- @qq_43224174
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
简介:本篇博客是kafka集群安装部署的详细操作步骤,主要包括了修改相关配置文件、配置环境变量、启动集群、编写启动和停止脚本。
[2021-12-28 23:35:02,165] ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)kafka.common.InconsistentClusterIdException: The Cluster ID eq9F2UfWTVqmKCEial0hrw
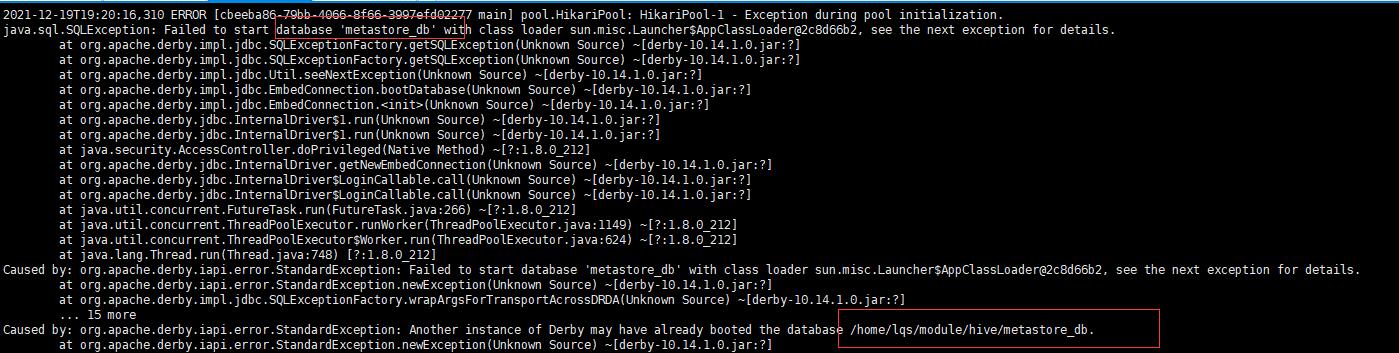
详细报错信息如下:2021-12-19T19:20:16,310 ERROR [cbeeba86-79bb-4066-8f66-3997efd02277 main] pool.HikariPool: HikariPool-1 - Exception during pool initialization.java.sql.SQLException: Failed to start database
本篇博客是对kafka produce 生产者分区器的API(Java)包含以下内容:分区使用原则,分区器使用原则,分区器相关代码编写及pom.xml配置文件编写,到最后的运行结果。使用kafka producer分区器的好处:1、方便在集群中扩展2、可以提高并发性分区原则1、 指明 partition 的情况下,直接将指明的值直接作为 partiton 值;2、没有指明 partition 值但
flume启动一直报错ERROR - org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:158)] Unable to deliver event. Exception follows.,报错详情如下2021-12-27 20:41:52,509 (SinkRunner-PollingRunner-DefaultSinkPr
