登录社区云,与社区用户共同成长
邀请您加入社区
大型语言模型(LLM)的本地化部署是当前AI工程实践中的关键环节,其核心在于平衡模型性能、推理速度与资源消耗。模型量化技术通过降低权重精度(如FP16、INT4),能显著减少显存占用并提升计算效率,是加速推理的基石。而高性能推理引擎(如vLLM)则通过连续批处理和PagedAttention等优化原理,动态合并请求并高效管理注意力缓存,从而大幅提升吞吐量,这对于构建低延迟、高并发的AI服务具有重要
本文详细解析了如何使用vLLM 0.4.2在单卡RTX 4090上高效部署Qwen2.5-7B大模型,通过关键参数调优实现吞吐量提升3倍的性能优化。重点介绍了内存管理、批处理参数及量化配置等核心技巧,为开发者提供实用的部署指南和性能对比数据。
大模型本地部署已从概念验证走向生产落地,其核心在于平衡性能、成本与可运维性。理解vLLM的PagedAttention显存优化原理、Ollama的快速验证定位,以及Docker容器化带来的环境一致性与交付标准化,是构建稳定AI服务链路的技术基础。这类部署方案显著降低推理延迟(如首token压至42ms)、节省云API调用成本(月省80万+),并支撑工业预测性维护、金融实时风控、政务智能问答等对低延
大语言模型部署是理解AI运行本质的起点,而非简单调用API的技术前置步骤。其核心原理在于将模型推理流程(token化、KV缓存管理、GPU显存调度)工程化落地,关键技术价值体现在推理效率提升、环境可复现性保障与业务微调能力打通。典型应用场景包括本地知识库RAG增强、轻量级移动端AI助手、企业级合同审核系统等。vLLM通过PagedAttention显著优化显存利用率,Docker解决跨平台环境一致
私有大模型推理服务是企业AI落地的关键基础设施,其核心在于平衡性能、成本与工程可控性。vLLM凭借PagedAttention内存管理、Continuous Batching动态批处理和原生OpenAI API兼容性,显著提升GPU利用率与并发能力;Ollama则作为高效模型分发协议,解决非AI工程师的模型获取与验证难题;Docker通过环境契约保障CUDA、PyTorch、vLLM等组件版本可重
大模型部署不是选择‘最酷方案’,而是匹配硬件条件、并发需求、安全策略与运维能力的工程决策。vLLM凭借PagedAttention实现高吞吐推理,Ollama以轻量封装降低桌面端验证门槛;FastAPI作为企业级胶水层桥接OpenAI兼容协议,Gradio提供零代码交互界面,Docker Compose保障跨环境一致性,Open WebUI则打通业务人员使用最后一公里。这些技术共同构成从原型验证到
本文详细介绍了如何通过vLLM推理框架优化Qwen2-7B-NER模型的部署,实现每秒1000次查询(QPS)的高性能推理。文章涵盖了环境准备、核心参数调优、自定义采样器实现、批处理与缓存优化以及性能监控等5项关键技术,帮助开发者在自然语言处理(NLP)任务中显著提升实体抽取(NER)的效率。
大语言模型推理框架 vLLM 是当前主流的高性能服务化方案,其核心原理基于 PagedAttention 内存管理与连续批处理(continuous batching)技术,显著提升 GPU 利用率与吞吐量。在实际工程落地中,版本兼容性、CUDA 工具链对齐、Tokenizer 行为差异及模型配置参数等细节常导致服务启动失败或长尾延迟。本文聚焦 vLLM 0.19.1 与通义千问 Qwen3.5
大模型推理框架 vLLM 作为当前主流的高性能服务引擎,其核心价值在于通过 PagedAttention 和 CUDA kernel 优化实现低延迟、高吞吐的 LLM 推理。理解其与不同模型架构(如 Qwen 系列)的兼容原理,是构建稳定生产环境的基础。Qwen3.5 引入动态 RoPE 编码(rope_theta 可变、支持 dynamic scaling),对底层 attention 实现提出
