




- @yuand7
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
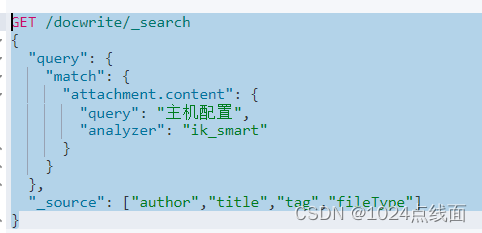
你可以指定一个包含字段名的数组来只包含这些字段,或者指定一个排除字段名的数组来排除这些字段。在Elasticsearch(ES)中,当你执行查询时,通常希望只返回特定的字段,而不是整个文档的所有字段。最近在使用ES检索pdf、word等文件内容时查询发现返回的结果过于冗长,不好阅读,因为文件的内容占据的篇幅太大了,因而要设置返回字段。请注意,根据你的具体需求和使用的Elasticsearch版本或
2022年已经没有人谈大数据这个概念,不是它失败了,恰恰是因为它成功了。成功技术的吊诡之处在于,它最终会被认为是理所当然,消失在背景音中。随着SaaS的普及和深入,数据驱动成为共识,云计算以及云端数据仓库的发展,逐渐有了现代数据技术栈这个新的数据生态体系。现代数据栈(MDS)主要是在欧美,确切的来讲是美国近几年出现的一个称呼,我们可以把它理解为一套新的数据生态体系。现代数据技术栈通常是指构成云原生
JVM G1GC(Garbage-First Garbage Collector)是Java虚拟机中的一种垃圾收集器,它以高吞吐量和可预测的停顿时间为目标,特别适合需要大内存和多核处理器的服务器应用。初始堆大小(-Xms)和最大堆大小(-Xmx)根据应用的内存需求设定这两个值,以确保应用在启动和运行过程中有足够的内存资源。通常建议将-Xms和-Xmx设置为相同的值,以减少运行时堆内存的动态调整,从

随着数字化时代的来临,大数据已经成为了许多领域不可或缺的重要资源。而大数据工程师掌握着处理、分析和应用大数据的核心技能。那么,大数据工程师的日常工作内容到底是什么呢?一种是数据需求的开发与治理,另一种则是平台与基础系统研发建设。业务侧的日常工作内容广泛而多样(但由于平台的建设,很多业务就是写SQL数据采集与集成设计并实施数据采集方案,包括从各种源头(如传感器网络、日志文件、交易记录等)收集数据,可
