




- @2401_84185471
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
XML可扩展标记语言eXtensible MarkupLanguage,由W3C组织发布,目前推荐遵守的是W3C组织于2000年发布的XML1.0规范。XML用来传输和存储数据,就是以一个统一的格式,组织有关系的数据,为不同平台下的应用程序服务。
/{ previewUrl: “/picture/icon10_10.png”, title: “宠物” ,number:10},//{ previewUrl: “/picture/icon9_9.png”, title: “生活” ,number:9},依赖@ohos.data.distributedData模块实现,详细参考源码RemoteDataManager.ets。TextInput({

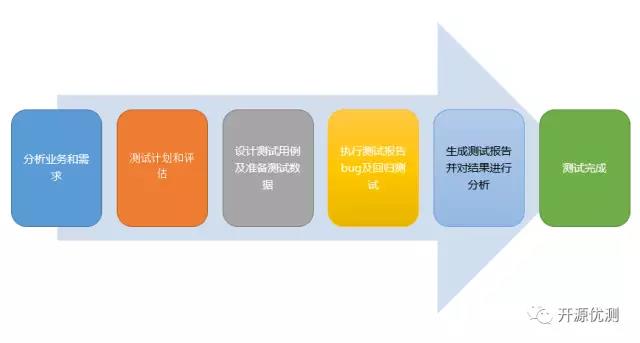
ETL测试是为了确保从源到目的地数据经过业务转换完成后是准确的。同时它还涉及数据的验证,即从源到目的地数据各个不同阶段验证数据。ETL是Extract-Transform-Load的缩写。
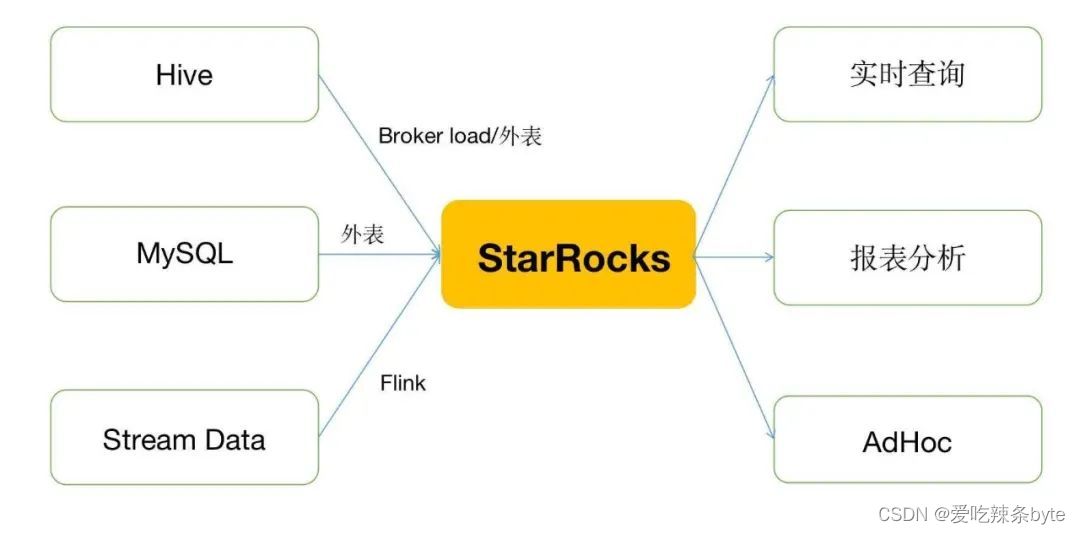
在这种“既要又要还要”的诉求下,选型很困难。OLAP 常用的技术架构有预计算、MPP、索引。单一技术架构的引擎很难满足需求,因此我们把目标瞄向混合架构引擎:同时具有预计算、MPP 计算、支持索引的引擎。目前市面上这类引擎不多,比较成熟的有 Apache Doris 和 StarRocks。最后选择 StarRocks,原因是 StarRocks 的社区更加活跃,产品的背后还有一支大胆创新的强大技术
是 Apache Flink 中用于将数据流转换为 Kafka 记录(record)的序列化模式(Serialization Schema)。它允许将 Flink 数据流中的元素转换为 Kafka 生产者记录,并定义了如何序列化元素的逻辑。在 Flink 中,当你想要将数据发送到 Kafka 主题,需要一个序列化模式来将 Flink 数据流中的元素序列化为 Kafka 记录。而就是为此目的而设计的


注意:序列化内容要在4号位置,这由column的顺序决定。
dataSet = pd.read_csv(‘dataSet.csv’, header=None).values.T# 转置 5*15数组。return -np.sum([p * np.log2§ for p in probability_lst])# 返回信息熵。cnt = Counter(data)# 计数每个值出现的次数Counter({1: 8, 0: 5})cnt = Counter(d
show backends;show backends \G;show data;show data from tpch.supplier;show TEMPORARY PARTITIONS FROM tpch.supplier;show PARTITIONS FROM tpch.supplier;desc supplier;show create table supplier;show rout

• batch.size:批次大小,默认16k• linger.ms:等待时间,修改为5-100ms默认是0ms,就是数据一到队列中就发给broker,这样的好处就是实时性好,但是效率低,一次发几条数据总比一次发一条效率高。也不能改太大,太大时效性不好。• compression.type:压缩snappy压缩数据,这样一批次就可以存更多的数据• RecordAccumulator:缓冲区大小,可