大语言模型推理框架vLLM凭借PagedAttention机制,显著提升高并发、短请求场景下的吞吐与延迟稳定性,已成为代码生成类模型(如DeepSeek-Coder-V2)的主流部署选择。其核心价值在于显存高效管理与低碎片化调度,尤其适配Fill-in-Middle(FIM)等结构化代码补全范式。然而,由于DeepSeek-Coder-V2采用自定义RoPE缩放参数、MoE专家路由逻辑及专用FIM
代码大模型推理依赖高带宽内存与低延迟互联,而AMD MI300X/MI355X凭借5.2TB/s HBM3带宽和896GB/s Infinity Fabric,天然适配长上下文代码生成任务。其技术原理在于将计算瓶颈从算力转向带宽利用率优化,需绕过CUDA生态惯性,构建以ROCm 7.0为底座、vLLM为执行引擎的专用推理链路。关键价值体现在生产级Day 0支持能力——模型发布当天即实现端到端可用,
AI推理运行时安全是大模型落地的核心瓶颈,尤其在vLLM、CUDA与Ubuntu 24.04深度耦合的生产环境中。本文从AI推理安全的基本原理切入,解析GPU内存隔离、动态链接符号劫持、模型加载完整性等关键风险点,阐明为何传统容器化或权限管控无法应对OpenClaw这类强依赖栈的‘全链路裸奔’问题。技术价值在于通过硬件抽象层(CUDA版本锚定)、运行时沙箱(seccomp+user namespa
OpenAI工具调用(tool calling)是Agent大模型落地的核心协议机制,其本质依赖于严格的状态机流转:assistant消息携带tool_calls后必须紧随tool消息。但在昇腾910B等非CUDA硬件上,vLLM因ACL图优化与状态同步机制差异,导致tool_calls响应无法被正确识别为‘半截请求’,从而触发‘tool_calls must be followed by too
大模型推理引擎vLLM已从实验工具演进为关键基础设施,其核心能力围绕高效KV缓存管理、CUDA运行时深度适配、模型架构原生支持、API协议语义对齐与确定性计算保障展开。vLLM作为当前主流的PagedAttention实现框架,其版本迭代直接影响吞吐、延迟、显存利用率与服务SLA稳定性。尤其在部署DeepSeek-V4等新一代长上下文模型时,旧版dsv4-cu129因缺乏多跳注意力支持、CUDA
vLLM并非传统推理框架,而是基于PagedAttention重构的GPU内存调度系统,其核心价值在于突破显存瓶颈、提升吞吐上限。理解KV Cache分页管理、CUDA Graph编译机制与RoPE位置编码对齐逻辑,是实现高并发低延迟服务的前提。技术本质是将GPU显存作为可调度资源进行细粒度管理,支撑金融文档解析、长上下文生成等生产场景。本文聚焦vLLM+Llama组合在A10G/A100上的真实
大语言模型推理引擎是支撑私有化AI服务的核心基础设施,其性能直接决定低延迟、高吞吐与显存效率。vLLM凭借PagedAttention内存管理与Continuous Batching动态批处理技术,显著提升KV Cache利用率和请求吞吐能力,已成为Llama、Qwen等Decoder-only架构模型的首选推理框架。相比transformers静态批处理易OOM、llama.cpp CPU推理延
大模型推理框架并非同质化工具,而是面向不同技术层级的基础设施:llama.cpp 是轻量确定性引擎,专注CPU/边缘设备上的量化推理与资源可控性;vLLM 是高并发服务化中间件,依托PagedAttention和连续批处理突破显存墙;Ollama 则是开发者友好的模型操作系统,提供声明式部署与跨平台一致性。三者分别解决‘能不能跑’‘能不能撑住’‘好不好用’的核心问题。在金融、政务、教育等私有化落地
