




- @wjpwjpwjp0831
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
静态建模:类图、对象图、用例图动态建模:序列图(顺序图,时序图)、通信图(协作图)、状态图、活动图物理建模:构件图(组件图)、部署图交互图:序列图(顺序图,时序图)、通信图(协作图)

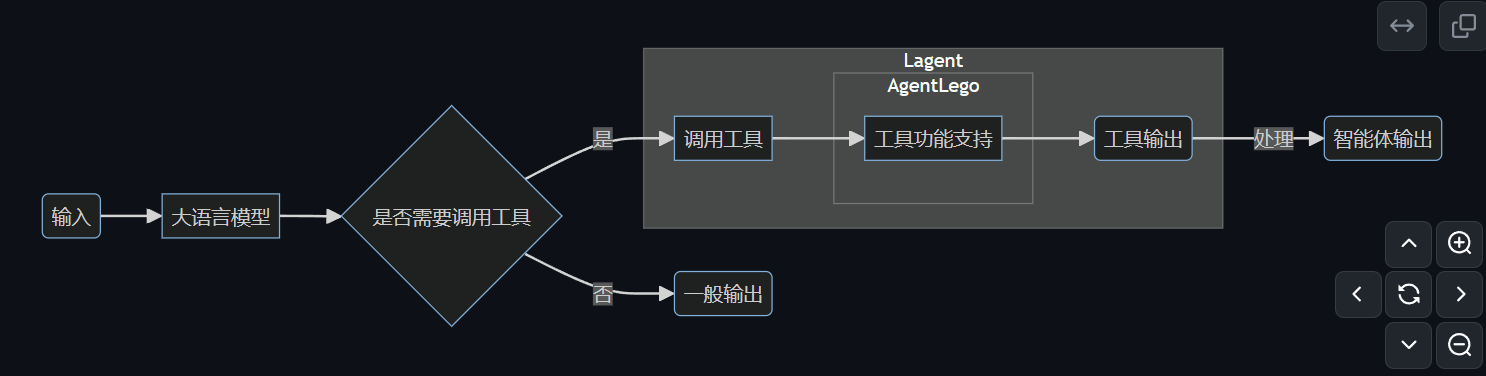
继承 BaseTool 类修改 default_desc 属性(工具功能描述)如有需要,重载 setup 方法(重型模块延迟加载)重载 apply 方法(工具功能实现)下面我们实现一个调用 MagicMaker 的 API 以实现图像生成的工具。class MagicMakerImageGeneration(BaseTool): # 第一步 继承BaseTool类。
本系列笔记是北邮鲁老师三维重建课程笔记,视频可在找到。

本节讲如何从单一视角恢复出3D的场景信息,以及能够恢复3D信息需要哪些条件。

这一阵子的一个小工作:把JDE的骨干网络换成了Swin-T,在VisDrone2019-MOT数据集上训练,的确得到了比DarkNet53作为骨干网络更好的效果:IDF1RecallPrecisionFPFNMOTAMOTPJDE(with DarkNet53 backbone)45.048.791.457776467242.40.235JDE(with Swin-T backbone)48.25
跑通代码最重要的就是路径问题, 为此我写了两个config模板, 让配置路径更简单.

