




- @u011457868
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
很多专家的观点都认为边缘计算就是先在边缘侧进行大量的数据预处理后,再将二次处理过的数据传给大数据平台端,做机器学习之类,这样既能解决带宽问题,又能减少后端的压力。我觉得这个观点不切实际!

时序数据库经常应用于机房运维监控、物联网IoT设备采集存储、互联网广告点击分析等基于时间线且多源数据连续涌入数据平台的应用场景,InfluxDB专为时序数据存储而生,尤其是在工业领域的智能制造,未来应用潜力巨大。数据模型1.时序数据的特征时序数据应用场景就是在时间线上每个时间点都会从多个数据源涌入数据,按照连续时间的多种纬度产生大量数据,并按秒甚至毫秒计算的实时性写入存储。传统的RDBMS数据库对

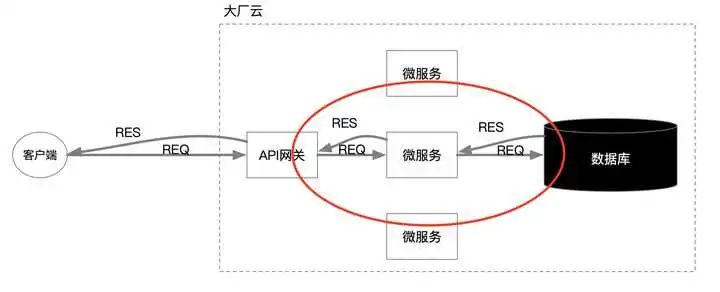
这个事情发生在两年前,是某丰的工程师,根据网上披露的信息,大体情况是这样:首先工程师接到了需求变更的任务工单,需要进行数据库SQL执行操作,并事先准备好了SQL的脚本。接下来通过登陆跳板机就进入到了生产数据库的管理端,然后运行Navicat-MySQL的客户端管理工具。这时候问题出现了,他发现自己选择错了数据库,但是SQL脚本已经粘贴上准备执行了,所以他的目的是按delete键删除选定的执行SQL
很多专家的观点都认为边缘计算就是先在边缘侧进行大量的数据预处理后,再将二次处理过的数据传给大数据平台端,做机器学习之类,这样既能解决带宽问题,又能减少后端的压力。我觉得这个观点不切实际!
大数据平台中Hadoop的分布式文件系统(HDFS)之上形成了一种极具特色的技术群体,那就是SQL查询引擎。这就包括了Hive、Impala、Presto、Spark SQL等;在分布式数据库HBase也具有Impala、phoenix这样的SQL外观,可以通过SQL与HBase交互;另外分布式关系模型数据库(NewSQL),例如:cockroachdb的sql layer、TiDB的tidb模块

分布式对象存储和分布式文件系统具有很强烈的对比性分布式对象存储是key/value的存储模式,以restful访问方式为主,几乎处于扁平化的存储形式,通过地址作为主键,访问、更新的文件对象作为值。文件本身可以分布式分片,但是key/value的访问都是原子性,文件不能追加数据,亦不能随机访问文件的片段,必须整存整取。几乎大多数的互联网web资源访问都适合这种模式,例如:大厂们都云存储OSS。分布式
对于经常接触云计算服务技术的同学们估计一听到ECS,耳朵都能磨出茧子,印象中ECS不就是弹性计算服务么,再人话点就是你按量充值的一台虚拟主机,然后通过SSH远程维护这台虚拟主机的操作系统呗,但是Amazon ECS就不同于你们理解的那个ECS啦!且听我慢慢道来。Amazon ECS全称是(Amazon Elastic Container Service),它是针对容器技术高度弹性的的管理服务,我么
