




- @qq_36936730
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
吐血整理八张思维导图,涵盖数据分析师学习路线及Python等结构化学习框架,让你以最短时间get数据分析秘籍!
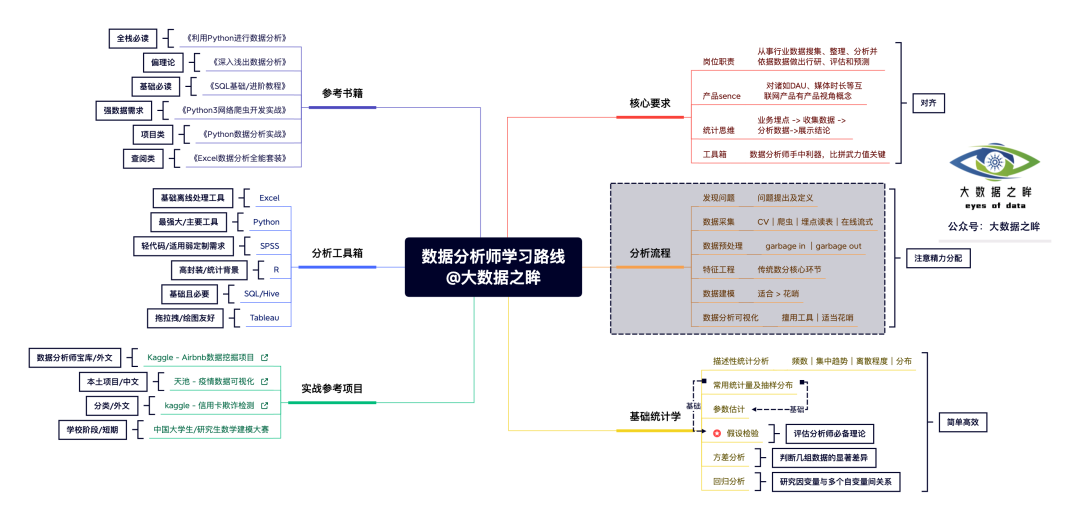
数据分析主要侧重产品sence与Hive使用,也会有少量数据结构、大数据架构与算法相关内容。以下试题为日常整理的通用高频面经,包含题目,答案与参考文章,欢迎纠正与补充。
MongoDB 是目前最流行的 NoSQL 数据库之一,使用的数据类型 BSON(类似 JSON)。本文详细介绍mongodb数据库的下载安装及配置,以及链接python的pymongo数据库和最优秀的mongodb compass可视化工具安装及使用。目录一、mongodb安装二、mongodb配置三、python链接mongodb四、mongodb可视化工具一...
注:数据结构与算法为面试基础,基本上所有岗位都有涉及,面试中侧重核心思路阐述和手撕代码。以下试题为作者日常整理的通用高频面经,包含题目,答案与参考文章,欢迎纠正与补充。____目录1.什么是链表、队列、堆栈、树图?2.删除链表中重复的节点(剑指offer 83)3.两数相加(Leetcode 2)4.反转链表、环形链表、合并链表5.创建包含mi...
注:深度学习同机器学习相似,注重原理理解、算法对比及多场景实战,同时知识迭代更加迅速,相对于机器学习更加前沿。以下试题为作者日常整理的通用高频面经,包含题目,答案与参考文章,欢迎纠正与补充。____目录1.反向传播主要思想及推导2.简要概述HMM、CRF、EM、GMM3.衡量分类器好坏指标4.正负样本不平衡的解决办法5.常用激活函数6.Te...
注:深度学习同机器学习相似,注重原理理解、算法对比及多场景实战,同时知识迭代更加迅速,相对于机器学习更加前沿。以下试题为作者日常整理的通用高频面经,包含题目,答案与参考文章,欢迎纠正与补充。____目录1.反向传播主要思想及推导2.简要概述HMM、CRF、EM、GMM3.衡量分类器好坏指标4.正负样本不平衡的解决办法5.常用激活函数6.Te...
通过前文爬虫理论结合实战的部分我们对爬虫有了初步的了解,首先通过requests模拟浏览器进行请求,接着通过正则表达式或者解析库对网页进行解析,还知道了动态网页Ajax的爬取方法,但总是担心模拟不够会被反爬侦测出来,而本文要介绍的方法则是直接调用浏览器的方式进行高仿浏览器爬虫,这样就再也不用担心啦~目录一、Selenium库介绍1.Selenium简介...
目录一、线性结构1.顺序存储:数组2.链式存储:链表3.线性结构对比4.串5.队列6.栈二、树形结构1.二叉树2.二叉树的特点3.特殊二叉树4.二叉树的性质5.二叉树的存储结构6.二叉树的遍历三、图形结构1.图2.图的存储结构3.图的遍历4.图的基本问题四、集合结构1.HashMap2.HashSet五、算...
今天开始更新爬虫系列笔记,此系列旨在总结回顾常用爬虫技巧以及给大家在日常使用中提供较为完整的技术参考。在进行正式的爬虫之前有必要熟悉以下爬虫的基本概念,例如爬虫的基本原理、网络通信原理以及Web三件套的相关知识等。目录一、爬虫原理1.获取网页2.提取信息3.保存数据4.自动化程序二、HTTPS1.URL...
Spark是一个极为优秀的大数据框架,在大数据批处理上基本无人能敌,流处理上也有一席之地,机器学习则是当前正火热AI人工智能的驱动引擎,在大数据场景下如何发挥AI技术成为优秀的大数据挖掘工程师必备技能。本文结合机器学习思想与Spark框架代码结构来实现分布式机器学习过程,希望与大家一起学习进步~目录1.数学公式2.线性回归3.逻辑回归4.线性支持向量机...