- @weixin_60200880
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
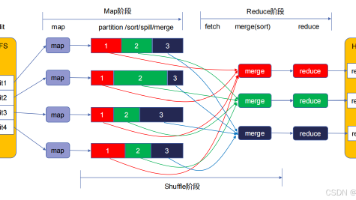
摘要:MapReduce是一种用于大规模数据并行处理的编程模型,它将计算任务分为Map和Reduce两个阶段,通过移动计算而非数据实现并行处理。MapReduce适用于离线批处理场景。其工作原理包括数据切分、Map任务处理、Shuffle阶段和Reduce任务汇总。典型应用如WordCount词频统计,通过哈希取模确保相同Key分发到同一Reduce节点。但MapReduce因大量磁盘I/O和网络
当地时间,24小时制,格式为hh:mm。结构号或序列号/线号或机身号。事故发生日期(年-月-日)事故前飞行的全部或部分航线。由飞机操作员指定的航班号。国际民航组织对飞机的登记。航空公司或飞机的运营商。出课程论文-多元统计分析论文、R语言论文、stata计量经济学课程论文(论文+源代码+数据集)
1)本次比赛的代码过于冗杂,很多地方都可以进行优化2)论文整体质量比上一次参加稍有进步最后插个小广告hhh(适合数据分析初学者&入门者)(出售本次比赛的论文、源程序、支撑材料,仅供学习使用,仅供学习使用,仅供学习使用。
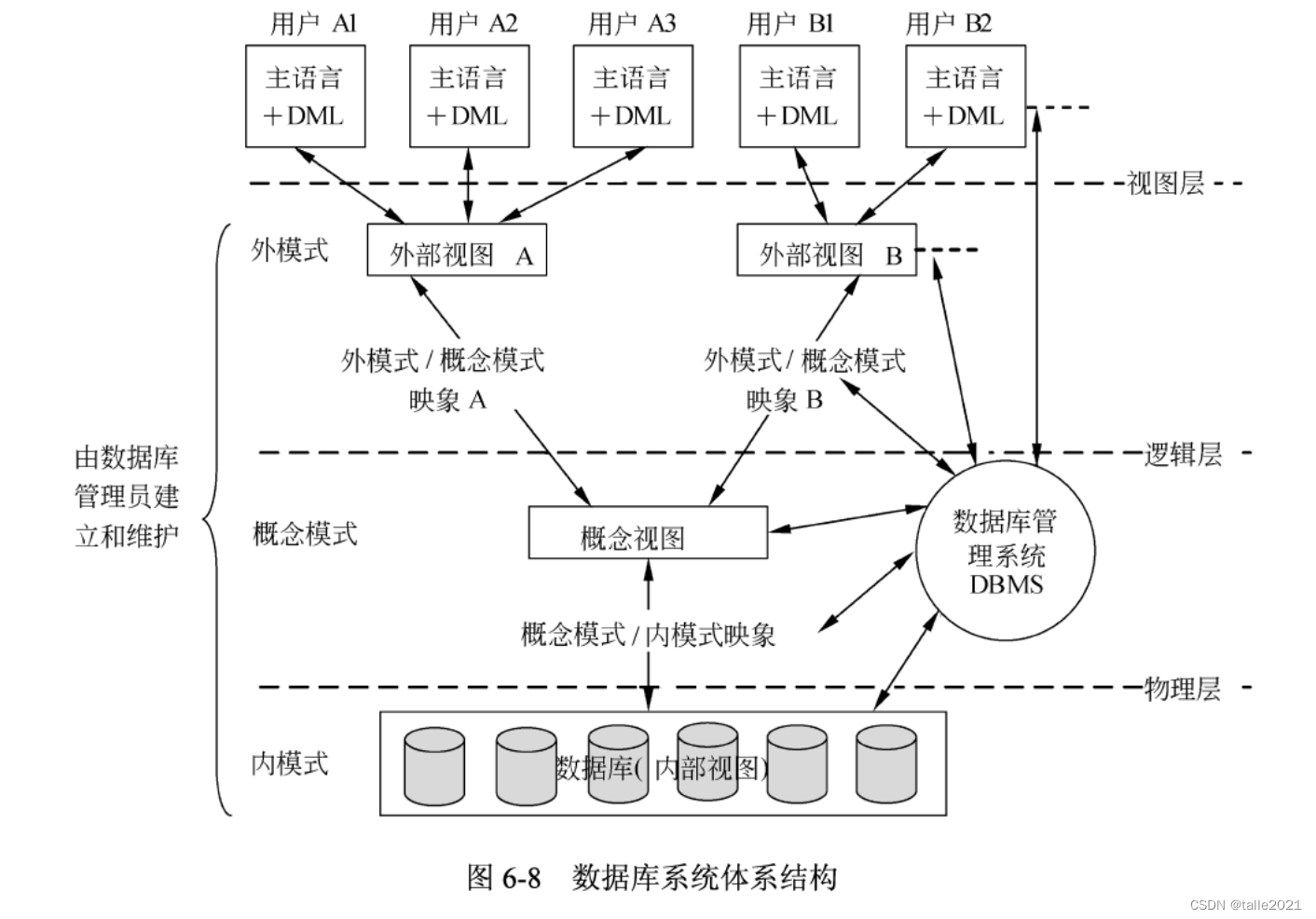
3)广义笛卡尔积:两个元数分别为m和n的关系R和S的广义笛卡尔积是一个(m+n)列的元组的集合。PS:三方联系和聚合的区别:三方联系必须要三方实体同时参与,而聚合是有先后顺序的,两个实体先产生联系,再与第三个实体产生联系。也称存储模式,是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。Y,那么对于任意两个相同的X,所对应的Y一定是相同的。是数据库中全部数据的逻辑结构和特征的描述,只设计
2022第五届泰迪杯数据分析技能赛B题-银行客户忠诚度分析 数据分析比赛
