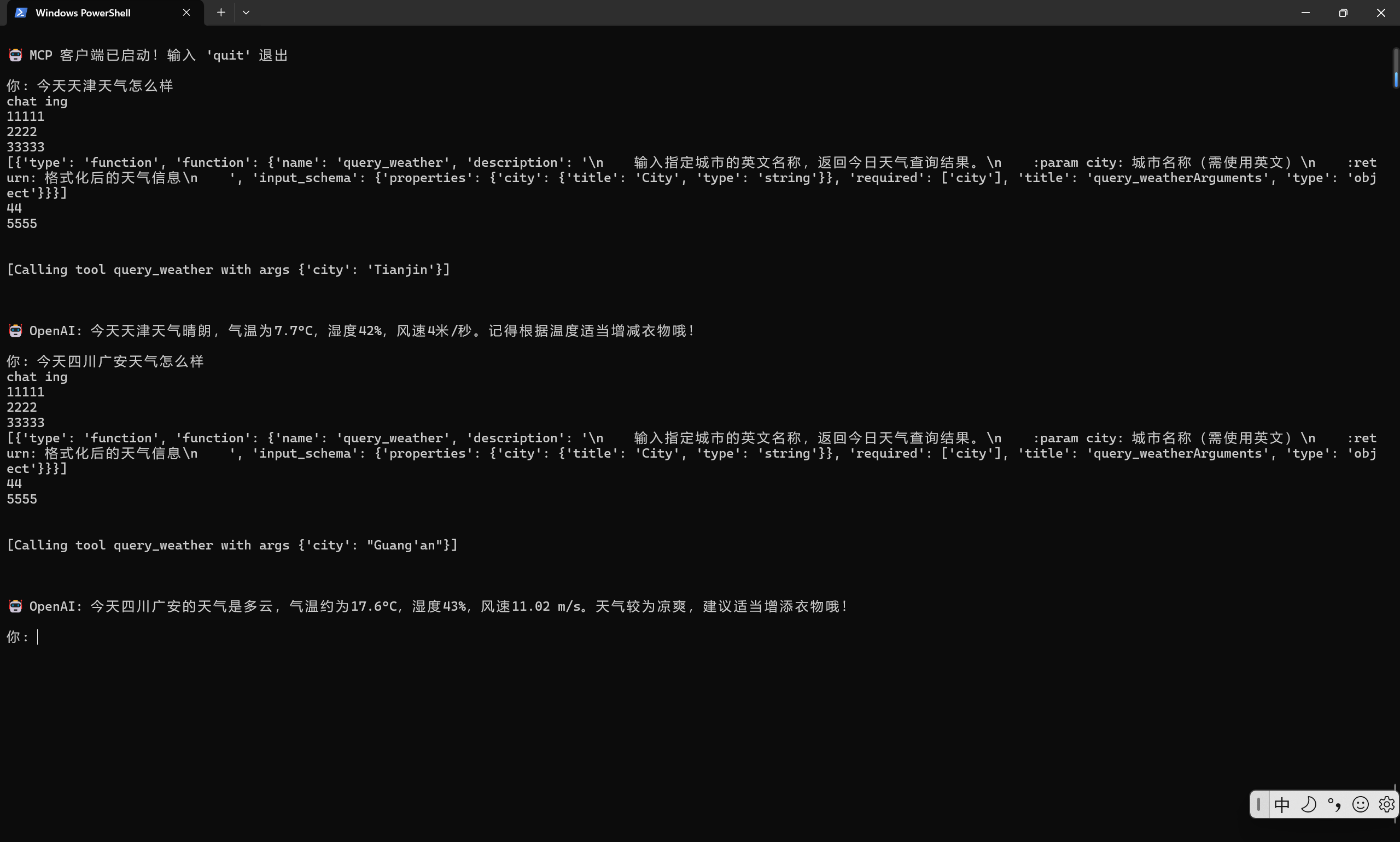
在使用Ollama进行AI模型管理时,有时需要根据实际需求更改模型文件的存储路径。本文将详细介绍如何在Linux系统中更改Ollama模型的下载路径。在新的路径/data/ollama/models下,会看到生成了blobs和manifests文件夹,这表明模型路径已经成功更改。进入默认的模型路径/usr/share/ollama/.ollama/models,会发现models文件夹已经消失。在

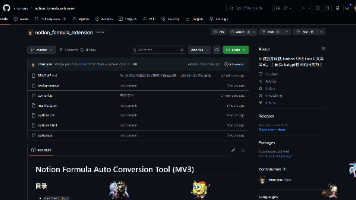
摘要:一款AI浏览器插件能自动识别Notion中的伪LaTeX公式文本,并将其转换为可渲染的数学公式。该插件采用AI识别+本地补漏策略,克服了传统正则表达式难以处理复杂公式的问题。用户只需加载插件并输入API密钥,即可一键转换文档中的公式文本。项目结构清晰,适合需要频繁处理技术文档、研究笔记的用户和团队,能有效提升公式转换的准确性和效率。(150字)
我最近的工作流变成了这样:一个 Claude Code 跑前端重构,一个跑后端接口对接,一个 Gemini 在旁边做 code review,还有一个 Codex 在尝试某个不确定的实验方向。再加两个终端窗口跑测试和部署。这还没算上那些我忘了关的。问题不是"能不能开这么多窗口"——tmux 当然能。问题是你根本不知道哪个 agent 正在等你回复、哪个已经卡死了、哪个其实三分钟前就做完了在空转。你
决策大模型作为新一代人工智能的底层技术,能够赋能智能体(AI agent)在数字世界做出有效决策,也能助力具身机器人在物理世界实现有效决策。它不仅推动了智能体在复杂环境中的自主决策能力,还为多领域应用提供了新的技术思路。

MCP,即Model Context Protocol(模型上下文协议),是由Claude的母公司Anthropic在2024年底推出的一项创新技术协议。在它刚问世时,并未引起太多关注,反响较为平淡。然而,随着今年智能体Agent领域的迅猛发展,MCP逐渐进入大众视野并受到广泛关注。今年2月,Cursor宣布正式支持MCP功能,这无疑为MCP的推广按下了加速键,使其迅速走进了众多开发人员的视野。从
windows下卸载ollama基本上直接选中就可以卸载了,主要是怎么在ubuntu环境中卸载羊驼,这里主要通过命令行来实现。
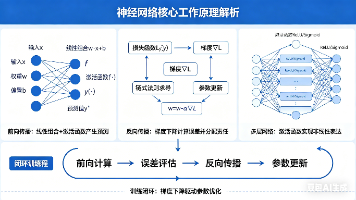
本文深入浅出地阐述了神经网络的核心工作原理。文章首先通过单神经元模型引入权重(w)和偏置(b)的概念,解释了前向传播如何通过线性组合和激活函数产生预测值。然后重点剖析了反向传播机制,说明梯度下降如何通过损失函数计算误差,并利用链式法则将误差责任反向分配给各层参数。文中通过具体数值示例,生动展示了参数更新的数学过程,阐明了学习率的作用。最后扩展到多层网络结构,强调激活函数对非线性表达能力的关键作用,