




- @qq_55906442
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
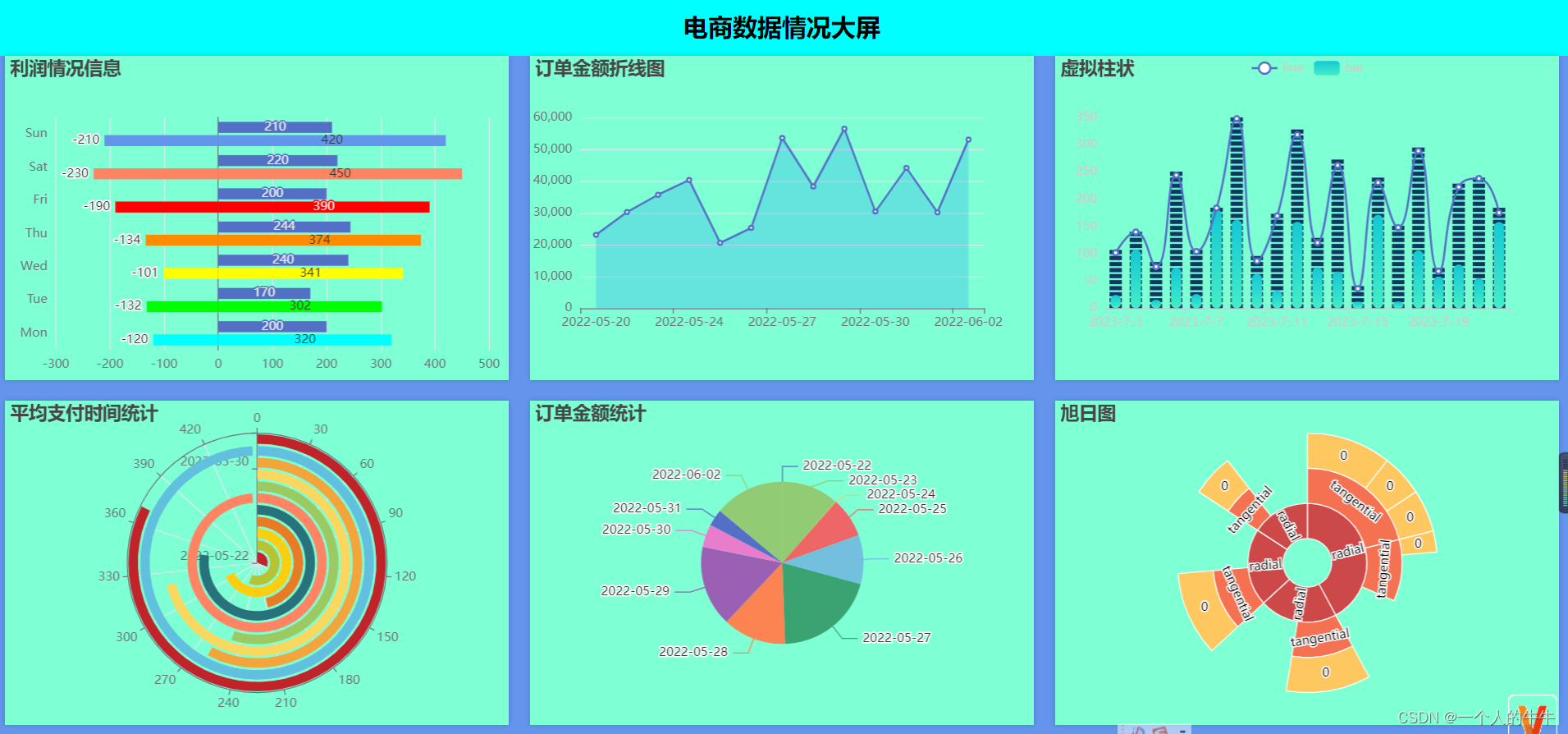
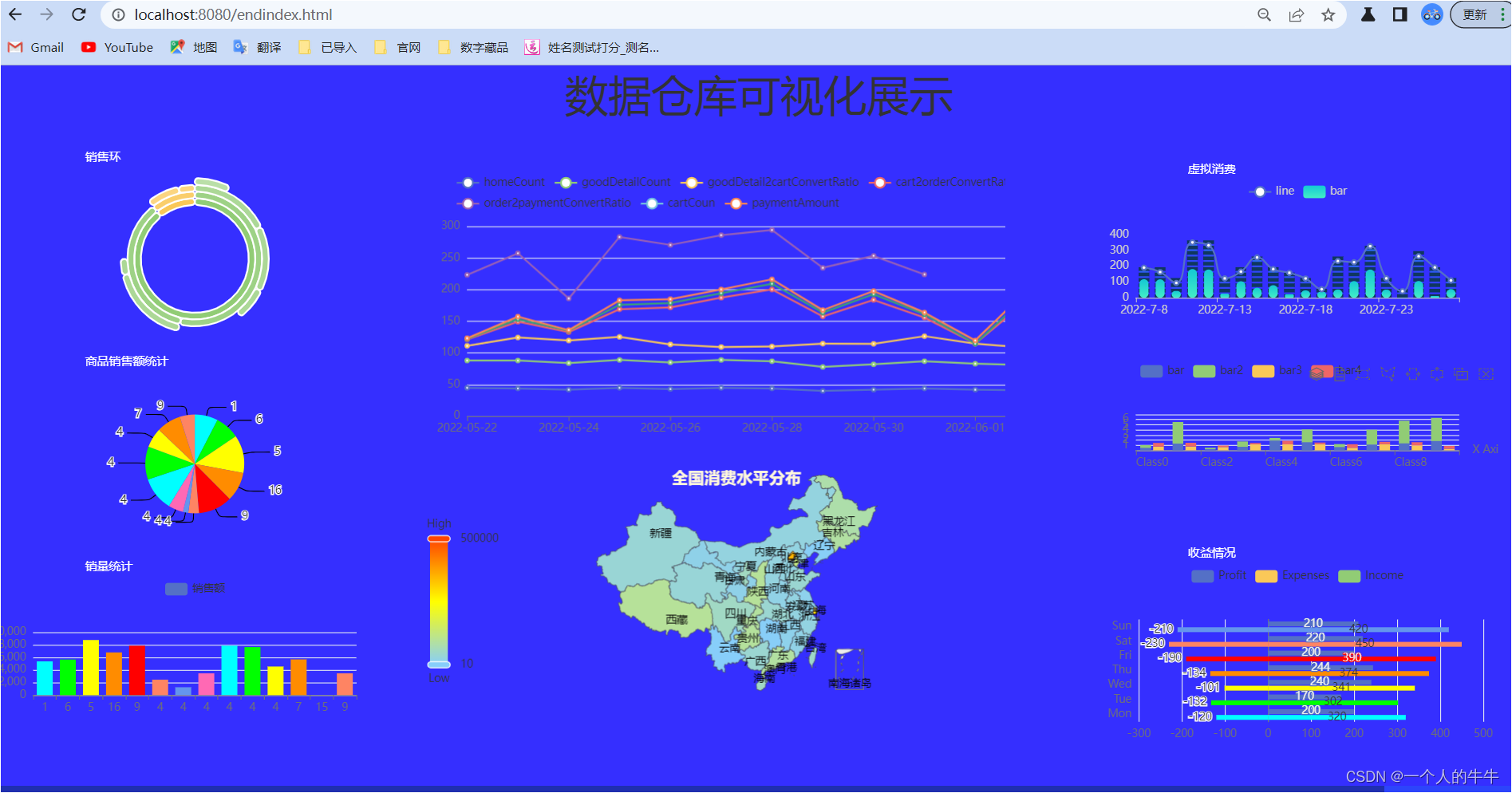
成果展示:1)可以使用自己的MySQL数据库;2)使用我提供的数据。(免费下载)gmall_report用于可视化的SQL文件-MySQL文档类资源-CSDN下载MySQLIDEAjdk1.8Maven创建springboot项目有二种方式:1)在IDEA中创建2)在官网上创建我喜欢在官网创建官网地址(记得收藏):https://start.spring.io/ 注:1)注意红色框框的地方,选择
