




- @weixin_46838716
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1)python的基础知识,虽然平时都在编代码,但是我们用的都是现成的深度学习模块啥的,里面的其他python知识不是非常了解2)没事就来看看,互联网大厂的笔试题和面试题都会考,尤其像京东的笔试选择题,一定会考的。
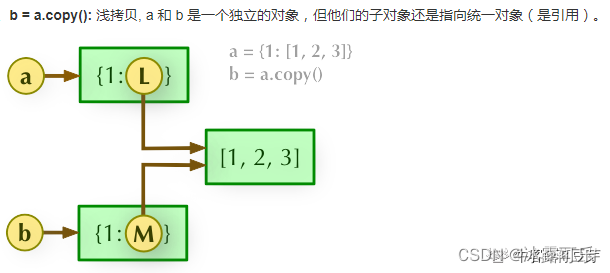
1)很多都是图像处理领域的传统算法,应用于目标检测,目标跟踪,数字信号处理等2)这些基础八股文,简单地了解一下,有个印象,不少东西是课堂上学过的,回忆一下就行。
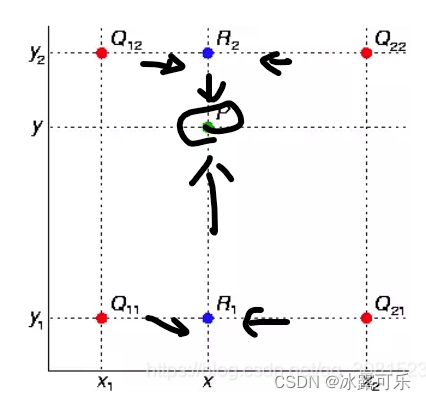
1)生成式对抗网络GAN的结构,目的,均衡效果,训练过程,优缺点,这些都做简要的了解。2)G的目标是生成尽可能真实的图片,欺骗D,D的目标是鉴别图片的真伪,尽量让自己更有判别性,交替训练,最终达到纳什均衡3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
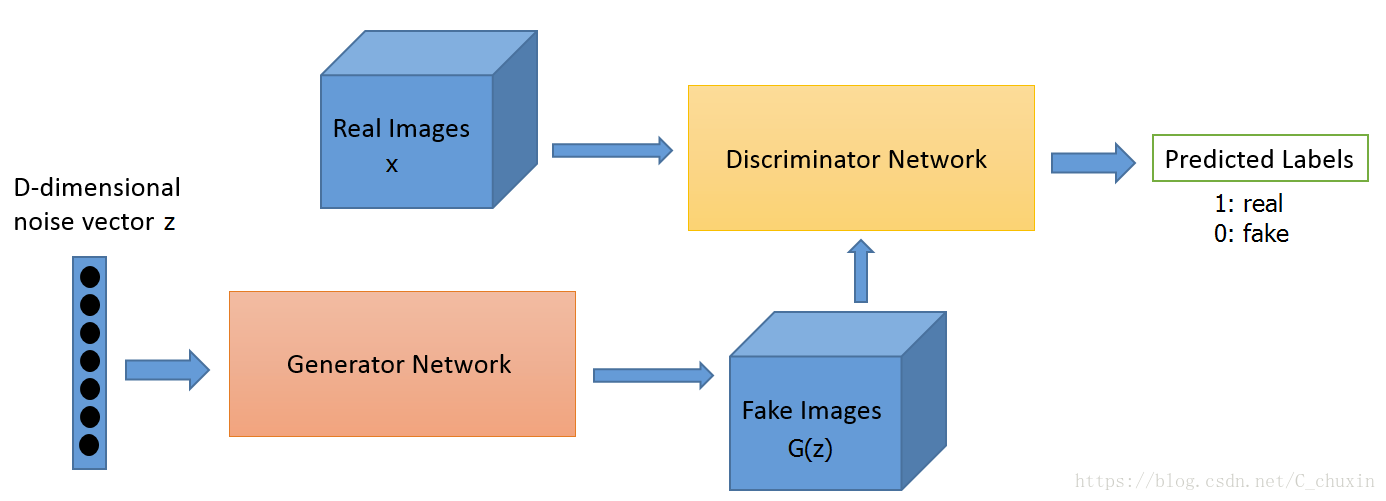
Oracle数据库:逻辑运算and,or,not和各种运算的优先级控制
数据挖掘与分析应用1:Excel表数据分析,sum,sumif,sumifs,vlookup,match,index,几个配合使用
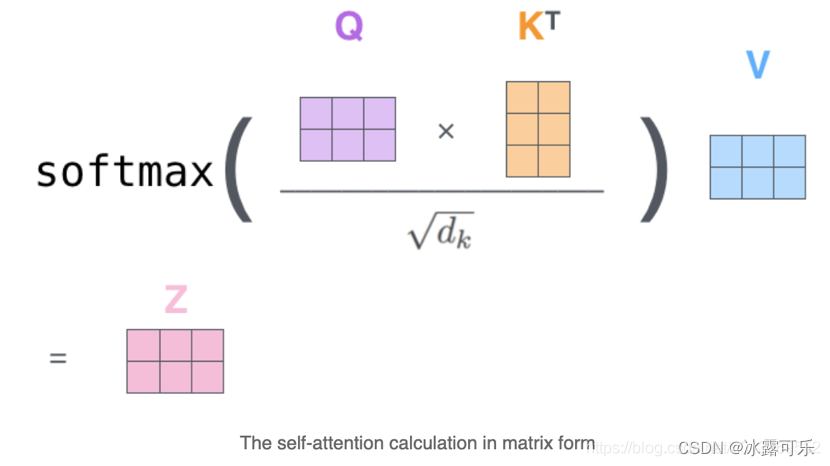
1)transformer是BERT的基本结构,self-attention又是transformer的重要核心,transformer比CNN,RNN,LSTM牛逼多了,BERT是预训练大模型。2)Tranformer已经在CV中开挂了,所以不只是NLP里面有这个玩意3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
史上最全的机器学习深度学习面经总结
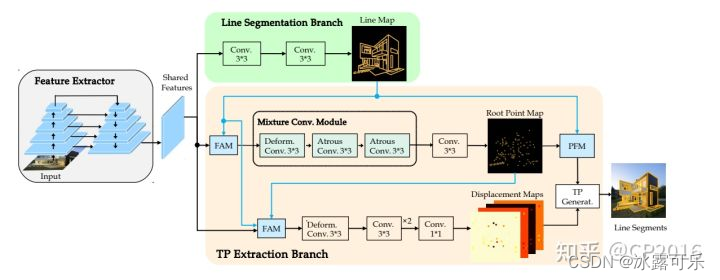
1)从霍夫变换算法到经典的LSD传统算法,后来改进很多,但是效果都和LSD差不多,而LSD又比霍夫变换牛2)2018年开源了一个直线检测的数据集wireframe,从此很多关于端点预测的2阶段,和2阶段网络设计出来,预测端点,或预测中点,方向和距离啥的。3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。...
1)深度学习和机器学习在互联网大厂中的笔试,或者面试都会遇到的知识点2)没事来看看,总会有用的3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。

数据挖掘与分析应用:聚类算法,kmeans聚类,DBSCAN基于密度空间聚类,关联规则法探索数据
