




- @alonewolf_99
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Spring框架通过丰富的扩展点设计提供了强大的灵活性。文章详细介绍了三大类扩展点:1. BeanDefinition注册阶段的扩展点(BeanDefinitionRegistryPostProcessor、BeanFactoryPostProcessor、ImportBeanDefinitionRegistrar);2. Bean创建过程的扩展点(BeanPostProcessor、Aware接

本文详细解析了SpringMVC的核心处理流程。主要内容包括:1)DispatcherServlet初始化及九大组件加载;2)四种Handler类型及其映射机制;3)HandlerAdapter适配器模式实现;4)方法参数解析器和返回值处理器的详细工作流程。重点分析了@RequestMapping方法的执行过程,包括参数绑定、返回值转换等关键环节,并提供了中文乱码解决方案和性能优化建议。最后总结了
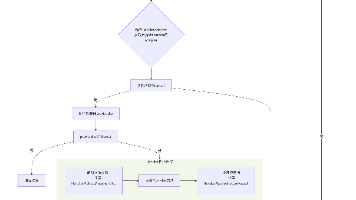
本文深入解析Java类加载机制,通过"程序员涨工资"的趣味案例,揭示类加载器的核心原理与应用场景。主要内容包括:1)类加载三要素(缓存、双亲委派、沙箱保护);2)JDK8三层类加载体系及双亲委派源码解析;3)链接过程的半初始化陷阱;4)五大实战场景:动态JAR加载、类文件加密、热加载实现、双亲委派打破(Tomcat案例)、SPI机制应用;5)模块化对类加载的影响及SpringB

MySQL学习路线与SQL执行机制解析 摘要:本文系统介绍了MySQL学习路径,分为基础、进阶和集群架构三个层次。重点剖析了SQL查询和更新语句的执行流程,包括连接器、分析器、优化器等核心模块。特别讲解了redolog和binlog的协作机制,以及通过两阶段提交保证数据一致性的原理。针对Java开发者,强调了连接池使用、事务控制和数据恢复等实践要点。文章通过"粉板记账"等生动比

本文系统解析了JDK17的JVM调优方法,从参数分类、内存布局到GC算法深度调优。重点介绍了标准/X/XX三类参数的作用及查询方式,详细剖析了堆内存、元空间等关键区域的优化策略。通过RocketMQ案例展示了G1/ZGC收集器的配置技巧,强调日志分析和监控的重要性。文章提出调优五步法,并列出常见误区与最佳实践,指出调优需结合业务特点持续验证,没有通用最优解。最后推荐了学习路径和资源,帮助开发者掌握

在分布式系统中,数据库的高可用性是保障业务连续性的关键。MySQL 8.0的InnoDB Cluster为Java应用提供了开箱即用的高可用数据库解决方案。通过MGR实现数据强一致性,通过MySQL Router实现无感知读写分离,极大地提升了系统的可用性和扩展性。生产环境:使用InnoDB Cluster,至少3节点测试/开发环境:可使用InnoDB ReplicaSet结合Spring Boo

MySQL复制是官方提供的高可用与扩展解决方案,通过将数据从源服务器同步到副本服务器实现数据冗余与分流。核心价值包括高可用性、性能扩展、异地灾备和业务隔离。复制基于二进制日志(Binlog),支持异步(默认)、半同步和GTID三种方式:异步复制性能最佳但存在延迟风险;半同步复制提升数据安全性;GTID复制实现运维自动化。实战部分演示了基于Docker的异步主从复制搭建和GTID故障处理方法。最后介

本文介绍了Redis的四种部署模式及配置方法:1)单机部署适合开发测试;2)主从部署实现读写分离;3)哨兵模式提供自动故障转移;4)集群部署支持数据分片和高可用。详细说明了每种部署的环境准备、安装配置步骤和常用命令,包括GCC安装、防火墙设置、配置文件修改等核心环节。特别针对集群部署给出了三主三从的配置示例和创建命令。最后提供了部署选型建议和安全注意事项,强调根据业务场景选择合适方案,生产环境需设

Redis是一款高性能内存数据库,支持字符串、哈希、列表等丰富数据结构。本文详细介绍了Redis的核心命令及Java实现示例,包括键值操作、事务处理、Lua脚本等高级功能。重点分析了Redis在缓存加速、会话管理、消息队列等典型场景的应用,并提供了使用注意事项和最佳实践建议。通过合理运用Redis的特性,可显著提升Java应用的性能和扩展性,是构建分布式系统的理想选择。

Redis产品体系及核心功能解析 Redis提供多种产品形态,包括Redis Cloud云服务、企业版、开源版和增强版Redis Stack。Redis Stack整合了Redis OSS和扩展模块,提供JSON处理、全文搜索等高级功能。其核心扩展包括: RedisJSON - 原生JSON支持,性能优异 RedisSearch - 全文搜索引擎,替代Elasticsearch BloomFilt