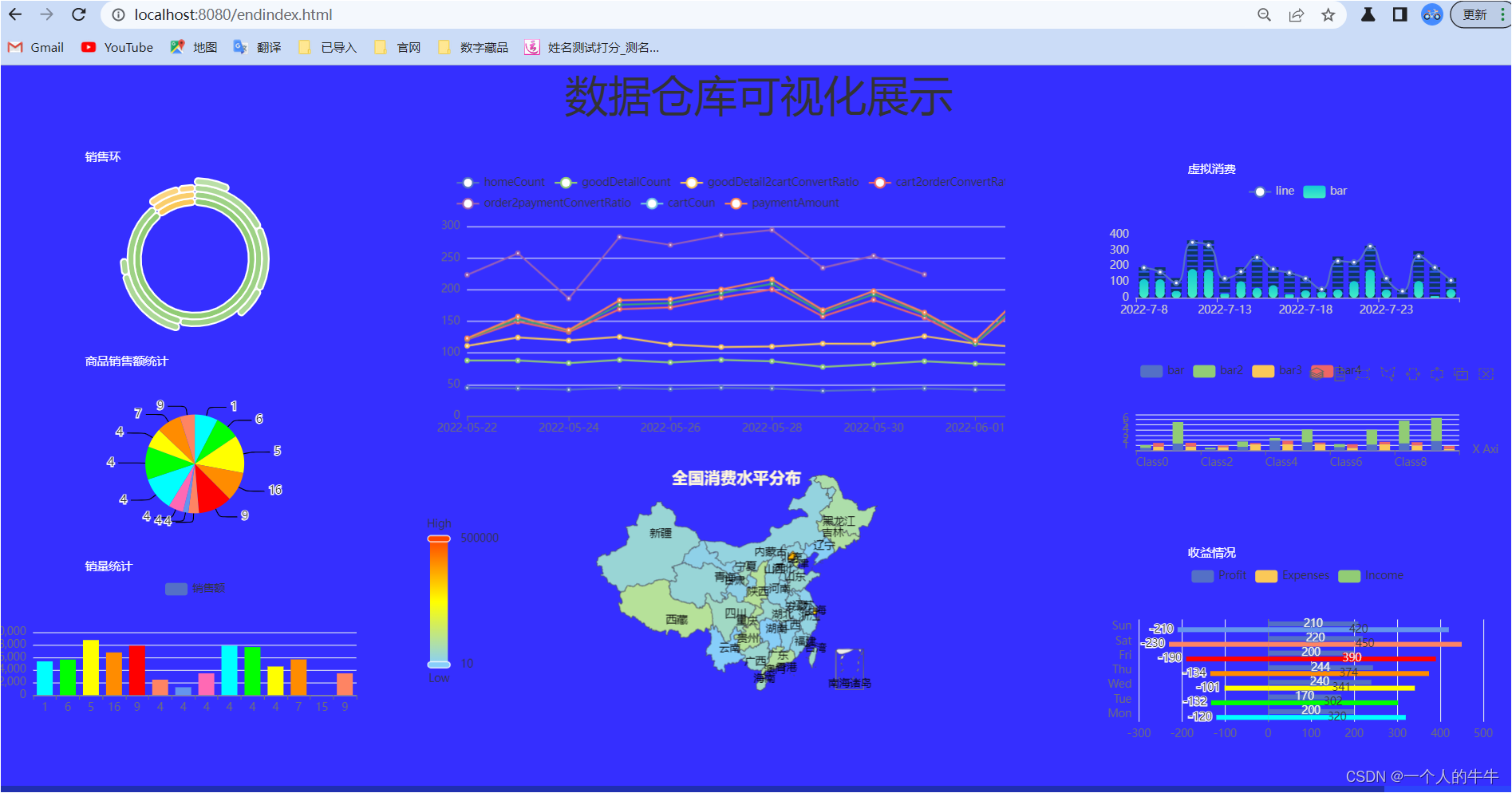
springboot+echarts +mysql制作数据可视化大屏(六图)
一、前期准备1.1安装了jdk1.2安装了zookeeper分布式zookeeper单机和集群(全分布)的安装过程_一个人的牛牛的博客-CSDN博客1.3配置免密码登录Linux配置免密登录单机和全分布_一个人的牛牛的博客-CSDN博客1.4机器准备主节点从节点hadoop01hadoop02hadoop02hadoop03笔记本性能不够,没有安装多的虚拟机,hadoop02重复使用。

成果展示:1)可以使用自己的MySQL数据库;2)使用我提供的数据。(免费下载)gmall_report用于可视化的SQL文件-MySQL文档类资源-CSDN下载MySQLIDEAjdk1.8Maven创建springboot项目有二种方式:1)在IDEA中创建2)在官网上创建我喜欢在官网创建官网地址(记得收藏):https://start.spring.io/ 注:1)注意红色框框的地方,选择
继承Receiver,实现onStart、onStop方法来自定义数据源采集。//TODO 创建配置环境//采集数据//开始}/*自定义数据采集器1.继承Receiver,定义泛型,传递参数2.重写方法*///最初启动,读数据val message = "采集的数据为:" + new Random().nextInt(10).toString}}}//停止}}}结果://初始化Spark配置信息/