登录社区云,与社区用户共同成长
邀请您加入社区
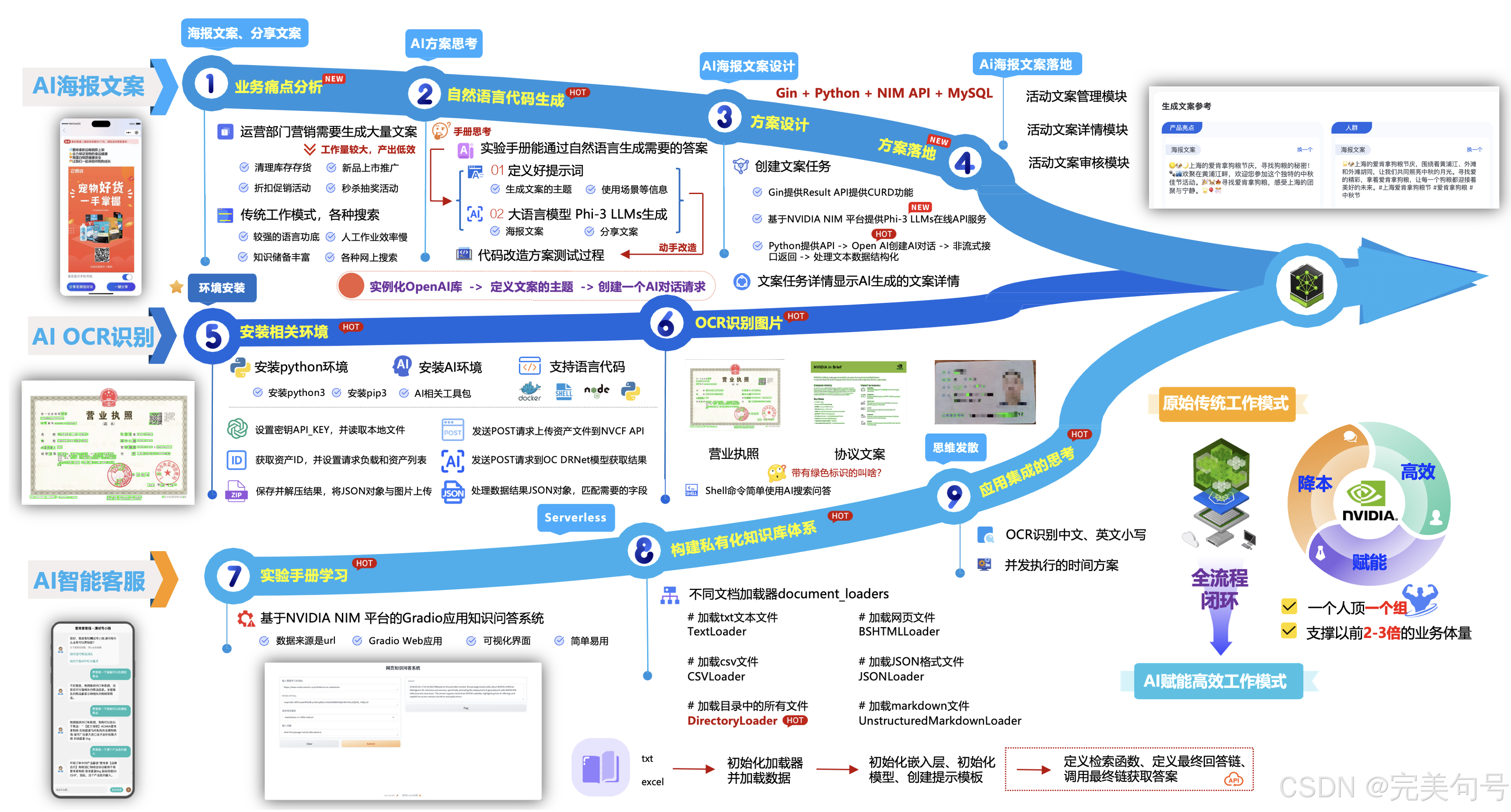
大模型推理服务正从云端调用转向本地化、标准化、工程友好的基础设施形态。其核心原理在于将模型封装为OpenAI兼容的HTTP API微服务,依托GPU原生优化(如TensorRT-LLM)实现低延迟、高吞吐、免编译的确定性推理。技术价值体现在显著降低70B级大模型在Ubuntu/Debian环境下的部署门槛,规避llama.cpp编译失败、nvidia-smi通信异常、驱动版本冲突等高频工程痛点。典
大模型本地化部署正从‘能跑’迈向‘稳用、好管、可生产’的新阶段。NVIDIA NIM(NVIDIA Inference Microservices)作为面向AI服务的标准化交付范式,通过硬件感知编译、OpenAI兼容API封装、GPU资源硬隔离等机制,显著降低高性能推理服务的工程门槛。它不是普通Docker镜像,而是预优化、可运维的微服务单元,天然适配DeepSeek-V4等MoE架构模型,在RT
AI推理服务是大模型落地的核心环节,其本质是将训练好的模型封装为标准化、可观测、可运维的HTTP API服务。NVIDIA NIM(Inference Microservice)作为企业级推理运行时,提供硬件感知优化、OpenAI兼容协议与内置服务治理能力;OpenClaw则通过声明式YAML编排实现健康驱动的服务依赖调度与资源约束。二者结合,使开发者无需接触模型权重即可在本地GPU(如RTX 4
大模型本地化推理是保障数据安全、降低延迟、提升可控性的关键技术路径。其核心原理在于将开源模型封装为标准化微服务,依托GPU加速引擎(如TensorRT-LLM)实现高性能、低开销的端侧或工作站级运行。技术价值体现在离线可用、API兼容、生产就绪三大维度,广泛应用于金融合规推理、代码辅助开发、私有知识问答及智能体构建等场景。本文聚焦DeepSeek-V4与NVIDIA NIM推理框架的深度协同,结合
