




- @weixin_39636364
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
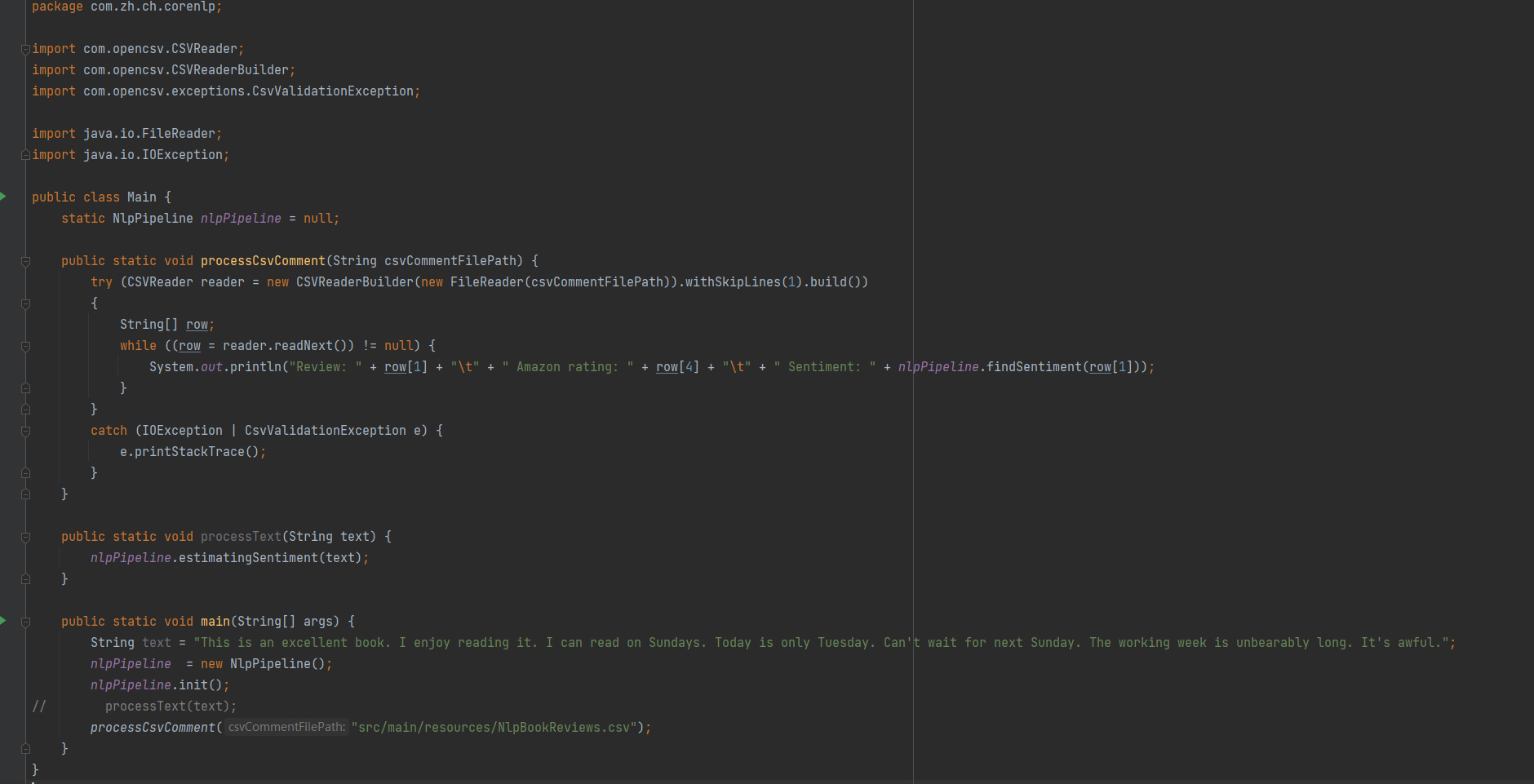
积极的? 消极的? 中性的? 使用斯坦福 CoreNLP 组件以及几行代码便可对句子进行分析。本文介绍如何使用集成到斯坦福 CoreNLP(一个用于自然语言处理的开源库)中的情感工具在 Java 中实现此类任务。斯坦福 CoreNLP 情感分类器要执行情感分析,您需要一个情感分类器,这是一种可以根据从训练数据集中学习的预测来识别情感信息的工具。在斯坦福 CoreNLP 中,情感分类器建立在递归神经
AI能力以API的形式开放出来让我们普通开发者能够很轻易上手使用。当然,市面上有很多成熟的AI API,那么今天就和大家介绍以下几种。OpenAI网址:https://openai.com/api/OpenAI 是一家非营利性人工智能研究公司,其目标是推进数字智能。 最近,当他们宣布 Codex 时,引起了大家的注意,这是一种将自然语言翻译成代码的人工智能。 虽然 Codex 仍处于内部测试阶段,