大语言模型推理服务在企业级GPU基础设施上的高效部署,核心在于硬件感知调度、显存精细化管理与框架语义集成。vLLM凭借PagedAttention机制显著降低KV缓存显存开销,成为高吞吐低延迟推理的关键引擎;而Nvidia DGX提供的NVLink高速互联与MIG实例化能力,则为多租户、高密度推理提供了底层支撑。当Spark不再仅作HTTP客户端,而是作为有状态请求调度中枢,通过gRPC长连接、动
大模型本地部署中,推理引擎、服务框架与用户环境是三个基础技术层级。Ollama 本质是面向终端用户的模型运行时环境,封装下载、量化适配与API服务;llama.cpp 是轻量级C/C++推理库,专注CPU/GPU极致效率与边缘设备兼容性;vLLM 则是高并发场景下的生产级推理服务器,核心依赖PagedAttention实现显存虚拟化与吞吐优化。三者分别解决‘开箱即用’‘资源受限确定性’和‘规模化服
本文详解如何通过 Cherry Studio 可视化连接私有 vLLM 服务,告别繁琐命令行。涵盖网络配置、API 对接及参数微调,助开发者安全高效地构建专属 AI 编程助手,轻松实现大模型本地化部署与应用。
本文详解 vLLM 在 AMD 显卡上的部署避坑指南,重点解决非法指令错误与显存碎片化问题。通过精准配置 PYTORCH_ROCM_ARCH 参数及优化 block-size,确保 MI300X 等硬件在大模型推理中的高效稳定运行,助力开发者规避生产环境风险。
本文详解 ROCm 7.x 环境下大模型推理延迟过高问题。通过从网络链路到内核算子的全链路排查,利用 rocprof 定位 Host-to-Device 拷贝等瓶颈,并优化 Batch Size 策略,帮助开发者在 Instinct GPU 上实现 vLLM 高性能部署与调优。
本文详解在 DevCloud 上配置 ROCm 7.x 环境以运行 vLLM 的实战指南。通过精选预置镜像、编写设备诊断脚本及验证核心工具链,帮助开发者避开驱动冲突与权限陷阱,快速搭建稳定的 AMD GPU 大模型推理底座,确保业务高效落地。
本文深入解析 ROCm 生态下大模型加载的显存碎片治理方案。针对 AMD GPU 部署 vLLM 时的 OOM 难题,详解 block_size 参数权衡与 gpu-memory-utilization 安全配置策略,帮助开发者优化显存管理,提升推理服务稳定性。
本文记录 ROCm 7.x 环境下从编译报错到服务上线的排错实战。针对链接器罢工、算子不匹配及段错误等难题,提供环境变量配置、架构代码指定与依赖版本锁定方案,助开发者高效部署 PyTorch 与 vLLM,确保大模型推理稳定运行。
本文实测 ROCm 7.x 新特性,揭示其如何通过 hipBLASLt 稀疏计算与异步流优化,显著降低长上下文推理延迟。数据显示,在 AMD Instinct GPU 上配合 vLLM,首字延迟降低约 20%,大幅提升大模型推理效率与稳定性。
本文基于 ROCm 7.x 环境,深度测试 vLLM 在 AMD Instinct GPU 上的大模型推理性能。通过 benchmark_serving.py 分析并发负载与 FP8 量化效果,揭示显存带宽瓶颈及调优策略。实测证明,合理配置下 AMD 平台可实现显著提速,为开发者提供非 NVIDIA 方案的高效部署参考。
本文深入解析 ROCm 7.x 环境下 vLLM 的显存碎片化难题。通过优化 PagedAttention 的 block-size 参数、结合 FP8 量化与重计算策略,有效解决 AMD GPU 上的 OOM 问题。文章还提供显存泄漏排查指南,助力开发者提升大模型推理效率与稳定性。
本文实测 ROCm 7.x 环境下 FP8 量化加速效果。数据显示,相比 FP16,FP8 显存占用降低 44%,解码吞吐量提升 36%,且精度损失可控。文章详解 vLLM 部署要点与算子支持验证,为 AMD GPU 大模型推理提供高效优化方案。
