




- @qq_52213943
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在大数据时代,信息的获取至关重要,而网络爬虫正是帮助我们从互联网上获取海量数据的重要工具。无论是数据分析、人工智能训练数据,还是商业情报收集,爬虫技术都能发挥重要作用。本篇文章将全面解析 Python 爬虫的各个方面,从基础知识到高级应用,带领读者掌握爬虫开发的核心技能。

2024年,人工智能技术进入全面突破期,从生成式AI到多模态大模型,覆盖语言、视频、音乐等多个方向,推动技术与产业深度融合。AI在教育、医疗、服饰等领域展现了极强的应用潜力,提升效率与创造力。AI的快速迭代不仅驱动技术变革,更在各行业落地实践中释放出改变社会的强大力量。

从传统数据库出发,帮助读者更好理解数仓的核心价值和基本结构
探讨在处理大规模数据集时如何有效地进行数据可视化,如何在大数据分析中有效传达信息,包括交互式探索、实时仪表板和复杂数据故事讲述
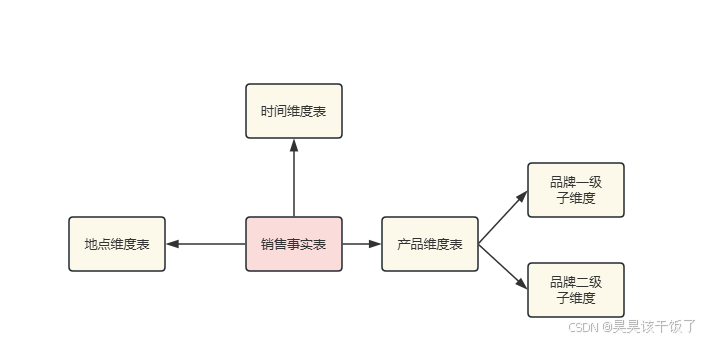
在大数据分析和数据仓库设计中,星型模型和雪花模型是两种常用的建模方法,它们各有优缺点,适合不同的业务场景。从结构特点到实际应用,从查询性能到存储优化,如何选择合适的模型对提升数据处理效率至关重要。本篇文章将以详细的表格、实例和SQL示例,全面解析星型模型与雪花模型的核心概念、结构对比和应用场景,帮助读者掌握数据建模的关键技术。
在深度学习项目的开发过程中,计算资源的选择对模型训练效率和成本控制至关重要。本文将以图像分类项目为例,详细解析如何利用GpuGeek平台的高性价比GPU资源和丰富的镜像市场,完成从数据预处理到模型部署的全流程,帮助读者高效推进深度学习项目。
Transformer是现代深度学习的核心架构之一,广泛应用于自然语言处理、计算机视觉等领域。本文将从Attention原理讲起,逐步拆解Transformer架构,结合BERT、GPT等主流模型,通过实战示例讲透大模型训练的完整流程。
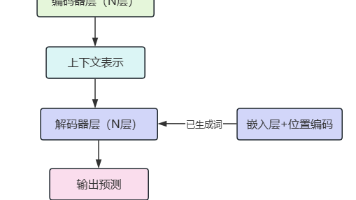
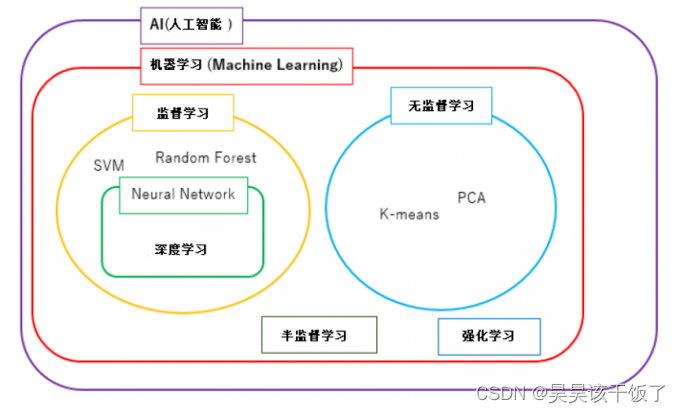
本文探讨机器学习和深度学习之间的关键区别和相互联系,目的是为大家提供一个清晰的框架,帮助大家理解这两种技术的特点、应用场景以及选择适当方法的依据。(理论辨析,无实践代码,放心食用)
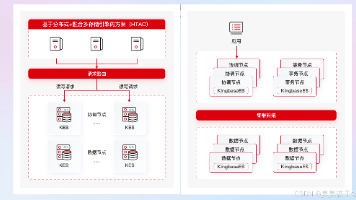
国产数据库早已实现 “可替代”,但要真正与国际头部厂商掰手腕,必须在 HTAP(Hybrid‑Transaction/Analytical Processing)与 AI 加速 两条技术赛道上实现跨越。KingbaseES 自 V8R3 调整为多进程架构后,历经 V8R6、KSOne 等产品层迭代,正在形成覆盖事务、分析、向量检索的一体化数据平台。本文基于官网文档、社区实践案例与作者内部测试数据,
IaaS、PaaS和SaaS构成了云服务的三大模型,分别提供了基础设施、平台和软件的即服务解决方案。IaaS提供最大的灵活性和可扩展性,适合需要深度控制基础设施的用户。PaaS简化了开发过程,加速应用部署,适用于开发者和初创公司。而SaaS为终端用户提供即开即用的应用,强调便捷性和易用性。理解这些模型的关键特性和适用场景,有助于根据具体需求做出明智的云服务选择。
