




- @weixin_66378701
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在写博客时,我们通常不使用csdn直接撰写,而是在本地使用markdown编辑器,比如比较好用的Typora,但是在本地写完直接上传到csdn时会存在图片由于防盗链不显示的问题,本文记录如何解决该问题。
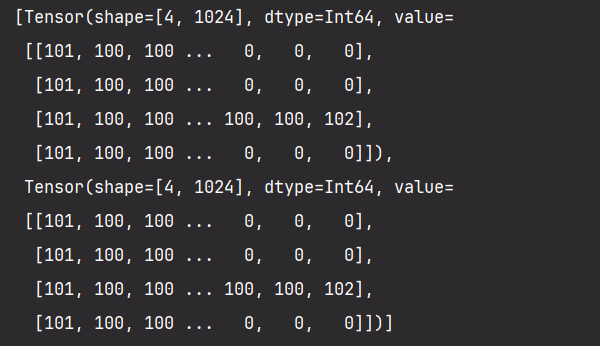
今天做一个根据一段文章提取摘要的提取器,基于nlpcc2017摘要数据,内容为新闻正文及其摘要,就是训练集及标签。首先我们来预装以下MindSpore环境安装tokenizers和mindnlp。
今天基于GPT实现一个情感分类的功能,假设已经安装好了MindSpore环境。
在一个torch做的项目中直接在最开始,在import torch之前,代码执行的主入口文件中,添加一行(需设置ENABLE_BACKWARD,看后面微分接口适配块)就行了,就能跑了,没错。人傻了。其他的代码都不用改。

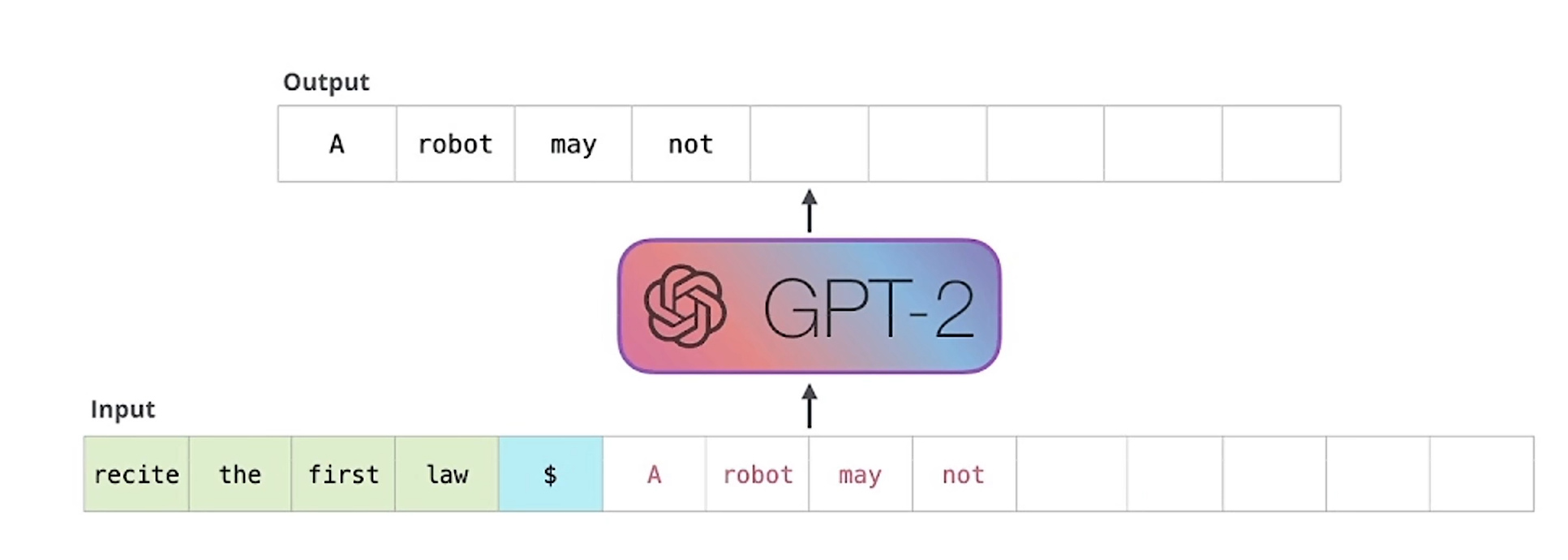
大语言模型就是输入前一个词预测下一个词。
