




- @weixin_62697030
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
常见的神经网络是一种监督学习,监督学习的主要特征即为根据输入来对输出进行,最终会得到一个输出数值.而非监督学习的目的不在于输出,而是在于对读入的数据进行归类,选取特征,打标签,通过对于数据结构的分析来完成这些操作, 很少有最后的输出操作.从训练数据的角度来说也是有所区别:监督学习的训练数据为(x,y), 即同时具有输入和输出数值,根据这种输入和输出来判断训练的结果是否正确.

DFS深度寻找所有的可能性,然后比较出一个结果BFS根据蚕食策略,找到所有的点,然后得到一个结果DFS可以更直观地得到路径,而BFS似乎更倾向于得到每个点的最短距离嘛。。不过该能做到的都能做到,只不过实现方法不同罢了。
当我们找到一个算法去计算某些东西的时候,我们通常要对这个算法进行一定的分析,比如时间复杂度,空间复杂度(前者更加重要),来进行比较,判断一个算法的优劣性.对于一个训练的模型来说,同样需要某种模型来进行分析,例如代价函数等等,通过比较拟合程度,正确精度等信息来判断出这个模型的好坏,从而选择更好的模型。
一点简单的小小总结:1.首先是关于net:net可以接受小批量,甚至是一个完整那个的数据list的输入的,也就是说我们传入的小批量其实是[256,1,28,28]然后我们最终的输出结果为[256,1],虽然这不是我们要的东西其实net本质就是一个张量处理机,’压缩‘成需要的格式张量处理机:一开是的猜测是会根据批量逐一处理那些张量,但是事实是net本身并不会对其进行太多的区分传入进来的仍然是一个整体

当我们找到一个算法去计算某些东西的时候,我们通常要对这个算法进行一定的分析,比如时间复杂度,空间复杂度(前者更加重要),来进行比较,判断一个算法的优劣性.对于一个训练的模型来说,同样需要某种模型来进行分析,例如代价函数等等,通过比较拟合程度,正确精度等信息来判断出这个模型的好坏,从而选择更好的模型。
其中两个一维函数可以使用递归计算(fy即为斐波那契数列的计算方式,这两个函数可以使用dp的方式完成优化,这里因为数据量较小不再实现) , 计算二维函数需要使用管道通信,将前两个进程的数据通过管道发送到另一个管道中,实现进程的通信.其实这就是fork函数的本质:当某个进程根据fork函数创建子进程的时候,会给根据这个函数创建的两个进程分别配一个返回值,父进程得到的返回值是大于0的,而子进程得到的返回

由于一些突发事件,导致目前大家手里或多或少都有了完整版的答案了。甚至很多学长学姐们写的代码远比我写的要好很多。但是这个系列我觉得还是稍微坚持下去一点,或许某些地方可以帮到未来的同学们。还是那句话,有需要可以随时向我反馈你遇到的问题,你的指点就是我最大的动力。
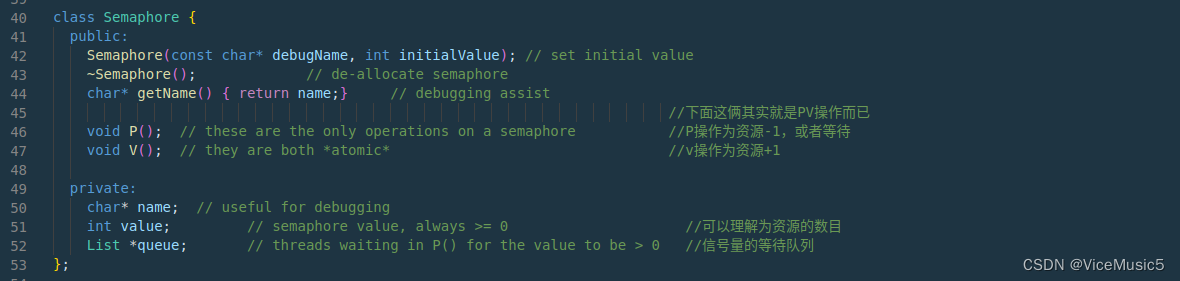
其实昨天就把这篇写完了,可是遇到了一些突发事件,暂时还没想好自己的出路在哪,争取这两天把课程设计的实验全都写完吧。。。。。我知道大家现在都很难过,生活上,学业上,事业上。。。。但是还是希望大家能一起加油度过这段日子。

归零编码和两种曼彻斯特都是子同步,通过归零和跳变,把时钟这一信号存入了比特流的内部.

注明:这些实验在完成整体实验的过程中,会先放到csdn做暂时存储(因为这台破机子没法装md的笔记软件),偏向于讲解实验如何完成,以及对于代码的一些解释,相当与在这里做一些笔记和记录。因为我之前在检索关于实验的教程的时候,会发现其实很多学长学姐留下的资料基本都是偏报告的,不过嘛熟悉我的兄弟们肯定都知道,我更习惯把自己的过程给手把手的教出来,当然这不是鼓励大家去照抄de。。。。能在某个特殊环节让大家找