Stream Ordered Memory Allocator是一种基于CUDA流(stream)的内存分配机制。它允许开发者在特定的CUDA流中分配和释放内存,从而确保内存操作的顺序性与流的执行顺序一致。这种机制特别适用于需要频繁分配和释放内存的应用程序,例如深度学习推理、图像处理等。传统的CUDA内存分配(如cudaMalloc和cudaFree)是全局的,不依赖于任何流。这意味着内存的分配和
本文详细介绍了NVIDIA NIM微服务在边缘计算中的实战部署,特别针对Jetson设备进行了优化。通过轻量化容器、硬件感知优化和离线推理能力,NIM微服务显著降低了内存占用和推理延迟,提升了能效比。文章提供了从环境准备到容器部署、性能调优的全流程指南,并展示了智慧变电站和农业无人机等典型应用场景。
本文介绍了使用LiteLLM统一接入NVIDIA NIM模型(如GLM、DeepSeek、Kimi等)的完整方案。主要内容包括: 整体架构:通过LiteLLM Proxy统一对接VSCode插件和多种AI模型,实现接口统一、API Key管理和多模型切换功能。 部署方案:提供Docker Compose配置,包含LiteLLM服务、PostgreSQL数据库和Prometheus监控。 关键配置:
【NVIDIA NIM】提供了强大的工具和灵活的部署选项,让生成式 AI 模型的开发和应用变得更加高效和便捷。无论您是初学者小白还是资深开发者老鸟,都可以使用NIM 都能轻松应对 AI 推理的复杂挑战,加速创新与落地,助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用。
NIM
——NIM
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 CSDN-OPC开发者社区
CSDN-OPC开发者社区

 AI Agent技术社区
AI Agent技术社区

 脑启社区
脑启社区

 腾讯云开发者社区
腾讯云开发者社区

 AtomGit开源社区
AtomGit开源社区

 智能机器人开发者大赛社区
智能机器人开发者大赛社区