目录任务1 数据探索与清洗任务1.1 数据探索与预处理任务1.2 特征编码任务2 产品营销数据可视化分析任务2.1 任务2.2任务2.3任务2.4 任务3 客户流失因素可视化分析任务3.1任务3.2任务3.3任务3.4分别对短期客户产品购买数据“short-customer-data.csv”(简称短期数据)和长期客户资源信息数据的训练集“long-customer-train.csv”(简称长期
YARN是一个分布式资源管理系统,采用主从架构(ResourceManager和NodeManager),支持多种计算框架(如MapReduce、Spark)。其高可用性通过ZooKeeper实现主备切换和元数据同步。YARN提供三种资源调度策略:FIFO(先进先出)、Capacity(预设队列资源比例)和Fair(动态公平分配)。Capacity调度器允许队列弹性使用空闲资源,而Fair调度器默

决定枚举网格搜索运算速度的因子一共有两个:①参数空间的大小(参数空间越大,需要建模的次数越多);②数据量的大小(数据量越大,每次建模时需要的算力和时间越多)。sklearn中的网格搜索优化方法主要包括两类,其一是调整搜索空间,其二是调整每次训练的数据。对网格搜索而言,如果参数空间中的某一个点指向了损失函数真正的最小值,那枚举网格搜索时一定能够捕捉到该最小值以及对应的参数(相对的,假如参数空间中没有
数据预处理之缺失值处理(sklearn、pandas)

(1)使用更多的数据:导致过拟合的根本原因是训练集和测试集的特征存在较大差异,导致原本完美拟合的模型无法对新数据集产生良好的效果;过拟合通俗点讲就是在做分类训练时面模型由于过度学习了训练集的特征,使得训练集的准确率非常高,测试集的准确率却很差。:混淆矩阵是作分类算法效果评估的基本方法,它是监督式学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息。(2)降维:通过维度选择或转换的方式,降低