积极的? 消极的? 中性的? 使用斯坦福 CoreNLP 组件以及几行代码便可对句子进行分析。本文介绍如何使用集成到斯坦福 CoreNLP(一个用于自然语言处理的开源库)中的情感工具在 Java 中实现此类任务。斯坦福 CoreNLP 情感分类器要执行情感分析,您需要一个情感分类器,这是一种可以根据从训练数据集中学习的预测来识别情感信息的工具。在斯坦福 CoreNLP 中,情感分类器建立在递归神经
积极的? 消极的? 中性的? 使用斯坦福 CoreNLP 组件以及几行代码便可对句子进行分析。本文介绍如何使用集成到斯坦福 CoreNLP(一个用于自然语言处理的开源库)中的情感工具在 Java 中实现此类任务。斯坦福 CoreNLP 情感分类器要执行情感分析,您需要一个情感分类器,这是一种可以根据从训练数据集中学习的预测来识别情感信息的工具。在斯坦福 CoreNLP 中,情感分类器建立在递归神经
从 0.9.0 开始 hudi 已经支持 hudi 内置的 FileIndex:HoodieFileIndex 来查询 hudi 表,支持分区剪枝和 metatable 查询。这将有助于提高查询性能。它还支持非全局查询路径,这意味着用户可以通过基本路径查询表,而无需在查询路径中指定“*”。有关支持的所有表类型和查询类型的更多信息,请参阅表类型和查询。如果使用location语句指定一个位置,或者使
在 Java 中,多线程是指同时执行两个或多个线程以最大限度地利用 CPU 的过程。 Java 中的线程是一个轻量级进程,只需要较少的资源即可创建和共享进程资源。多线程和多进程用于 Java 中的多任务处理,但我们更喜欢多线程而不是多进程。 这是因为线程使用共享内存区域有助于节省内存,而且线程之间的内容切换比进程快一点。线程的生命周期线程在其生命周期中必须经历五种状态。 此生命周期由 JVM(Ja

前言截止今年(2022年),亚马逊云已经走过了16个年头,并连续十一年被Gartner认可为云计算领导者。在EC2方面从最原始的单一实例到今天支持475+实例类型,而在服务类型方面更是发展并延伸到了各行各业。说起我与亚马逊云科技的渊源,还得从上大学的时候说起,从当年免费体验亚马逊云上的服务资源,到今天在亚马逊云上的持续学习。接下来我将从产品使用、参与创新大会、深入阅读技术资源等方面聊一聊在亚马逊云

paperswithcode是一个整理论文、代码、数据集等资源的网站,如其网址所述,papers with code!该专题通讯跟踪最新机器学习代码、论文、数据集,机器学习方法以及机器学习库,半个月左右更新一期,具有相当高的质量。本期主题科学机器学习的几项进展,零样本图像分类的最新结果,我们与 ACL 的合作使访问代码和数据集变得更加容易,几个新的研究数据集和工具,... 以及更多科学机器学习在本
AI能力以API的形式开放出来让我们普通开发者能够很轻易上手使用。当然,市面上有很多成熟的AI API,那么今天就和大家介绍以下几种。OpenAI网址:https://openai.com/api/OpenAI 是一家非营利性人工智能研究公司,其目标是推进数字智能。 最近,当他们宣布 Codex 时,引起了大家的注意,这是一种将自然语言翻译成代码的人工智能。 虽然 Codex 仍处于内部测试阶段,

linuxUbuntu and Debian (64 Bit)sudo apt-get install -y adduser libfontconfig1wget https://dl.grafana.com/enterprise/release/grafana-enterprise_8.1.5_amd64.debsudo dpkg -i grafana-enterprise_8.1.5_amd6