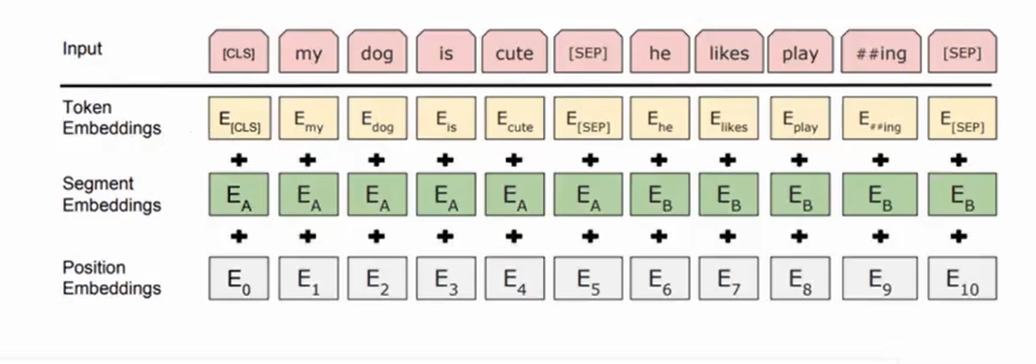
bert和transformer都有Embedding操作,包括词嵌入(word embedding)和位置嵌入(positional embedding)但是transformer中的位置信息是三角函数bert中的位置信息是可学习的,并增加了用于区分不同句子的段嵌入(Segment Embeddings)。三个embedding作相加得到最后的embeddingbert就是多层的transfor
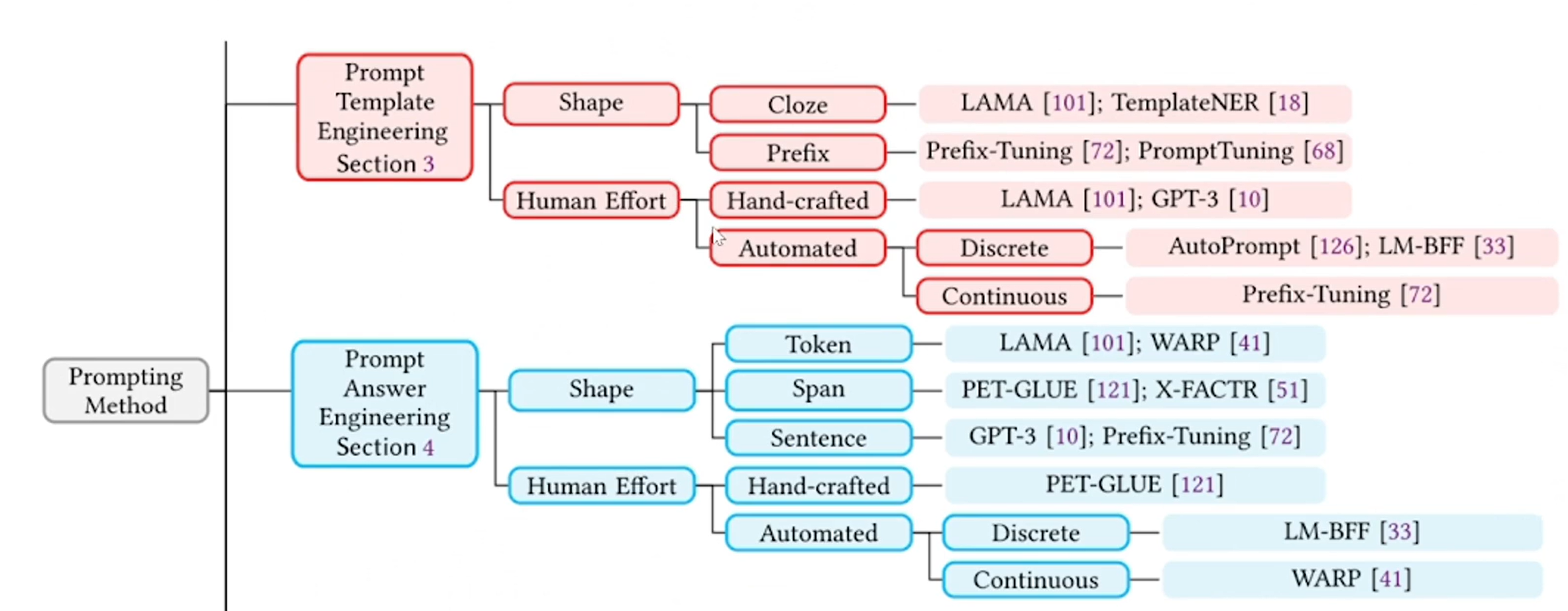
标签词映射:在模型给出答案之后,比如模型给了个greet,因为我们是个情感分类任务,想要得到的结果只是两种,我们就要建立greet到positive的映射。传统的NLP训练模式都是先在大量的无标注的样本上进行预训练,然后再使用有标注的样本进行有监督的训练,调整单一的线性成果而不是整个模型。这一步给模型模型就需要去填这个mask 的答案,模型会填进去很多可能的答案,每个答案对应一个分数,分数最高的是
函数式自动微分是Mindspore学习框架所特有的,更偏向于数学计算的习惯。