本文详解 AMD Instinct GPU 上 vLLM 的网络延迟诊断与优化策略。从链路瓶颈排查到利用 rocprof 定位异常算子,再到减少数据拷贝开销及日志优化,全方位提升推理性能。掌握这些技巧,有效解决高延迟问题,释放 GPU 算力潜能。
本文详解 ROCm 7.x 环境下 vLLM 的 PagedAttention 调优策略。针对 AMD GPU 显存不足痛点,深入剖析 gpu-memory-utilization 安全阈值、block-size 场景化选择及量化技术落地要点,助开发者有效避免 OOM,大幅提升大模型推理效率。
本文详解 ROCm 环境下 vLLM 编译报错与运行故障排查。针对 HIP 库缺失、架构代码不匹配及依赖冲突等常见问题,提供环境变量配置、GPU 架构指定及驱动修复方案,助开发者快速解决 vLLM 部署难题,确保大模型推理稳定运行。
本文详解如何利用 Radeon GPU 搭配 vLLM 搭建低成本高并发大模型推理服务。通过优化 ROCm 环境与参数调优,解决兼容性问题,实现 PagedAttention 高效运行。实测数据显示,该方案在内部场景中吞吐量显著提升,为预算有限团队提供高性价比的 AI 部署新选择。
本文详解 AMD 显卡部署大模型实战,聚焦 ROCm 7.x 与 vLLM 的避坑指南。涵盖 Ubuntu 环境配置、PyTorch 源码编译及显存碎片化调优,通过调整 block-size 与 FP8 量化解决 OOM 难题,助开发者高效构建稳定推理服务。
本文详解 AMD ROCm 环境下 vLLM 部署中 Triton 编译器版本匹配的关键技巧。针对段错误难题,提供 PyTorch 与 Triton 的兼容性矩阵查询方法及精准安装步骤,帮助开发者规避依赖冲突,确保大模型推理稳定运行。
本文详解 ROCm 环境下大模型多卡并行配置策略。针对 Llama 3.1 等超大参数模型,深入剖析张量并行原理、GPU 拓扑检测及 NUMA 绑核优化技巧。通过 vLLM 实战与通信瓶颈排查,助开发者高效部署高性能推理服务,解决显存溢出难题。
OpenAI Workspace Agents 是 2026-04-22 发布的 ChatGPT 团队级共享 Agent 产品,2026-05-06 信用计费生效,面向 Business / Enterprise / Edu / Teachers 用户,是 GPTs 的"演进形态",由 Codex 驱动,可跨工具(Slack、Google Drive、Linear、Calendar、Gmail、N
摘要 DeepSeek-OCR是DeepSeek AI推出的创新多模态模型,采用"上下文光学压缩"技术实现高效文本处理,在10倍压缩比下精度达97%。该系统支持五种分辨率模式,日处理20万页数据,可识别文档、表格、公式等复杂内容。安装需24GB以上显存GPU和Python 3.12.9环境,提供本地部署和云端服务两种方案。应用场景包括企业文档数字化、学术研究、金融法律等领域,通
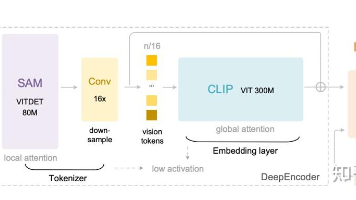
研究动机:LLM 处理超长上下文时计算与显存成本会随序列长度急剧上升。DeepSeek-OCR 提出把长文本转为高分辨率图像,再用视觉 token替代海量文本 token,从而显著降低成本。总体架构:一个DeepEncoder(视觉编码器)+ 一个3B MoE 解码器。DeepEncoder 以窗口注意力 + 16×卷积压缩 + 全局注意力串联,既能吃高分辨率,又能把视觉 token 压到很少;解
vLLM
——vLLM
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区














 AMD开发者中国社区
AMD开发者中国社区


 AtomGit AI 社区
AtomGit AI 社区