




- @qq_73472828
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文探讨了生成对抗网络(GAN)在工业界的核心应用,重点分析了超分辨率、人脸合成与数据增强三大领域。文章首先梳理了超分辨率技术的发展历程,从传统插值方法到基于GAN的SRGAN、ESRGAN和Real-ESRGAN,并介绍了感知损失函数如何解决传统MSE损失导致的模糊问题。在人脸合成方面,文章讨论了DeepFake技术原理及其检测方法。此外,还展示了GAN在医疗影像增强和数据稀缺场景中的应用价值。

本文是Python高性能编程系列的收官篇,通过一个图像处理流水线的综合实战案例,展示了从纯Python实现到最终120倍性能提升的完整优化过程。案例处理1000张512×512灰度图像,包含归一化、高斯滤波、边缘检测、直方图均衡化和特征提取五个步骤。作者首先建立纯Python基准实现,然后逐步应用系列前九篇介绍的优化技术:NumPy向量化、内存优化、Numba JIT编译、多进程并行和流水线架构优

这篇文章是《Python 基础全栈系列》的开篇,全面介绍了Python的基础知识和环境搭建。主要内容包括: Python全景介绍:从1989年Guido van Rossum的圣诞项目诞生,到成为全球最流行的编程语言,解析了Python"可读性优先、简洁至上、实用主义"的设计哲学及其在AI、数据科学、Web开发等领域的广泛应用。 环境搭建指南:详细讲解了Python解释器的安装(CPython/P

这篇文章是Python基础全栈系列的第4篇,聚焦函数与作用域这一核心概念。文章分为三个主要部分: 函数定义与参数:详细讲解Python函数的5种参数类型(位置参数、默认参数、可变位置参数、仅关键字参数和可变关键字参数),强调参数顺序规则,并揭示可变默认值的陷阱及解决方案。 作用域规则:通过LEGB(Local-Enclosing-Global-Builtin)模型解析变量查找机制,介绍global

本文介绍了Python中的流程控制结构,包括条件判断(if/elif/else/match/case/三元运算符/海象运算符)和循环(for/while/break/continue/else)。重点讲解了Python特有的缩进语法、模式匹配、可迭代对象遍历方式(enumerate/zip)以及Pythonic的推导式写法。内容涵盖从基础语法到进阶特性,通过猜数字游戏案例展示如何综合运用这些控制结

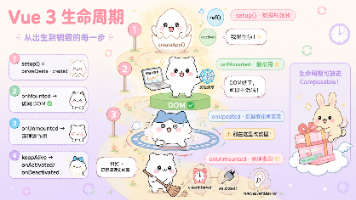
文章摘要 本文是Vue 3系列教程的第四篇,全面解析了Vue 3的生命周期钩子。主要内容包括:Vue 3与Vue 2生命周期对比(如beforeDestroy改为onBeforeUnmount);setup()替代了beforeCreate和created;各阶段钩子的执行时机和使用场景(如onMounted用于DOM操作);特殊钩子如keep-alive相关钩子;在Composable中使用生命
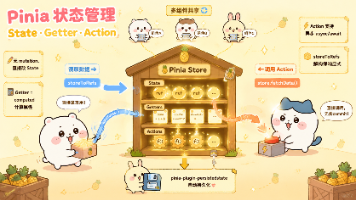
本文是Vue 3系列第六篇,全面介绍Pinia状态管理库。Pinia作为Vuex的轻量级替代方案,具有更好的TypeScript支持、更简洁的API(无mutation概念)和更小的体积(约1KB)。文章对比了Pinia与Vuex的差异,详细讲解了两种Store写法:Options风格(类似Vue 2)和推荐的Setup风格(基于Composition API)。通过电商购物车场景示例,展示了如何
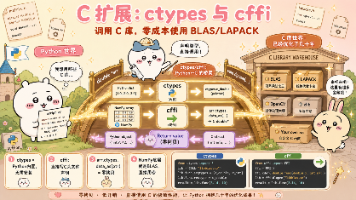
Python高性能编程:使用ctypes和cffi调用C库 本文介绍了Python中直接调用C库的两种主要方法:内置的ctypes模块和更现代的cffi库。主要内容包括: 为什么调用C库:许多高性能数值计算库(如BLAS、LAPACK、FFTW)都是用C/Fortran编写并经过高度优化,直接调用可以避免重复实现。 ctypes基础: 加载系统C库(Linux的libc.so.6、macOS的li
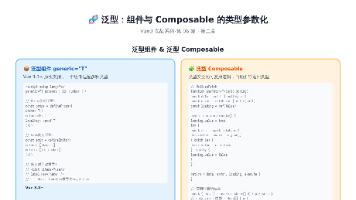
本文是 Vue3 实战系列的收官之作,重点探讨 TypeScript 与 Vue3 的深度整合。文章从类型安全基础入手,对比了 defineProps 的运行时声明与泛型声明,推荐使用泛型声明以获得更完整的类型支持。同时介绍了 defineEmits 的事件类型安全机制和 ref 模板类型的 InstanceType 用法。第二部分深入讲解了 Vue 3.3+ 的泛型组件特性,通过 generic
本文是Vue 3完全指南系列的收官篇,重点介绍工程化实战。主要内容包括:Vite配置详解(开发服务器、构建优化、CSS处理等);TypeScript最佳实践;自动导入工具unplugin-auto-import和unplugin-vue-components的使用;代码规范配置(ESLint+Prettier);多环境配置、路径别名设置;构建产物分析与优化;以及部署方案(Nginx、Docker、
