- @luanpeng825485697
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
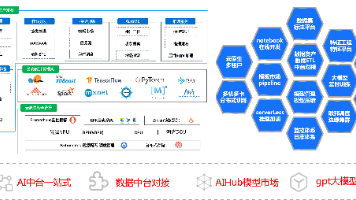
CubeStudio 是一款国产化、云原生的一站式开源人工智能平台,同时覆盖传统机器学习、深度学习与大模型全链路(MLOps / MaaS / 算力调度 / 训推平台),开源协议 MIT,开源免费商用,开源版本已有数千家企业私有化部署。平台提供多租户与算力纳管调度、算力租赁与 Token 中转站、拖拉拽 Pipeline 任务流编排、多机多卡分布式训练、超参搜索、推理服务、vGPU 虚拟化、云边端
全栈工程师开发手册 (作者:栾鹏)python数据挖掘系列教程梯度下降法算法详情参考:https://www.cnblogs.com/pinard/p/5970503.html随机梯度下降(SGD) 是一种简单但又非常高效的方法,主要用于凸损失函数下线性分类器的判别式学习,例如(线性) 支持向量机 和 Logistic 回归 。Stochastic Gradient Descent (
前言:cube是开源的云原生机器学习平台,目前包含特征平台,支持在/离线特征;数据源管理,支持结构数据和媒体标注数据管理;在线开发,在线的vscode/jupyter代码开发;在线镜像调试,支持免dockerfile,增量构建;任务流编排,在线拖拉拽;开放的模板框架,支持tf/pytorch/spark/ray/horovod/kaldi等分布式训练任务;task的单节点debug,分布式任务的批
全栈工程师开发手册 (作者:栾鹏)python数据挖掘系列教程支持向量机svm的相关的知识内容可以参考https://blog.csdn.net/luanpeng825485697/article/details/78823919支持向量机的优势在于:在高维空间中非常高效.即使在数据维度比样本数量大的情况下仍然有效.在决策函数(称为支持向量)中使用训练集的...
全栈工程师开发手册 (作者:栾鹏)python数据挖掘系列教程决策树的相关的知识内容可以参考http://blog.csdn.net/luanpeng825485697/article/details/78795504本文只讲述sklearn中如何使用决策树。其中需要安装numpy 、pandas 、matplotlib、sklearn 、pydotplus库...
全栈工程师开发手册 (作者:栾鹏)python教程全解安装pip install lightgbmgitup网址:https://github.com/Microsoft/LightGBM中文教程http://lightgbm.apachecn.org/cn/latest/index.htmllightGBM简介xgboost的出现,让数据民工们告别了传统的机器学习算法们:RF、GBM
cube是tme开源的云原生机器学习平台,目前包含特征平台,支持在/离线特征;数据源管理,支持结构数据和媒体标注数据管理;在线开发,在线的vscode/jupyter代码开发;在线镜像调试,支持免dockerfile,增量构建;任务流编排,在线拖拉拽;开放的模板框架,支持tf/pytorch/spark/ray/horovod/kaldi等分布式训练任务;task的单节点debug,分布式任务的批

在单机单卡,或者单机多卡无法在有限时间内完成训练的情况下,我们就需要使用多机多卡分布式训练,在多机多卡分布式训练主要存在几个难点:1、分布式多机多卡集群2、pytorch多机多卡分布式训练代码3、多机多卡分布式训练gpu利用率问题分布式训练集群...

开源地址:https://github.com/tencentmusic/cube-studiomlops平台:cube studio一站式机器学习mlops/llmops平台,支持多租户,sso单点登录,支持在线镜像调试,在线ide开发,数据集管理,图文音标注和自动化标注,任务模板自定义,拖拉拽任务流,模型分布式多机多卡训练,超参搜索,模型管理,推理服务弹性伸缩,支持ml/tf/pytorch/

开源地址:https://github.com/tencentmusic/cube-studiocube studio 腾讯开源的国内最热门的一站式机器学习mlops/大模型训练平台,支持多租户,sso单点登录,支持在线镜像调试,在线ide开发,数据集管理,图文音标注和自动化标注,任务模板自定义,拖拉拽任务流,模型分布式多机多卡训练,超参搜索,模型管理,推理服务弹性伸缩,支持ml/tf/pytor