- @weixin_73404807
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
从图中可以直观感受到ResNet的特点:ResNet直接使用stride=2的卷积做下采样,并且用average pool层替换了全连接层。ResNet在网络中引入了残差模块,输入和输出进行跳跃连接,综合形成残差单元。同时,当feature map大小降低一半时,feature map的数量增加一倍,图中虚线就表示feature map数量发生了改变,ResNet通过这种变化保持网络层的复杂度。

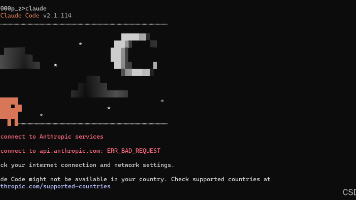
这意味着Git在进行HTTPS连接时不会验证服务器的SSL证书,可能会导致不安全的连接。在特定情况下,如果你无法正确地验证证书,或者遇到错误的SSL证书,你可以使用这个命令来解决问题。这个命令不仅复制远程仓库中的所有文件,还复制仓库的历史记录,使得你可以在本地进行版本控制操作,如提交(commit)、分支(branch)和合并(merge)等。配置git证书信任:有时候,Git无法识别服务器的SS

图像预训练经历了“监督学习(ImageNet 时代)→ 自监督学习(对比学习与掩码建模时代)→ 多模态统一(CLIP 与大模型时代)”用更少标注、更低成本,获得更强的视觉理解、泛化与生成能力。未来,视觉预训练将与语言、音频、动作等多模态深度融合,迈向真正的通用人工智能。
热力图是一种通过颜色变化展示数据强度的可视化工具,常用于呈现矩阵数据、相关性分析等场景。其核心原理是将数值映射为颜色深浅,通过色块直观反映数据分布。Seaborn库的sns.heatmap函数支持多种参数配置,包括颜色映射范围、注释显示、单元格样式等。典型实现包括生成随机矩阵、设置坐标标签、添加遮罩效果等操作,还能结合相关系数矩阵进行高级分析。通过合理设置参数,热力图可有效揭示数据间的关联模式和分

CCSwitch 3.13.0版本现已发布,用户可通过GitHub下载Windows安装包。安装过程简单快捷,只需按照向导点击"Next"即可完成。安装后需配置供应商API Key方可使用。该版本下载地址为:https://github.com/farion1231/cc-switch/releases/download/v3.13.0/CC-Switch-v3.13.0-Wi
CCSwitch 3.13.0版本现已发布,用户可通过GitHub下载Windows安装包。安装过程简单快捷,只需按照向导点击"Next"即可完成。安装后需配置供应商API Key方可使用。该版本下载地址为:https://github.com/farion1231/cc-switch/releases/download/v3.13.0/CC-Switch-v3.13.0-Wi
Seaborn的sns.clustermap函数用于创建聚类热图,通过颜色和位置直观展示数据相似性。主要参数包括数据输入、行列聚类控制、距离度量方法、标准化处理及颜色映射。函数返回ClusterGrid对象,支持进一步自定义。参考实现展示了不同应用场景:基础聚类、大小布局调整、彩色标签添加、颜色映射修改、聚类参数变更、数据标准化和规范化处理。该工具适用于探索性数据分析,但需注意大数据集可能增加计算

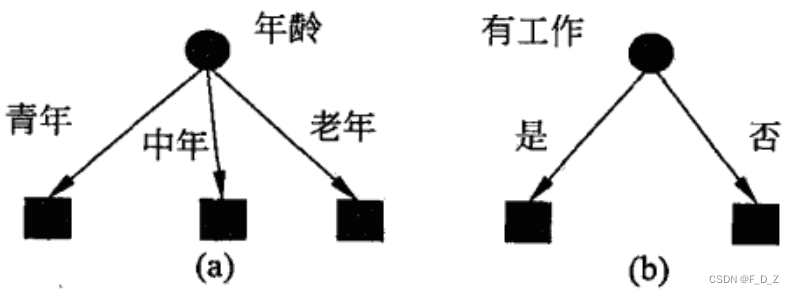
决策树是一类预测模型,它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
热力图是一种通过颜色变化展示数据强度的可视化工具,常用于呈现矩阵数据、相关性分析等场景。其核心原理是将数值映射为颜色深浅,通过色块直观反映数据分布。Seaborn库的sns.heatmap函数支持多种参数配置,包括颜色映射范围、注释显示、单元格样式等。典型实现包括生成随机矩阵、设置坐标标签、添加遮罩效果等操作,还能结合相关系数矩阵进行高级分析。通过合理设置参数,热力图可有效揭示数据间的关联模式和分
本文介绍通过命令行修改Claude配置文件的方法:1)使用Win+R打开运行窗口,输入cmd启动命令提示符;2)通过PowerShell命令修改用户目录下的.claude.json文件,添加或更新hasCompletedOnboarding属性为true;3)最后重启Claude应用使更改生效。这个操作可以跳过Claude的初始引导流程,适合需要快速使用的场景。全文提供了完整的命令行操作步骤,通过