- @wuyy0224
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
标签: AI什么是one-hot编码?one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。假设有如下表格,记录了某网站访问者的三个信息:性别,来自,使用的浏览器:考虑以下三个特征:性别:["男","女"]来自:["北京","上海","广州"]使用的浏览器:["Firefox"," Chrom
pip 是 Python 的包管理工具,用于第三方库的查找、下载、安装、卸载等。从 Python 3.4 开始,pip 默认包含在 Python 二进制安装程序中。如果安装的 Python 版本里没有自带 pip 工具,可以通过下载 get-pip.py 文件,然后通过如下方式安装:python get-pip.py install pip运行 pip 可以通过 pip 命令,也可以用 pytho
我们在开发Flask应用程序时,通常通过运行Flask自带的Web服务器来开发测试,这个服务器提供了基本的但功能完备的WSGI服务器。但开发结束以后,在应用程序上线到生成环境时,有很多不得不考虑的事情,其中之一是我们是否应该要求客户端使用加密连接以增加安全性。人们总是问我这个问题,特别是如何在HTTPS协议上部署Flask服务器。在本文中,我将介绍几种为Flask应用程序添加加密的方案,从一个非常
标签: AI什么是one-hot编码?one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。假设有如下表格,记录了某网站访问者的三个信息:性别,来自,使用的浏览器:考虑以下三个特征:性别:["男","女"]来自:["北京","上海","广州"]使用的浏览器:["Firefox"," Chrom
本文详细介绍了Gunicorn的安装使用以及各个配置参数的含义。希望对读者朋友们有所帮助。针对这些的学习还是看官方文档最好。
示例: 假设容器名为testtomcat,要从容器里面拷贝的文件路为:/usr/local/tomcat/webapps/test/js/test.js,现在要将test.js从容器里面拷到宿主机的/opt路径下面,那么命令应该怎么写呢?示例:假设容器名为testtomcat,现在要将宿主机/opt/test.js文件拷贝到容器里面的/usr/local/tomcat/webapps/test/j
这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是"进程时间",它是用秒表示的浮点数(时间戳)。而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。1毫秒=1000微秒)作为浮点数,即具有最高可用分辨率的时钟,以测量短持续时间。建议PC上使用time.perf_counter() 来计算程序的运算时间,特别是测试算法在相邻两帧的处理时间,如果计算不准确,那可能会对算法的速
简介: 逻辑回归是分类当中极为常用的手段,它属于概率型非线性回归,分为二分类和多分类的回归模型。对于二分类的logistic回归,因变量y只有“是”和“否”两个取值,记为1和0。假设在自变量x1,x2,……,xp,作用下,y取“是”的概率是p,则取“否”的概率是1-p。逻辑回归是分类当中极为常用的手段,它属于概率型非线性回归,分为二分类和多分类的回归模型。对于二分类的logistic回归,因变量y
前言在做一个使用matplotlib画函数图像的作业的时候遇到了一个问题。如题所示的报错让我纳闷了很久。然而在一个随意的更改之后竟然解决了问题,于是我稍微探究了一下问题所在。问题的出现我的报错代码如下:import matplotlib.pyplot as pltfrom numpy import*from math import*plt.figure(figsize=(6,6))wh=hh=6/

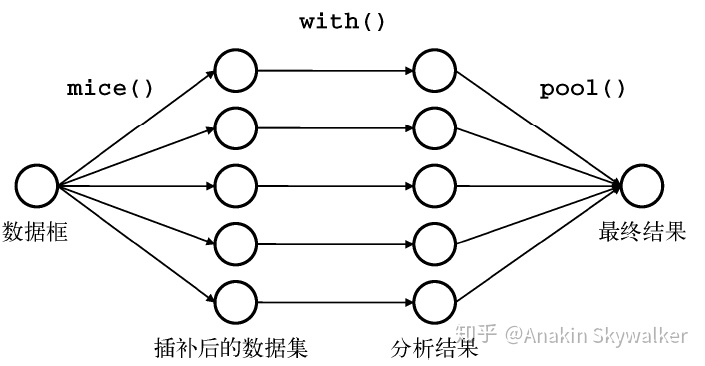
插补法可以在一定程度上减少偏差,常用的插补法是热卡插补、拟合插补和多重插补。拟合插补,要求变量间存在强的相关性;多重插补(MCMC法),是在高缺失率下的首选插补方法,优点是考虑了缺失值的不确定性。热卡填充(Hot deck imputation)也叫就近补齐,对于一个包含空值的对象,热卡填充法在完整数据中找到一个与它最相似的对象,然后用这个相似对象的值来进行填充。通常会找到超出一个的相似对象,在所