解决idea 的因为lombok的报错:java: You aren't using a compiler supported by lombok, so lombok will not work and has been disabled.Your processor is: com.sun.proxy.$Proxy27Lombok supports: OpenJDK javac, ECJ
linux下启动Presto报错:Cannot connect to discovery server for announce: Announcement failed for http://hadoop102:8881在虚拟机hadoop103启动时报错[lqs@hadoop103 presto]$ bin/launcher run报错内容如下:hadoop103:349662021-12-0

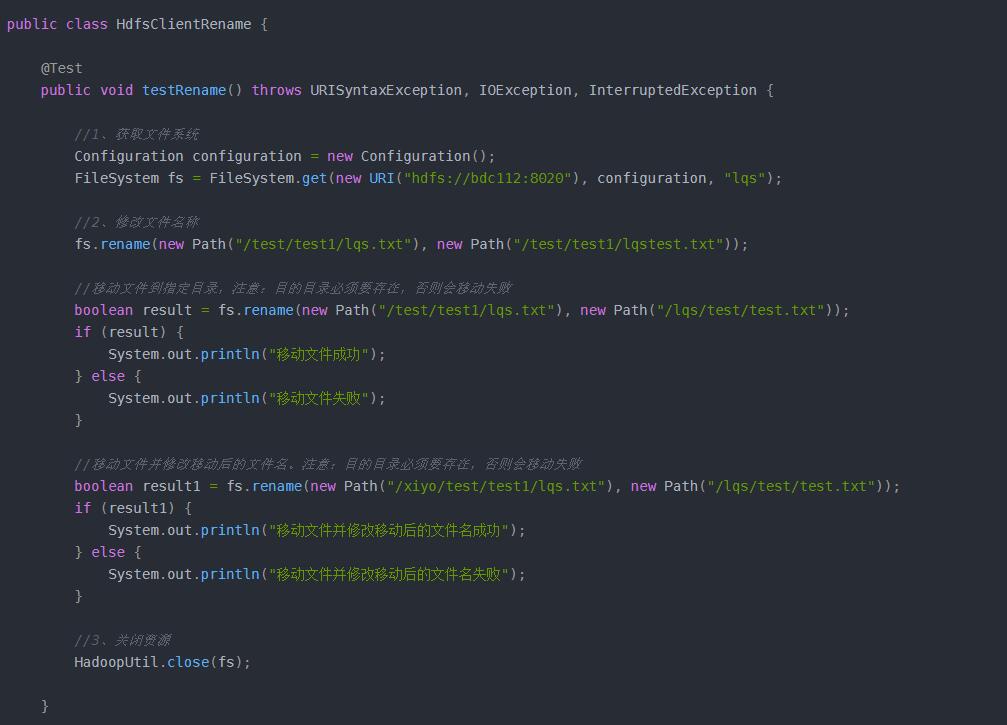
本篇文章主要介绍的是hadoop hdfs的基础api的使用。包括Windows端依赖配置,Maven依赖配置。最后就是进行实际的操作,包括:获取远程hadoop hdfs连接,并对其进行的一系列操作,包括;文件夹创建、文件上传、文件下载、文件(夹)删除、文件更名或移动、文件详细信息的获取并打印到控制台,以及文件类型的判断(文件夹或文件)并打印对应文件(夹)的详细信息。
Traceback (most recent call last):File "/home/admin/apps/*-*-sync/task/__init__.py", line 114, in runfor data in self.index_data():File "/home/admin/apps/*-*-sync/task/huahuo/*_*_sync.py", line 72, in
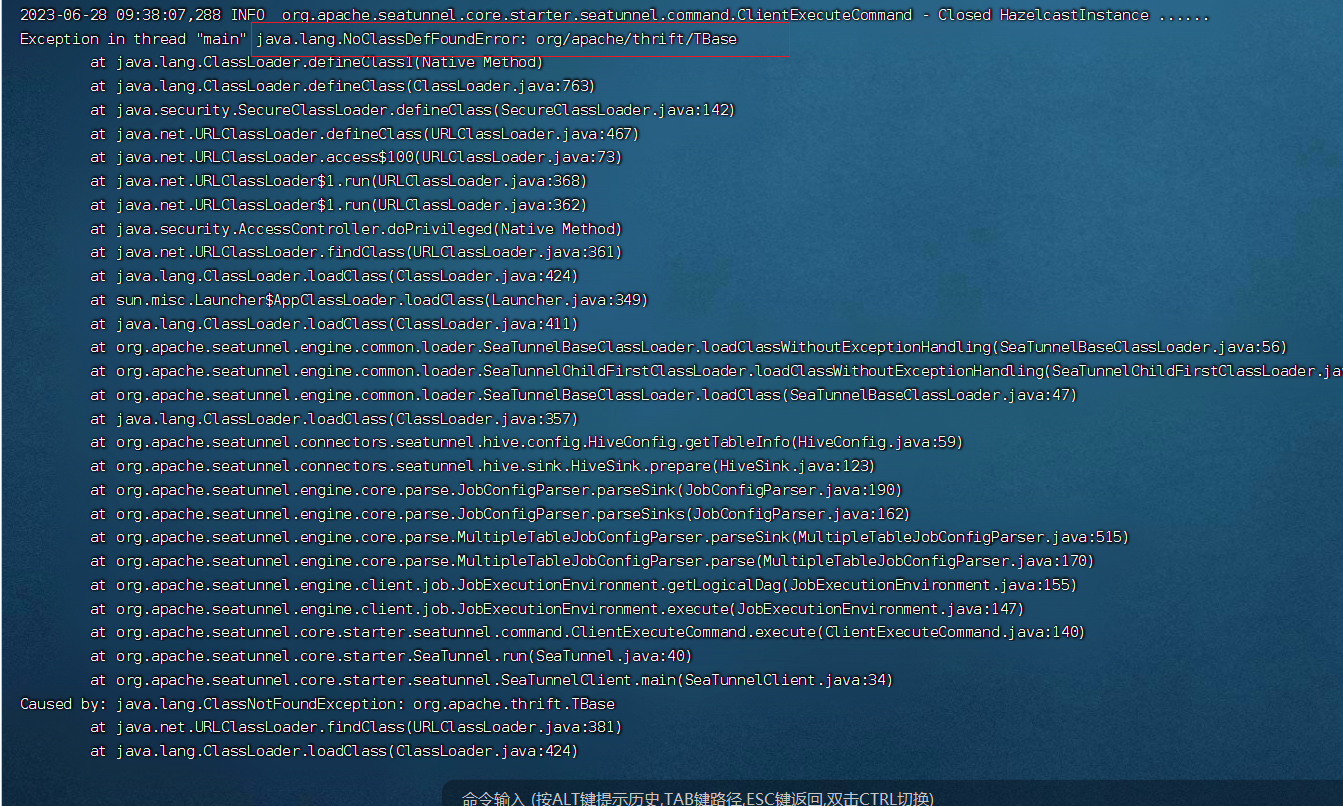
java.lang.NoClassDefFoundError: org/apache/hadoop/hive/metastore/api/MetaException2、java.lang.NoClassDefFoundError: org/apache/thrift/TBase3、java.lang.NoClassDefFoundError:org/apache/hadoop/hive/conf/