零 前言觉得害得补补RNN的知识,虽然好像有人说transformer把RNN替代了。
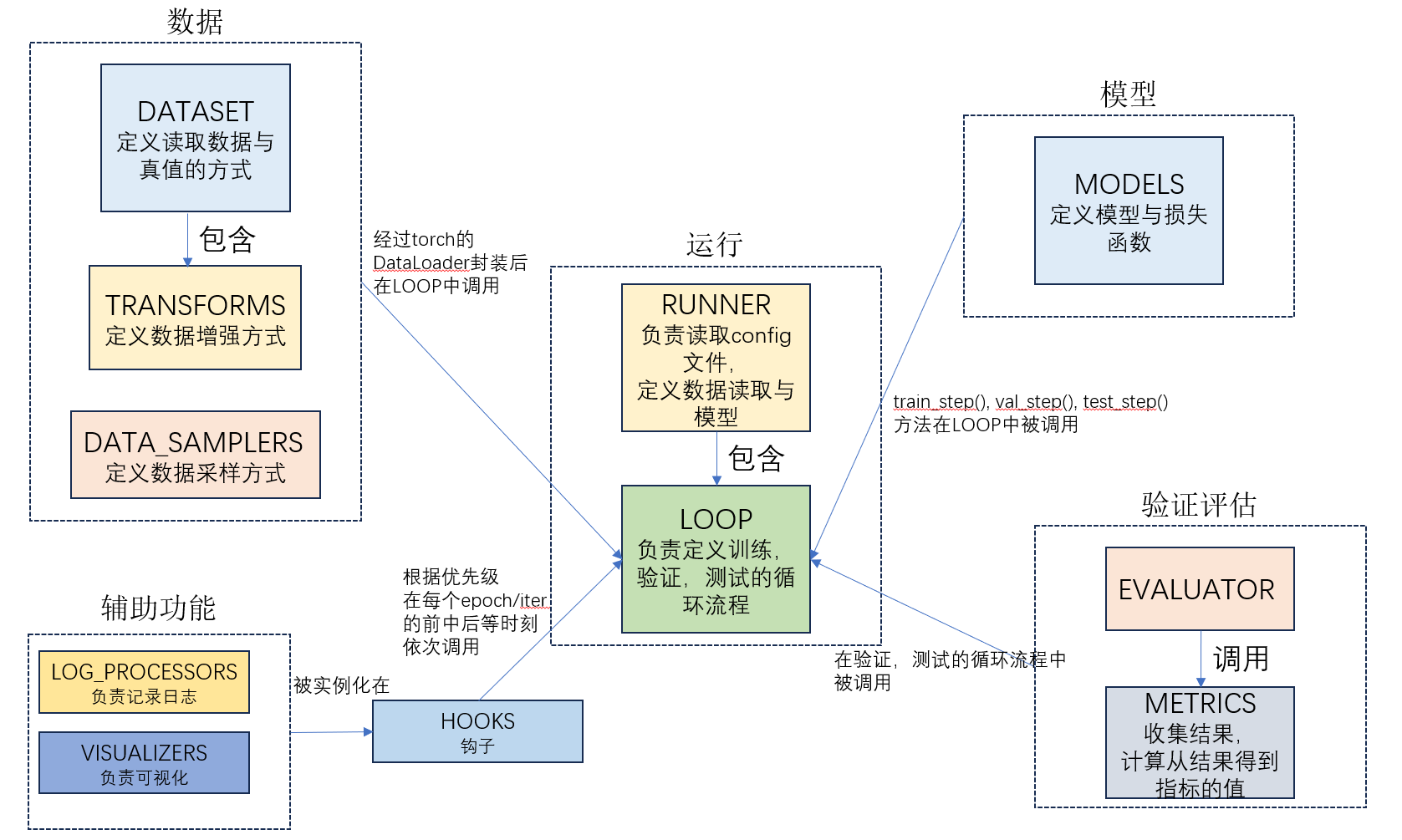
之前跑了一下mmdetection 3.x自带的一些算法, 但是具体的代码细节总是看了就忘, 所以想做一些笔记, 方便初学者参考. 其实比较不能忍的是, 官网的文档还是空的…这次想写其中的数据流是如何运作的, 包括从读取数据集的样本与真值, 到数据增强, 再到模型的forward当中.
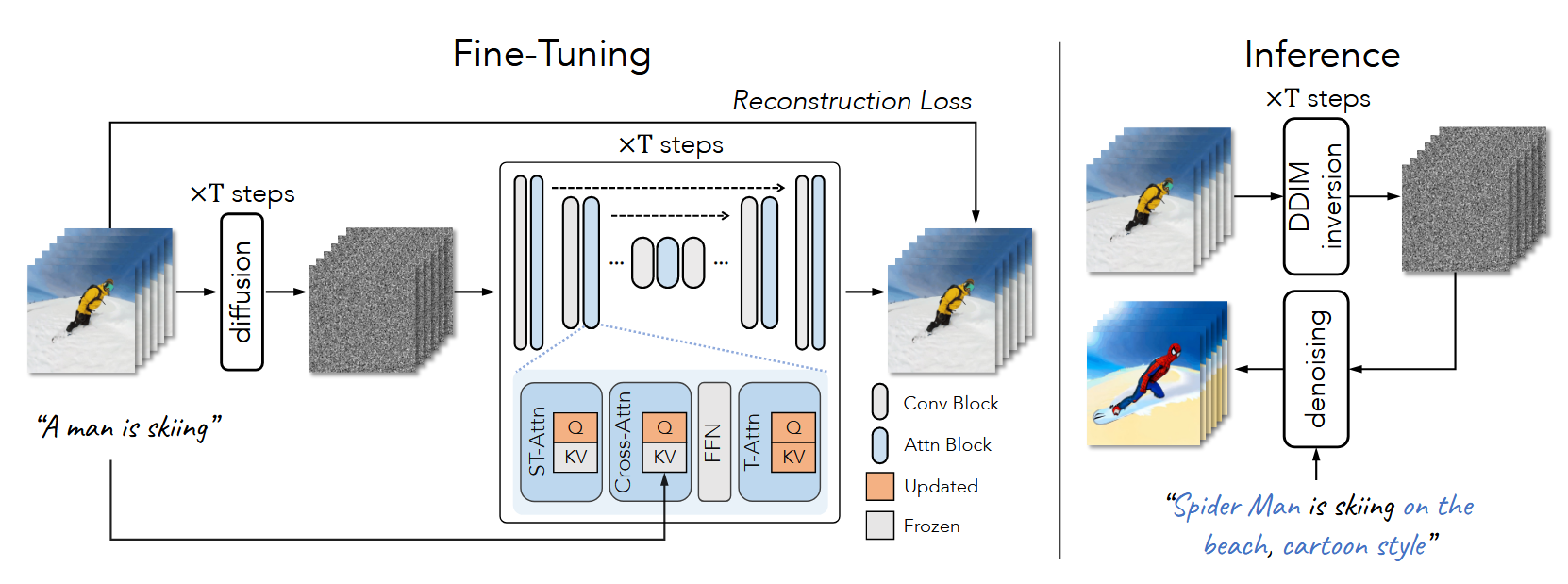
Tune-A-Video通过One-shot的方式, 也就是, 需要对每个你希望编辑的视频, 都需要训练一次. 训练过程只需要待编辑的视频, 不需要其他的, 因为相关的world knowledge是由预训练的Stable Diffusion提供的.既然是视频生成, 那就必须要约束生成帧的时间一致性. 因此就通过重新设计注意力机制的形式让temporal之间也进行注意力计算, 从而维持一致性. 模
Lp空间在泛函分析中比较详细地讲述过(但我没有详细地学过),这里更多作一点重复。1.Lp空间定义设(X,F,μ)(X,\mathscr F,\mu)(X,F,μ)是一测度空间,定义其上绝对值p次幂可积的函数(p≥1p\ge1p≥1)的全体集合为Lp(X,F,μ)L^p(X,\mathscr F,\mu)Lp(X,F,μ)。也即LpL^pLp中的函数满足:∫X∣f∣pdμ<∞\int_X |f