这里也是和pytorch差距最大的部分,具体体现在训练部分的代码,MindSpore是把各个梯度计算、损失函数计算在这幅图中,右边这个就是函数式编程,首先先自己定义一个loss函数,最后一行使用grad(),把loss function传进去,因为传进去的是一个函数,做的是一个函数闭包,所以返回的还是一个函数。

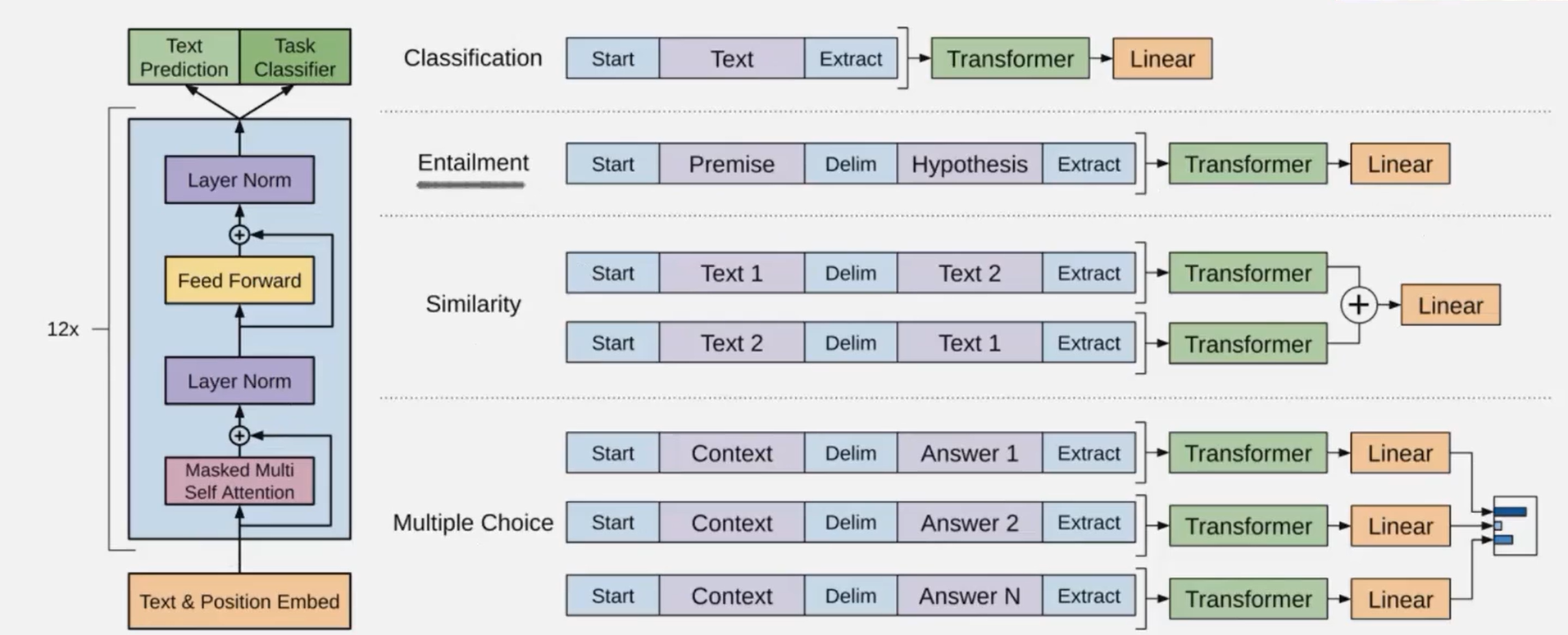
在实际中,往往未标注的文本数据远多于已标注的,这些未标注的文本数据无法投入训练,又浪费提出了一种方法,基于大量未标注的文本数据,训练预训练语言模型,学习到一些general的特征。然后使用已标注的文本数据,对模型针对某一特定下游任务进行finetune,微调,仅更改output layer,就是GPT1存在问题:多元的下游任务难以有统一的优化目标。同时较难将预训练模型学到的信息传递到下游任务中。这
比如此时给一个手放在键盘上的照片,你要猜他此时是在苦逼敲代码还是快乐打游戏。但如果之前给了一张照片,上面是屏幕上的内容,那么我们就可以结合上一张照片来更好的判断此时手在键盘上是干什么。CRF全称Conditional Random Field,按照名字来理解,条件随机,随机输入,条件输出。在正式开始LSTM+CRF序列标注之前,我们先来了解一下条件随机场,以下仅做简单介绍。线性CRF是最常用的,也
